本篇文章是对林沛满老师的两部书籍《Wireshark 网络分析就这么简单》和《Wireshark 网络分析的艺术》的读书笔记。这两本书详实地记录了作者使用 Wireshark 来分析各类网络疑难杂症的经历。通过这些案例,作者介绍了许多使用 Wireshark 的小技巧,同时也向我们传授了其网络排障的一些宝贵经验。阅读这两本书时,让我回想起当时面试百度时面试官的一个问题:”客户端访问服务器慢,怎么排查?”。如果之前我阅读过这两本书,我想我可以回答地更详尽一些。
Wireshark 是解决网络问题的瑞士军刀,通过 Wireshark,我们可以清楚地看见网络中的每一个数据包(此刻请自行脑补你站在世界地图面前,清楚看见当前 Internet 上每一个数据包的流动)。
Wireshark 简介
Wireshark 是目前非常流行的、跨平台的网络嗅探器(sniffer),其提供了非常友好的图形界面。同时如果你是命令行 Geeker,也可以使用它的命令行形式 TShark。Wireshark 有两大作用:
- 协助网络工程师定位网络问题
- 帮助网络工程师更深刻地理解网络协议
Wireshark 使用
纸上得来终觉浅,觉知此事要躬行。对于工具类软件的学习,最好的办法就是 get hands dirty。以下关于 Wireshark 的使用介绍是基于我 Mac 上的 Wireshark 3.4.3,不同平台、不同版本的 Wireshark 在使用细节上可能略有不同。
抓包
在抓取网络包时,我们应该尽量只抓取必要的部分。有很多方法可以实现这一点:
-
只抓包头:一般一个帧的最大长度为 1514 字节,在启用了 jumbo Frame 之后,帧的大小可达 9000 字节以上。而大多数时候只需要抓取 IP 头或 TCP 头即可。可以在
Capture->Options->Input->Snaplen(B)中进行设置,例如设置成 80 字节,这样一般就可以包含数据链路层、网络层、传输层的信息了。如果还需要包含应用层,那就需要设置的更大一点。使用tcpdump时,其-s选项也可以设置抓包大小 -
只抓必要的包:Wireshark 的 Capture Filter 可以在抓包时过滤掉不需要的包,可以在
Capture->Options->Input->Capture filter中设置。
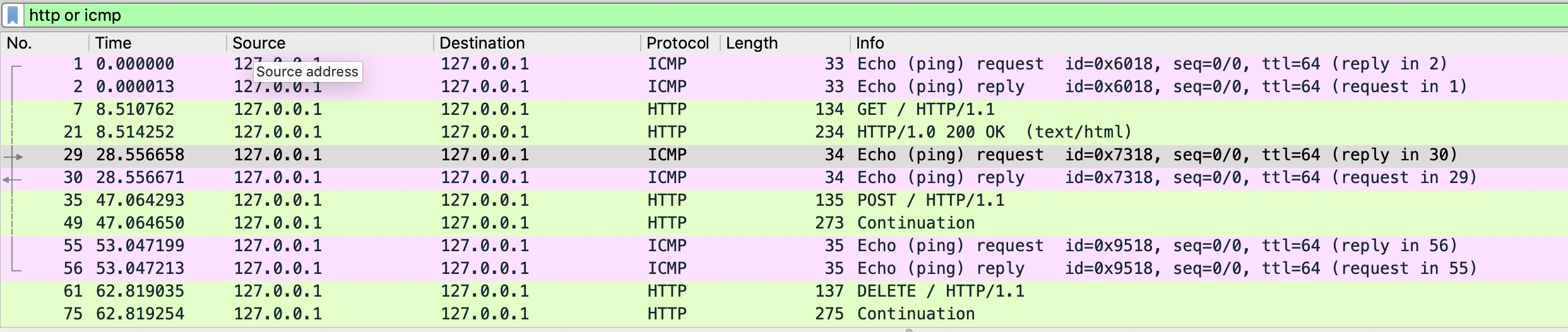
例如在我的无线网卡中设置只抓取 53 端口(DNS)的报文,然后执行 nslookup www.baidu.com 就可以看到抓取的 DNS query 和 DNS response 报文:


- 抓包时每一步打上标记,这样抓包结果一目了然。例如一个操作涉及三个步骤,可以在每一步之前通过
ping <IP> -n 1 -l $size的方式发送标记报文,其中 size 就是当前步骤编号。这样我们就可以在一系列报文中区分出每一步所涉及的报文了。
另外,如果你在抓包时提示你没有抓包权限,只需要按照 Wireshark 的提示安装 ChmodBPF 软件包即可。

个性化设置
- 不同类型的网络包可以自定义颜色,这样就可以一目了然的得到报文分类。通过
