# inpath: # verifies that a specified program is either valid as is # or can be found in the PATH directory list
in_path() { # Given a command and the PATH, tries to find the command. # Returns 0 if found the executable. 1 if not. # Note that this temporarily modifies the IFS (internal field separator) # but restores it upon completion
cmd=$1 ourpath=$2 result=1
oldIFS=IFS IFS=":"
for directory in$ourpath do if [ -x $directory/$cmd ]; then result=0 # if we're here, we found the command fi done
IFS=$oldIFS return$result }
check_cmd_in_path() { var=$1
if [ "$var" != "" ]; then if [ "${var:0:1}" = "/" ]; then if [ ! -x $var ]; then return 1 fi elif ! in_path $var"$PATH" ; then return 2 fi fi }
test() { if [ $# -ne 3 ]; then echo"Usage: $0 month day year" >&2 echo"Formats are Auguest 3 1962 and 8 3 1962" >&2 exit 1 fi
if [ $3 -le 999 ]; then echo"$0: expected 4-digit year value." >&2 exit 1 fi
# Is the month input format a number if [ -z $(echo$1 | sed 's/[[:digit:]]//g') ]; then month_num_to_name $1 else month="$(echo $1 | cut -c1 | tr '[:lower:]' '[:upper:]')" month="$month$(echo $1 | cut -c2-3 | tr '[:upper:]' '[:lower:]')" fi
echo$month$2$3 exit 0 }
if [ "$BASH_SOURCE" = "$0" ]; then test$@ fi
exit 0
原理
这个脚本只能进行简单的格式化,其接受 Month Day Year 形式的输入,可以将数字形式或字符串形式的月份统一转换为三个字符的简写形式,另外年份只能是 4 位数字格式。
通过 [ -z $(echo $1 | sed 's/[[:digit:]]//g') ] 判断输入的月份是否只包含数字。
# nice_number.sh # Given a number, show it in comma-separated form. Expects DD # (decimal point delimiter) and TD(thousands delimiter) to be # instantiated. Instantiates nicenum or, if a second arg is specified, # the output is echoed to stdout.
nice_number() { # Note that we assume that . is the decimal separator in the INPUT value, # the decimal separator in the output value is "." unless specified by # the user with the -d flag.
separator=$(echo$1 | sed 's/[[:digit]]//g') if [ ! -z "$separator" -a "$separator" != "$DD" ]; then echo"$0: Unknown decimal separator $separator encountered." >&2 exit 1 fi
# valid_integer.sh # Validates integer input, allowing negative integers too
valid_int() { # Validate first field and test the value against min value $2 and/or # max value $3 if they are supplied. If the value isn't within range # or it's not composed of just digits, fail.
number="$1" min="$2" max="$3"
if [ -z "$number" ]; then echo"You didn't enter anything. Please enter a number." >&2 return 1 fi
# is the first character a '-' sign if [ "${number%${number#?}}" = '-' ]; then test_value="${number#?}" else test_value="${number}" fi
no_digits=$(echo$test_value | sed 's/[[:digit:]]//g')
if [ ! -z "$no_digits" ]; then echo"Invalid number format! only digits, no commas, spaces, etc." >&2 return 1 fi
if [ ! -z "$min" ]; then # Is the input less than the minimum value if [ "$number" -lt "$min" ]; then echo"Your value is too small: smallest acceptable value is $min." >&2 return 1 fi fi
if [ ! -z "$max" ]; then # Is the input greater than the max value if [ "$number" -gt "$max" ]; then echo"Your value is too big: largest value is $max." >&2 return 1 fi fi
return 0 }
test() { if valid_int $@ ; then echo"Input is valid integer within your contraints". fi
return 0 }
if [ "$BASH_SOURCE" = "$0" ]; then test$@ fi
原理
该脚本的核心是 valid_int() 函数,其首先检查输入的 number 字符串是否为空。然后判断第一个字符是否为 -,如果是 -,则获取 - 之后的所有字符。然后检查剩余字符是否都为数字,如果不是则代表输入不是合法的整数。之后如果用户传递了 min 或 max,再检查该整数是否在其范围内
其使用到的 bash 脚本编程知识已经在前面的脚本中介绍过了,这里在简单总结一下:
使用 if [ -z “$number” ] 判断 number 变量是否是空字符串
使用 {number%{number#?}} 获取 number 字符串变量中的第一个字符
使用 ${number#?} 获取去除第一个字符后的剩余所有字符
运行
以下展示了该脚本的运行结果的运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ ./valid_integer.sh 10 0 100 Input is valid integer within your contraints.