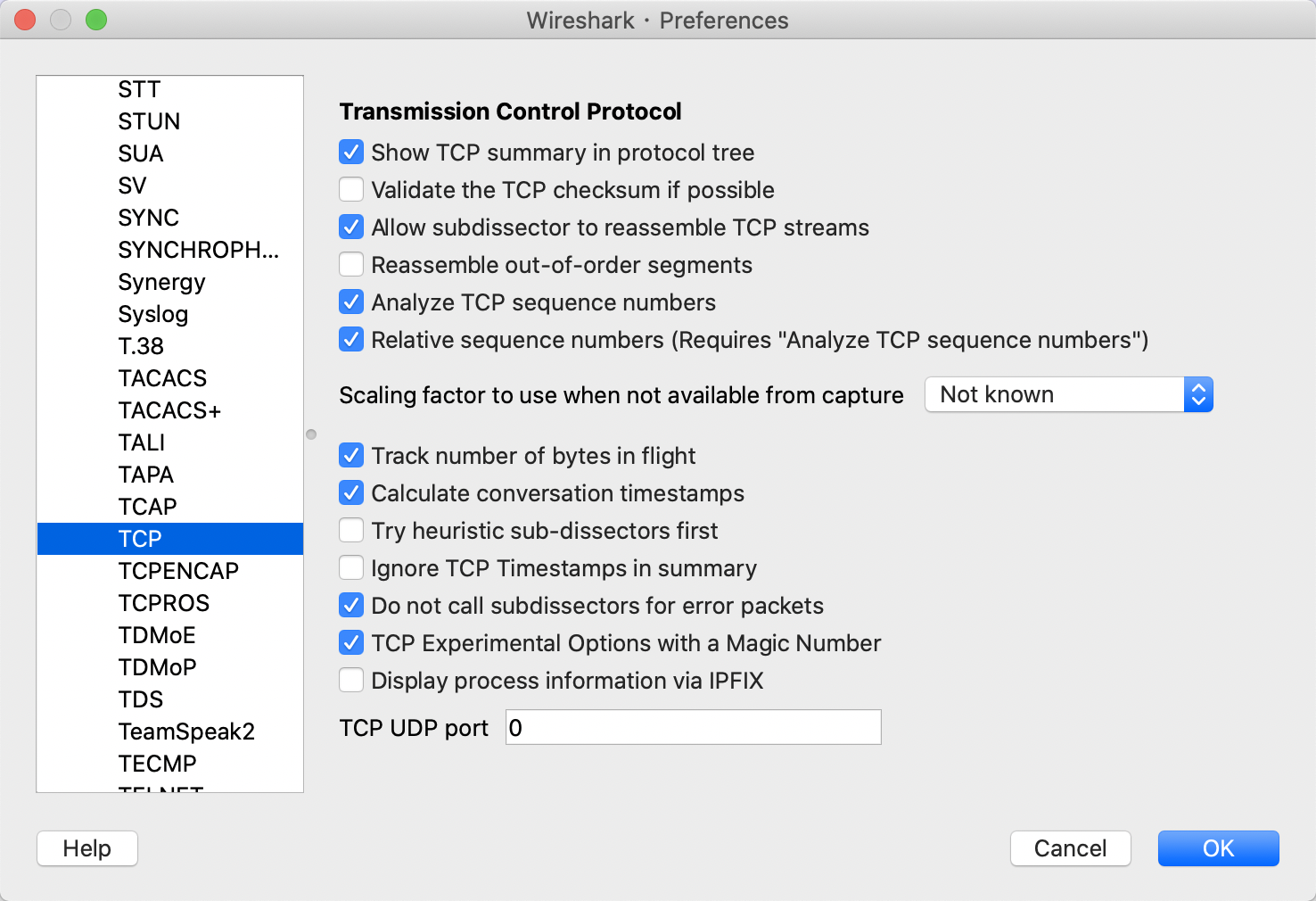
View->Coloring Rules修改颜色规则 - 协议的细节设置可以在
Preferences->Protocols中进行设置,例如对 tcp 协议的设置项如下:
过滤
除了在抓包的时候可以进行过滤,报文在完成抓取后还可以进一步过滤。很多时候,解决问题的关键就是找到关键报文:
- 如果是某个协议发生问题,可以直接用协议名称过滤
-
IP地址加端口:例如
ip.src_host==127.0.0.1 and tcp.srcport==8000 -
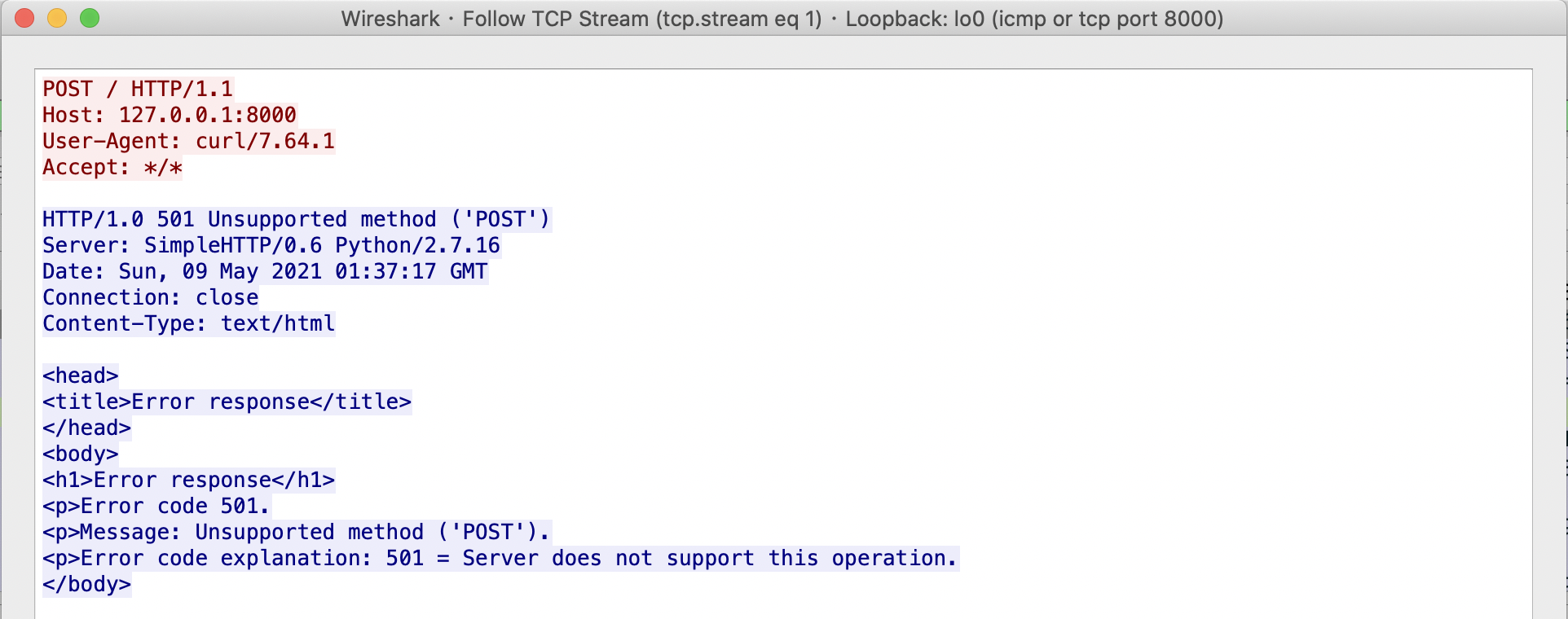
Wireshark 提供了更快捷的方式:在感兴趣的包上单击右键,选择
Follow->TCP Stream就可以自动选择该 TCP 流的所有数据包,并且在新窗口中显示该 stream 内容,如下所示
- Wireshark 根据五元组过滤出 TCP/UDP Stream。通过
Wireshark 的 Statistics->Conversations,选择 TCP/UDP 标签,就可以看到对应的 TCP/UDP stream 统计信息

-
当鼠标选中某个报文的某个字段后,通过
Prepare a Filter->Selected/And Selected/...等选项就可以将在 Filter 框中自动生成对应的过滤表达式。如果选择的是Prepare a Filter->Selected/And Selected/...,则直接应用该过滤条件 -
通过
File->Export Specified Packets按要求保存数据包 -
Wireshark 也支持按关键字搜索报文,通过
Ctrl+F进行搜索,搜索内容为Packet bytes,搜索方式为String,例如:

让 Wireshark 自动分析
有时候我们不需要研究包的细节,可以让 Wireshark 帮我们自动分析:
- 通过
Analyse->Expert Info可以看到不同级别的提示信息,例如连接建立、连接终止等信息。在分析网络性能和连接问题时,经常需要借助这个功能 - 通过
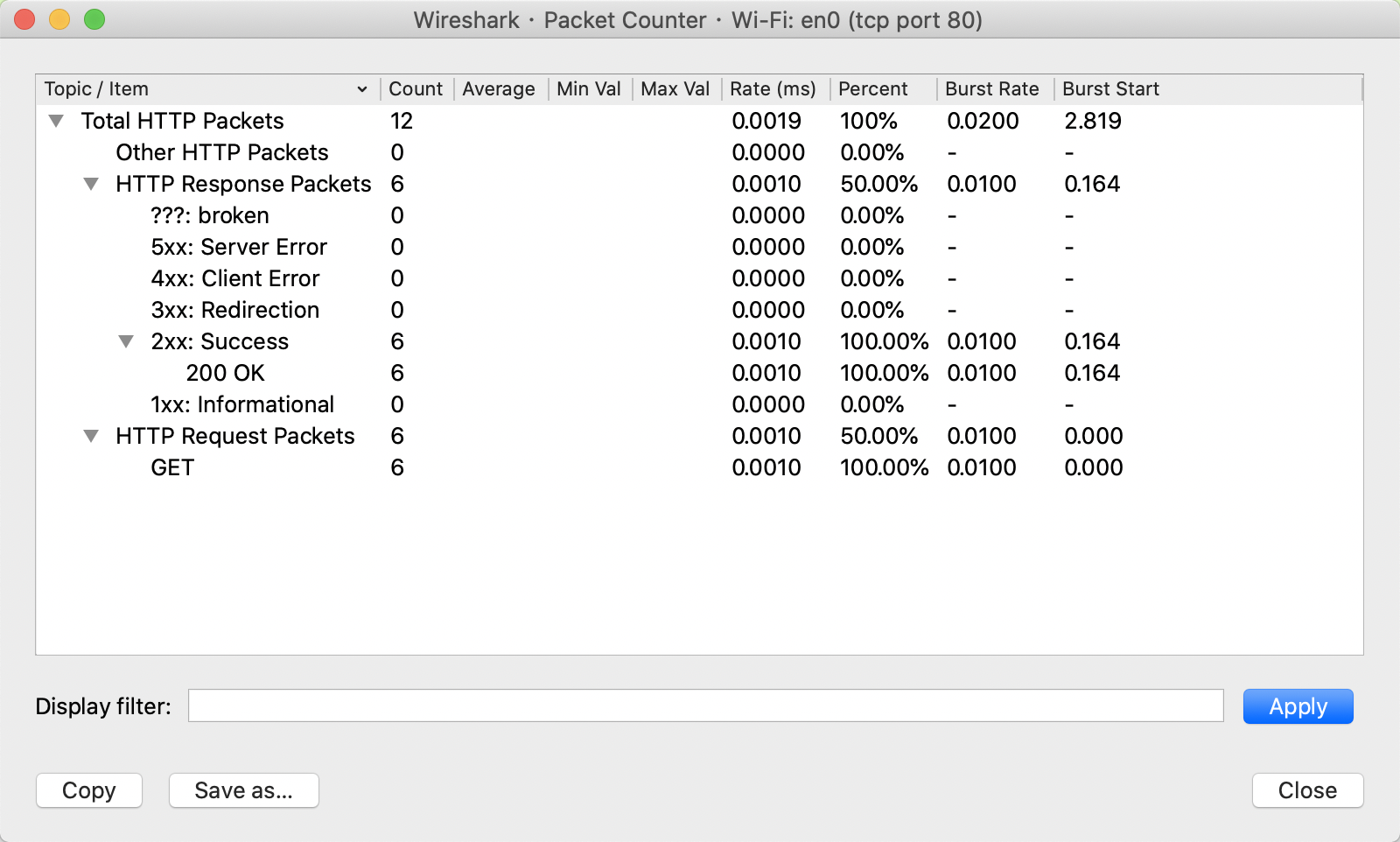
Service->HTTP/DNS/...可以查看具体协议的统计信息,例如查看 HTTP 的统计信息
- 通过
Statistics->TCP Stream Graph可以查看 TCP 的统计图 - 通过
Statistics->Capture File Properties可以获取总体的统计信息
使用 Wireshark 分析 TCP
TCP 一直是 TCP/IP 协议栈中非常复杂的一部分,接下来将使用 Wireshark 分析一个典型的 TCP 连接建立/断开过程。这里我使用 curl www.baidu.com 访问百度首页,使用 Wireshark 抓到的报文如下:
- 首先是 TCP 建立所涉及的三个报文,也被称为 TCP 三次握手。可以看到,在前两个报文中,双方都把自己的 MSS(Maximum Segment Size)告诉对方,MSS 为
本端 MTU - IP 头部长度(通常为 20 字节)- TCP 头部长度(通常为 20 字节)。在建立连接时主动通告自己的 MSS,也体现了 TCP 会主动为 IP 层着想,避免报文传递给 IP 层后被 IP 层分片。但是这种方式并不能完全避免报文分片,因为如果网络路径上存在 MTU 小于通信双方所通告的 MTU 的话,这个包还是会被分片。

- 接来的报文则是应用层通信过程,即一个典型的 HTTP 交互过程,客户端发送 HTTP GET 请求(4 号包),服务器返回 HTTP 响应(6,7,8)。另外,5 号包是服务器端 TCP 层对所接收到的 4 号包的 ACK 报文。服务器的 HTTP 响应一共通过 3 个报文发送,所有报文的 TCP 数据部分长度都不超过 1370(即通信双方的 MSS 中的较小值,本例中服务端的 MSS 为 1370,客户端通告的 MSS 为 1460,所以通信双方 TCP 数据部分长度都不会超过 1370)。9、10 号包是客户端 TCP 层对所接收到的 HTTP 响应数据的 ACK 报文,其中 9 号包是对 6、7 号包的确认,10 号包是对 8 号包的确认。11 号包是客户端的 TCP 窗口更新通告,这侧面反映此时客户端程序从 TCP socket buffer 里将 HTTP 响应数据读走了,所以接收端窗口恢复成初始值 262144

- 最后 4 个报文则是典型的 TCP 连接断开过程,也被称为
TCP 四次挥手过程。

从整个 TCP 报文交互过程我们也可以看到,SYN包、FIN 包都需要占据一个发送序号,而单纯的 ACK 包是不占发送发送序号的。另外,这里看到的报文序号是从 0 开始,这是因为 Wireshark 启用了 Relative Sequence Number 功能,真实的序号并不一定是从 0 开始。
Wireshark 定位 TCP 三次握手/四次挥手相关问题
握手失败一般分为两种类型:要么被拒绝,要么是丢包了。使用如下两个过滤表达式可以定位大多数失败的握手
(tcp.flags.reset == 1) && (tcp.seq == 1):过滤出所有含有 Reset 标志的相对序号为 1 的报文- (tcp.flags.syn == 1) && (tcp.analysis.retransmission):过滤出重传的握手请求。重传有可能是 SYN 报文丢弃,也有可能是对端恢复的 ack 报文丢弃。
通过 Wireshark 的 Analyse->Expert Info->Chats 可以迅速发现是否遭遇了 SYN 泛洪攻击。
TCP 的延迟确机制,可能导致 TCP 的挥手过程只需要 3 个报文即可完成,此时第二个报文为 FIN/ACK 包。
TCP 窗口
TCP 为应用层提供可靠的传输机制,但是如果发送端每发送一个包就停下来确认,那么一个往返时间里只能传一个包,这样传输效率太低了。最快的方式是一口气把所有包都发出去,然后一起确认。但是现实中也存在一些其他限制,例如接收方的缓存(接收窗口)无法一下子接收太多数据;或者网络的带宽也是有限的,发送端一口气将报文全部发出来可能会导致丢包。所以发送方需要知道接收窗口和网络两个限制因素哪一个更严格,然后在其限制范围内尽可能多发包。一口气能够发送的数据量就是传说中的 TCP 发送窗口。