$ ./valid_integer.sh 10 50 100 Your value is too small: smallest acceptable value is 50.
$ ./valid_integer.sh 10 0 9 Your value is too big: largest value is 9.
$ ./valid_integer.sh -1 -10 10 Input is valid integer within your contraints.
$ ./valid_integer.sh -1 -20 -10 Your value is too big: largest value is -10.
$ ./valid_integer.sh -30 -20 -10 Your value is too small: smallest acceptable value is -20.
Hacking
注意这个脚本不能使用逻辑 -a 来简化嵌套的 if 表达式,因为 bash 的 -a 不具有短路求值特性。这样可能会执行没有意义的比较。
# Copyright (C) fuchencong.com # valid_float.sh # Tests whether a number is a valid float-pointing value. # Note this script can't accept scientific notation.
# To test whether an entered value is valid floating-point number. # We need to split the value into two parts: the integer portion # and the fractional portion. We test the first part to see whether # it's a valid integer, and then we test whether the second part is a # valid >0 integer. So -30.5 evaluates as valid, but -30.-8 doesn't.
# To include another shell script as a part of this one, use the . source # notation. Easy enough
. valid_integer.sh
valid_float() { fvalue="$1"
# check whether the input number has a decimal point if [ ! -z $(echo$fvalue | sed 's/[^.]//g') ]; then # Extract the part before the demical point demical_part="$(echo $fvalue | cut -d. -f1)"
# Extract the part after the demical point fractional_part=${fvalue#*\.}
# Start by testing the demical part, which is everything to the left # of the demical point. if [ ! -z $demical_part ]; then if ! valid_int "$demical_part"; then return 1 fi fi
# To start, you can't have a negative sign after the demcial point. if [ "${fractional_part%${fractional_part#?}}" = "-" ]; then echo"Invalid floating-point number: '-' not allowed after demical point." >&2 return 1 fi
if [ "$fractional_part" != "" ]; then if ! valid_int "$fractional_part""0"""; then return 1 fi fi else # if the entire value is just "-", that's not good either. if [ "$fvalue" = "-" ]; then echo"Invalid floating-point format." >&2 return 1 fi
# finally, check the remaining digits are actually # valid as integers. if ! valid_int "$fvalue"""""; then return 1 fi fi
return 0 }
test() { if valid_float $@ ; then echo"Input is valid float." fi
# valid_date.sh # Validates a date, taking into account leap year rules.
normal_date="./normalize_date.sh"
exceed_days_in_month() { # Give a month name and day number in that month, this function will return 0 # if the specified day value is less than or equal to the max days in month, # 1 otherwise
if ! exceed_days_in_month "$month""$2"; then if [ "$month" = "Feb" -a "$2" -eq 29 ]; then if ! is_leap_year "$year"; then echo"$0: $3 is not a leap year, so Feb doesn't have 29 days." >&2 exit 1 fi else echo"$0: bad day value: $month doesn't have $2 days." >&2 exit 1 fi fi
$ sh valid_date.sh 2 30 2000 valid_date.sh: bad day value: Feb doesn't have 30 days. $ sh valid_date.sh 2 29 1996 Valid date: Feb 29 1996 $ sh valid_date.sh 2 29 2000 Valid date: Feb 29 2000 $ sh valid_date.sh 2 29 2001 valid_date.sh: 2001 is not a leap year, so Feb doesn't have 29 days.
$ sh valid_date.sh 2 28 2001 Valid date: Feb 28 2001
$ sh valid_date.sh 5 32 2001 valid_date.sh: bad day value: May doesn't have 32 days. $ sh valid_date.sh 6 31 2001 valid_date.sh: bad day value: Jun doesn't have 31 days.