- 每个 TCP 报文的头部都包含
Window Size字段,这是在向对端通告自己的接收窗口大小(并没有办法从 TCP 报文中得知发送端的发送窗口大小)。对端收到该通告后,就会把自己的发送窗口限制在该范围内,这就是 TCP 滑动窗口机制的一部分。 - 发送窗口决定了一口气能够发送多少字节,MSS 决定了这些字节要分多少个包发完。
- TCP 头部中
Window Size只占 16 位,所以最大值只能为 65535。而现在随着网络的进步,该窗口大小已经远远无法满足应用程序对性能的要求。RFC1323 提出了一个解决方案:在 TCP 三次握手过程中,将Window Scale放在 TCP 头部选项中,Window Scale用于向对方声明一个偏移量,以该偏移量进行 2 的指数运算,即得到 Scale 值。将Window Size乘以该 Scale 值即为最终的Window Size。如下展示了上个例子中服务器 SYC-ACK 报文中所通告的Window Scale值:

Window Scale只会在建立连接时进行通告,之后报文交互过程中,都需要将报文中所通告的Window Size乘以之前对端所通告的Window Scale,才是对端当前真实的接收窗口大小。Wireshark 在显示Win时也是根据这一方法计算的,所以如果抓包时没有抓到三次握手,Wireshark 就不知道该如何计算,这时可能就会看到一些极小的接收窗口值
决定发送窗口的因素有两个:
- 网络上的拥塞窗口(Congestion Window,缩写为 cwnd)
- 接收端的通告的接收窗口
发送端的输出不能超过 cwnd 和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
cwnd 的增长方式是先 慢启动,然后再是 拥塞避免。前者起点低但能快速增长,后者起点高,但是每个 RTT 只能增加一个 MSS。在 Wireshark 中,选中一个发送窗口中最后的一个包,看到它的 Bytes in flight,有时它就可以代表 cwnd 的大小(当发送数据量没有达到接收窗口大小时,但却没有继续发送,说明此次发送端受 cwnd 的影响)。
理论上只要窗口足够大,TCP 也可以不受往返时间的约束而源源不断地传送数据。当然 TCP 确实也有因为往返时间而降低效率的时候,例如传输小块数据,本来一个 RTT 时间就可以完成的事情,却需要额外的 3 次握手和 4 次挥手。Google 的 QUIC(Quick UDP Internet Connection)协议就是为了消除 TCP 的延迟而设计的替代品。
TCP 重传
网络因素之所以会影响发送窗口,是因为如果网络一下子收到太多数据时,就会发生拥塞,拥塞的结果就是丢包,那么这个时候接收端可能就无法对报文进行确认,发出的报文一直缓存在发送窗口中,等待重传。这个时候应用程序的可用发送窗口也就受限。能够导致网络拥塞的数据量称为拥塞点,发送方应该将发送窗口控制在拥塞点以下,这样就能避免拥塞了。但是拥塞点并不容易计算,因为传输路径中可能存在多个网络设备,其中任意一个设备都可能是瓶颈。而且拥塞点是一个随时会改变的动态值,这就更加不好估算了。