$ sh valid_date.sh 6 30 2001 Valid date: Jun 30 2001
Hacking
这里介绍一种非常特别的方式来判断某一年是否是闰年:
1 2 3 4 5 6 7 8 9 10
is_leap() { year="$1"
if [ $(date -d "12/31/$year" +%j) = "366" ]; then return 0 else return 1 fi }
这里用到了 date 命令,-d 选项用来指定日期,而 +%j 用于输出指定日期在这一年中的天数,这样,如果一年的最后一天是 366,则代表是闰年,否则不是闰年。
whilegetopts"lur:" opt; do case$optin l ) action="lock" ;; u ) action="unlock" ;; r ) retries="$OPTARG" ;; esac done shift $(($OPTIND - 1))
if [ $# -eq 0 ]; then cat << EOF Usage: $0 [-l|-u] [-r retries] LOCKFILE Where -l request a lock(the default), -u request an unlock, -r X specifies a max number of retries before it fails (default= $retries). EOF exit 1 fi
if [ -z "$(which lockfile | grep -v '^no ')" ]; then echo"$0 failed: 'lockfile' utility not found in PATH." >&2 exit 1 fi
if [ "$action" = "lock" ]; then if ! lockfile -r "$retries""$1" 2> /dev/null; then echo"$0: Failed: Couldn't create lockfile in $retries times." >&2 exit 1 fi else if [ ! -f "$1" ]; then echo"$0: Warning: lockfile $1 doesn't exit to unlock." >&2 fi rm -f "$1" fi exit 0
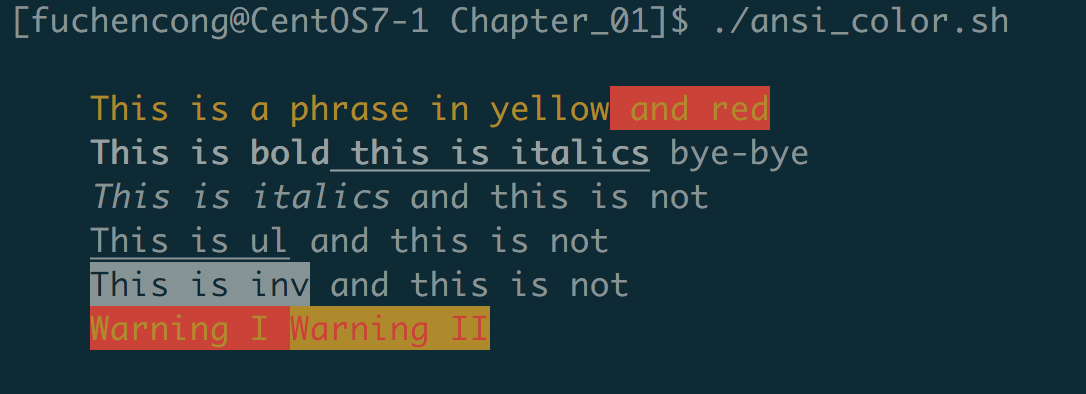
# ansi_color.sh # Use these variables to make output in different colors and formats. # Color names that end with f are foreground colors, and those ending # with 'b' are background colors.
str=" ${yellowf}This is a phrase in yellow${redb} and red${reset} ${boldon}This is bold${ulon} this is italics${reset} bye-bye ${italicson}This is italics${italicsoff} and this is not ${ulon}This is ul${uloff} and this is not ${invon}This is inv${invoff} and this is not ${yellowf}${redb}Warning I ${yellowb}${redf}Warning II${reset} " echo -e "$str" }
in_path() { # Given a command and the PATH, tries to find the command. # Returns 0 if found the executable. 1 if not. # Note that this temporarily modifies the IFS (internal field separator) # but restores it upon completion
cmd=$1 ourpath=$2 result=1
oldIFS=IFS IFS=":"
for directory in$ourpath do if [ -x $directory/$cmd ]; then result=0 # if we're here, we found the command fi done
IFS=$oldIFS return$result }
check_cmd_in_path() { var=$1
if [ "$var" != "" ]; then if [ "${var:0:1}" = "/" ]; then if [ ! -x $var ]; then return 1 fi elif ! in_path $var"$PATH" ; then return 2 fi fi }
valid_int() { # Validate first field and test the value against min value $2 and/or # max value $3 if they are supplied. If the value isn't within range # or it's not composed of just digits, fail.