为了解决该问题,就有了 TCP 的拥塞避免机制。它的策略就是在发送方维护一个虚拟的拥塞窗口,并利用各种算法使他尽可能接近真实的拥塞点。网络对发送窗口的限制,就是通过拥塞窗口实现的:
- 连接刚刚建立的时候,发送方对网络状况一无所知,如果一口气发送太多就可能遭遇拥塞,所以发送方把拥塞窗口的初始值定的很小,RFC 的建议是 2 个、3 个或者 4 个 MSS,具体根据 MSS 大小而定
- 如果发出去的包都得到确认,表明还没有到达拥塞点,可以增大拥塞窗口。由于该阶段发生拥塞的概率很低,所以增速应该快一些。RFC 建议的算法是每收到 n 个确认,就可以把拥塞窗口增加 n 个 MSS。这个过程增速很快,但是由于基数较低,传输速度还是比较慢的,所以称为慢启动过程
- 慢启动过程持续一段时间后,拥塞窗口达到一个较大值,这时候传输速度较快,触碰到拥塞点的概率比较大,所以不能再继续采用翻倍的慢启动算法了,而是要缓慢一点,,RFC 建议的算法是在每个往返时间增加 1 个 MSS,这个过程称为拥塞避免。从慢启动过渡到拥塞避免的临界窗口值很有讲究:如果之前发送过拥塞,就将该拥塞点作为参考依据,如果从来没有拥塞过就可以取相对较大的值,比如和最大接收窗口相等
如果发生拥塞,对发送方来说,就是发出去的包不像往常一样得到确认了。但是收不到确认也可能是网络延迟所导致的。所以发送方会等待一段时间再判断,如果一段时间后仍然没有收到,就认为该包丢失了,只能重传了。这个过程称为超时重传。从发出原始包到重传该包的时间称为 RTO。重传之后需要重新调整拥塞窗口,为了不给刚发生拥塞的网络雪上加霜,RFC 建议把拥塞窗口降到一个 1 个 MSS,然后再次启动慢启动过程,此时从慢启动过渡到拥塞避免的临界窗口值就有参考依据了。 RFC 5681 认为应该是发生拥塞时没有被确认数量的 1/2,但不能小于 2 个 MSS。
超时重传对性能有严重影响:
- RTO 阶段不能传数据,相当于浪费了一段时间
- 拥塞窗口急剧减小,相当于接下来传得慢的多了
通过 Wireshark 的 Analyse->Expert Info 可以看到重传情况。
当拥塞较小导致少量包丢失时,或者偶然因素导致校验码不对时,会导致单个丢包。这两种丢包和严重拥塞时不一样,因为后续有包能正常到达,当后续的包到达时,接收方会发现其 Seq 比期望的大,所以每收到一个包就 Ack 一次期望的 Seq 序号,以提醒发送方重传。当发送方收到 3 个或以上重复确认时,就意识到丢包了,从而立即重传它,这个过程称为快速重传,它不需要像超时重传一样需要等待一段时间。
之所以需要凑满 3 个,是因为网络包有时会乱序,乱序的包一样会触发重复的 Ack,但是为了乱序而重传没有必要。一般乱序的距离不会相差太大,所以限定 3 个或以上可以很大程度上避免因为乱序而触发快速重传。
如果在拥塞避免阶段发生了快速重传,不会像发生超时重传一样处理拥塞窗口。因为完全没有必要。既然后续的包都到达了,说明网络并没有严重拥塞,接下来传慢点就可以了。RFC5681 建议临界窗口值应该设置为发生拥塞时还没有被确认数据量的 1/2(但不能小于 2 个 MSS),然后将拥塞窗口设置为临界窗口值加 3 个 MSS,继续保留在拥塞避免阶段,这个过程称为快速恢复。
很多时候丢的包不止一个,而通过接收方的 ACK 序号只能知道该序号的包肯定需要重传,但并不知道还有哪些包也丢失了,此时有几种方案:
- 将发送窗口中未确认的包都重传一遍,效率较低(丢一个包导致多个包被重传),早期的 TCP 协议就是这样处理的
- 只重传相应序号的包,当丢包量较大时,需要花费很多个 RTT 时间来重传所有丢失的包
- 接收方在发送 Ack 包时,顺便把收到的包号告诉发送方,这样发送方对丢包细节了如指掌。这个方案称为 SACK,由 RFC2018 定义。
最后介绍了一个经验,丢包对极小文件的影响比大文件严重。因为读写一个小文件需要的包数据很少,所以丢包时往往凑不满 3 个 Dup ACK,只能等待超时重传了,而大文件有较大可能触发快速重传。
网络承载量可以用已经发送出去,但是尚未确认的字节数来表示(bytes in flight,在途字节数)。在途字节数如果超过了网络的承载能力,也会丢包重传。在 Wireshark 中通过某一个时间点的发包序号、已被确认序号计算得知:在途字节数 = Seq + Len - Ack。当发送方一口气向网络中注入大量数据时,就可能超过该网络的承受能力而导致拥塞,这个足以触发拥塞的数据量就称为拥塞点。大致可以认为:发生拥塞时的在途字节数即是该时刻的网络拥塞点。
拥塞的特征就是连续丢包,丢包就会重传,而 Wireshark 是可以标识出重传报文的。因此:先从 Wireshark 中找到一连串重传包中的第一个,在根据该重传包的 seq 值找到其原始包,最后计算该原始包发送时刻的在途字节数。由于网络拥塞就是在该原始包发出去的时刻发生的,所以在途字节数就大致代表了拥塞点的大小。该方法不一定准确,但是有参考意义,最好多次采样,然后选定一个合适的值作为拥塞点。
在局域网中,当重传率超过 0.1% 就值得采取措施了。
延迟确认
TCP 的延迟确认原理是:如果收到一个包之后暂时没有什么数据要发送给对方,那么就延迟一段时间再确认。如果在这段时间里恰好有数据要发送,那确认信息和数据就可以在一个包里发出去。延迟确认并没有直接提高性能,它只是减少了部分确认包,减轻了网络负担。而且有时候延迟确认反而会影响性能。
例如在某些古老的 TCP 协议栈在处理网络拥塞时,可能会出现如下情况:
- 假设客户端在同一发送窗口发送了 9 个 TCP 包,但是 3、4、5 号因为拥塞丢失了
- 到达服务器的 6、7、8、9 触发了 4 个
Ack 3,于是客户端迅速重传报文 3 - 服务器收到重传的 3 号报文后,由于启用了延迟确认,所以等待 200ms 才恢复 Ack 4
- 客户端重传 4 号包,服务器又等待 200ms 后才回复 Ack 5
- 客户端重传 5 号包,服务器又等待 200ms 后才回复 Ack 10
所以此时:在连续丢掉多个包后,由于延迟确认,每个重传都需要等待 200ms。所以延迟确认和重传放在一起,可能会影响性能。