number="$1" min="$2" max="$3"
if [ -z "$number" ]; then echo"You didn't enter anything. Please enter a number." >&2 return 1 fi
# is the first character a '-' sign if [ "${number%${number#?}}" = '-' ]; then test_value="${number#?}" else test_value="${number}" fi
no_digits=$(echo$test_value | sed 's/[[:digit:]]//g')
if [ ! -z "$no_digits" ]; then echo"Invalid number format! only digits, no commas, spaces, etc." >&2 return 1 fi
if [ ! -z "$min" ]; then # Is the input less than the minimum value if [ "$number" -lt "$min" ]; then echo"Your value is too small: smallest acceptable value is $min." >&2 return 1 fi fi
if [ ! -z "$max" ]; then # Is the input greater than the max value if [ "$number" -gt "$max" ]; then echo"Your value is too big: largest value is $max." >&2 return 1 fi fi
return 0 }
is_leap_year() { year="$1"
if [ "$((year % 4 ))" -ne 0 ]; then return 1 elif [ "$((year % 400))" -eq 0 ]; then return 0 elif [ "$((year % 100))" -eq 0 ]; then return 1 else return 0 fi }
# set up all those ANSI escape sequences. initialize_ansi
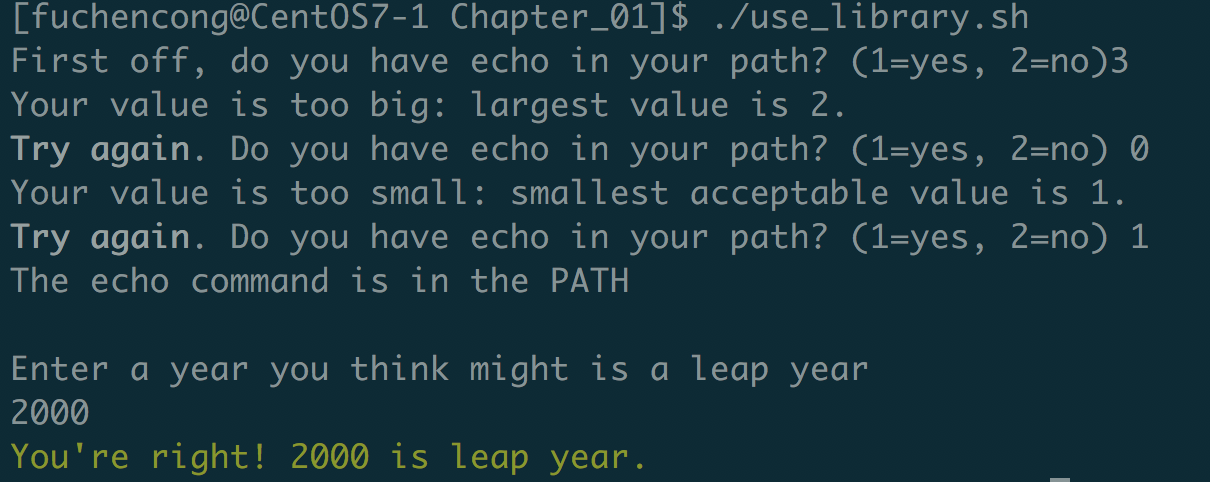
echon "First off, do you have echo in your path? (1=yes, 2=no)" read answer
while ! valid_int $answer 1 2; do echon -e "${boldon}Try again${boldoff}. Do you have echo " echon -e "in your path? (1=yes, 2=no) " read answer done
# check echo if in PATH if ! check_cmd_in_path "echo"; then echo"Nope, can't find the echo command" else echo"The echo command is in the PATH" fi
echo"" echo"Enter a year you think might is a leap year" read year
while ! valid_int $year 1 9999; do echon -e "Please enter a year in the ${boldon}correct${boldoff} format:" read year done
if is_leap_year $year; then echo -e "${greenf}You're right! $year is leap year.${reset}" else echo -e "${redf}Nope! $year is not a leap year.${reset}" fi
$ sh guess_number.sh Guess a number between 1 and 100 guess_number.sh: line 26: unexpected EOF while looking for matching `"' guess_number.sh: line 30: syntax error: unexpected end of file $ grep '"' guess_number.sh | egrep -v '.*".*".*' echo "...bigger