对于上述问题,启用 TCP SACK(Selective Acknowledgement)可以解决该问题。通过服务器的 SACK,客户端可以一次性重传多个丢包,而不用每重传一个就等待一次 ACK,白白浪费多个往返时间。
延迟确认导致性能下降的另外一种场景是:TCP 窗口极小的情况下,发送端每次发送若干个 MSS 后就会耗光窗口,若此时再开启延迟确认,那么每次发送端都需要等待 200ms 后(收到对端的 Ack)才可以继续发送。
在 Wireshark 中 使用 tcp.analysis.ack_rtt > 0.2 and tcp.len==0 可以将超过 200毫秒的确认都筛选出来。
Nagle 算法
Nagle 算法的原理是:在发出去的数据还没有确认前,假如又有小数据生成,那么把小数据收集起来,凑满一个 MSS 或者等收到确认后再发送。和延迟确认一样,Nagle 也没有直接提高性能,启用它的作用是提高传输效率,减轻网络负担。在某些场合下,和延迟确认一起使用时甚至会降低性能(发送端由于需要凑慢一个 MSS 而没有立即发送数据,而对端又开启了延迟确认,导致 Ack 迟迟不来,导致应用层数据一直没有得到发送,从而导致性能降低)。
LSO 与 LRO
LSO(Large Segment Offload)是为了拯救 CPU 而出现的一个创意,传统网络的工作方式是:应用层把产生的数据交给 TCP 层,TCP 层再根据 MSS 的大小进行分段(由 CPU 负责),然后再交给网卡,而启用 LSO 之后,TCP 层就可以把大于 MSS 的数据块直接传给网卡,让网卡来负责分段工作。而发送方 Wireshark 抓包时是站在 CPU 的视角,所以可能看到是一个分段前的大包。
LRO(Large Receive Offload),会积累多个 TCP 包再集中处理,此时可能造成 Ack 数目小于其他机器(在没有开启延迟确认的情况下,并不是所有的 TCP/IP 实现都是收到 n 个数据包就回复 n 个 Ack 的,例如很多 Linux 服务器就是累计收到两个数据包才 Ack 一次)。
多 TCP 连接问题
因为网络延迟、拥塞和应用层设计问题,单个连接可能无法占满整个物理链路,此时可以通过增加一些连接数来占满链路。但是当连接数多到足以占满整个链路时,再增加连接就没有意义了,甚至可能会带来负面效果(可能会增加丢包率)。当 Wireshark 提示 [TCP window Full],此时表明发送方发送的数据量已经达到了对方所声明的接收窗口大小,不能再发了,此时只好停下来等待。这说明带宽没有完全利用,应该继续增加发送窗口或者连接数来补充。
Wireshark 的其他事项
- 受损的帧不会在 Wireshark 中显示。数据链路层的 FCS(Frame Check Sequence)机制就会直接丢弃受损的帧。通过
netstat -i | column -t可以直接查看 Linux 上 FCS 错误统计 Packet size limited during capture:表示被标记的包没有抓全,一般是由抓包方式引起的,tcpdump 默认只抓每个帧的前 96 个字节,可以使用-s来指定抓包字节数TCP Previous segment not captured:缺失的数据包在整个网络包(排除乱序后)都找不到,就会提示该信息TCP ACKed unseen segment:当 Wireshark 发现被 Ack 的包没有被抓到,就会提示该信息。一般是由于抓包开始时错误过了前面的数据包TCP Out-of-Order:乱序数据包,小跨度的乱序影响不大,但是大跨度的乱序却可能重发快速重传TCP Dup ACK:当乱序或丢包时,接收方会收到一些 Seq 号比期望值大的包。它每收到一个这种包时,就会 Ack 一次期望的 Seq 值,以此来提醒发送方,于是就产生了重复的 Ack。TCP Fast Retransmission:当发送方收到 3 个以上TCP Dump Ack就意识到之前发的包可能丢了,于是快速重传它TCP Retransmission:如果一个包真的丢了,但是又没有后续包可以在接收方触发Dup Ack,就不会触发快速重传。此时只能等到发送方的超时重传了,该类包被 Wireshark 标记为TCP RetransmissionTCP zerowindow:TCP 包中的win=表示接受窗口的大小,即表示这个包的发送者当前还有多少缓存区可以接收数据。当win=0时,Wireshark 就会给该报文打上TCP zerowindow标志,表示缓冲区已满,不能再接收数据TCP window Full:表示这个包的发送者已经把对方声明的接收窗口耗尽了,即在途字节数已经达到最大值了TCP segment of a reassembled PDU:这说明开启了Allow sub dissector to reassemble TCP stream,它表示 Wireshark 可以把属于同一个应用程序 PDU 的 TCP 包虚拟地集中起来。Wireshark 在最后一个包中虚机地把所有包集中起来Continuation to #:这说明没有开启Allow sub dissector to reassemble TCP stream,这时同一个应用程序 PDU 的包没有被 Wireshark 集中起来Time-to-live exceeded (Fragment reassembly time exceeded):ICMP 错误之一,表示这个包的发送方之前收到了一些分片,但是由于某些原因迟迟无法组装起来- 如果服务器上的多个网卡被绑定为一个 NIC Teaming,需要注意它的类型。如果为 TLB(Transmit Load Balancing)则收包由一个网卡负责,发包则分摊给所有网卡。
- 每经过一次路由,网络包的 TTL 值就减去 1,有时网络包的 TTL 值也有助于定位网络问题,TTL 的初始值值一般为 64。
tshark
tshark 是 wireshark 的命令行版本,和图形界面相比,命令行有一些先天的优势:
- 命令行的输出可以直接通过 awk 之类的方式处理处理,这是图形界面难以实现的
- 编辑命令虽然费时,但是编辑好后可以反复使用
- tshark 输出的分析文本大多数可以直接写入分析报告中,而 Wireshark 生成不了这样的报告
- 命令行往往比图形界面快的多