程序中的形式应该仅仅反映它所要解决的问题,代码中的其他任何外加形式都是一个信号,表明对问题的抽象还不够深。迭代是数据处理的基石。扫描内存中存不下的数据集时,需要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式。
在 Python 中所有集合都可以迭代,在 Python 语言内部,迭代器用于支持:
- for 循环
- 构建和扩展集合类型
- 逐行遍历文本文件
- 列表推导、字典推导和集合推导
- 元祖拆包
- 调用函数时,使用 * 拆包实参
一个单词序列实例
接下来实现一个 Sentence 类,向该类的构造方法传入包含一些文本的字符串,然后可以逐个单词迭代。如下版本实现了序列协议,因此这个类的对象是可迭代的(因为所有序列都是可迭代的)。
1 | import re |
1 | import sentence |
findall 返回一个字符串列表,里面的元素是正则表达式的非全部重叠匹配。可以看到 Sentence 类实例可以迭代,也支持序列操作,例如按索引获取单词。我们都知道,序列可以迭代,这里详细解释一下原因。
解释器需要迭代对象 x 时,会自动调用 iter(x)。内置的 iter 函数有以下作用:
- 检查对象是否实现了
__iter__,如果实现了,则调用它获取一个迭代器 - 如果没有实现
__iter__,但是实现了__getitem__方法,则 Python 会创建一个迭代器,尝试按照顺序(从索引 0 开始)获取元素 - 如果尝试失败,Python 则抛出 TypeError 异常,提示该对象不可迭代
任何 Python 序列都是可迭代的原因是,它们都实现了 __getitem__ 方法。其实标准的序列也实现了 __iter__ 方法,因此你自己实现的序列最好也这样做。之所以会对 __getitem__ 方法做特殊处理,是为了向后兼容。
虽然 Sentence 类是可以迭代的,但是却无法通过 issubclass(Sentence, abc.Iterable) 测试(没有实现 iter 方法)。从 Python3.4 开始,检查对象 x 是否可以迭代,最准确的方法是调用 iter(x) 函数,如果不可迭代,再处理 TypeError 异常。iter(x) 函数会考虑遗留的 __getitem__ 方法,而 abc.Iterable 类则不会考虑。
可迭代对象和迭代器的对比
可迭代对象:使用 iter 内置函数可以获取迭代器的对象:
- 如果对象实现了返回迭代器的
__iter__方法,那么对象就是可以迭代的 - 序列都可以迭代,因为其实现了
__getitem__方法,而且其参数是从 0 开始的索引
因此可迭代的对象和迭代器之间的关系是:Python 从可迭代对象中获取迭代器。如下一个简单的循环中,字符串是可迭代对象,背后是有迭代器的:
1 | for c in 'abc': |
如果没有 for 语句,则需要使用 while 循环模拟:
1 | s = 'abc' |
- 使用可迭代对象构建迭代器 it
- 不断在迭代器上调用 next 函数,获取下一个字符
- 如果没有字符,迭代器抛出 StopIteration 异常
- StopIteration 异常表明迭代器到头了,Python 语言内部会处理 for 循环和其他迭代上下文(如列表推导、元祖拆包)中的 StopIteration。
标准的迭代器接口有两个方法:
__next__方法:返回下一个可用的元素,如果没有元素了,则抛出 StopIteration 异常__iter__方法:返回 self,以便在应该使用可迭代对象的地方也可以使用迭代器,例如 for 循环中
如下展示了展示了这些关系:
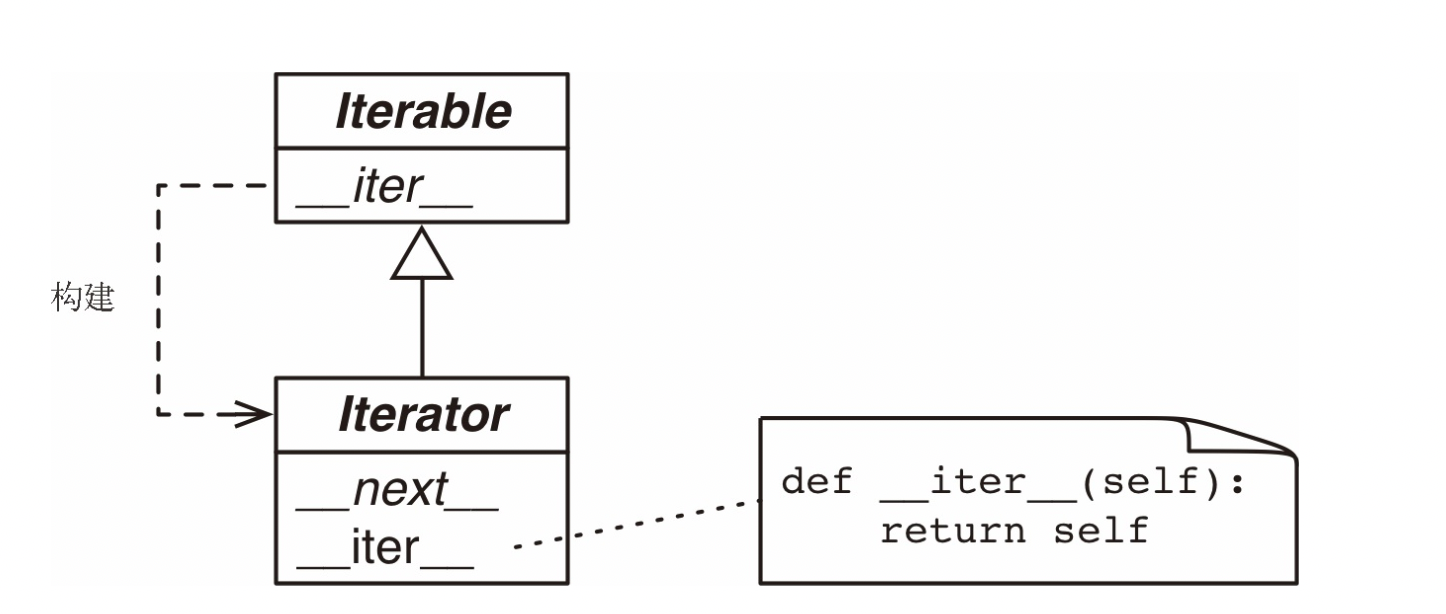
检查对象 x 是否为迭代器的最好方法是调用 isintance(x, abc.Iterator),得益于 Iterator.__subclasshook__ 方法,即使对象 x 所属的类不是 Iterator 类的真实子类或虚拟子类,也能检查。
1 | >>> s = sentence.Sentence("this is a test") |
如果想还原迭代器,即想再次迭代,只能使用 iter() 传入之前构建迭代器的可迭代对象。传入迭代器本身没有用,因为 Iterator.__iter__ 方法的实现方式是返回实例本身,所以传入迭代器无法还原已经耗尽的的迭代器。
总结一些,迭代器是这样的对象,实现了无参数的 __next__ 方法,返回序列中的下一个元素,如果没有元素了,则需要抛出 StopIteration 异常。Python 中的迭代器还实现了 __iter__ 方法,因此迭代器本身也是可迭代对象。由于内置的 iter() 函数会对序列做特殊处理,因此序列也是可迭代对象。
all、any、max、min、reduce、sum 等函数都接受一个可迭代的对象,然后返回单个结果。这些函数被称为归约函数。另外,all 和 any 函数来说,这两个函数会短路求值(即一旦确定了结果就立即停止使用迭代器)。
典型的迭代器
如下的 Sentence 类可以迭代,因为它实现了特殊的 __iter__ 方法,构建并返回了一个 SentenceIterator 实例,这也符合一般设计模式书籍中所描述的 迭代器设计模式。
1 | import re |
1 | import sentence_v2 |
这里 SentenceIterator 这个迭代器类实现了 __next__ 和 __iter__ 两个方法,如果让 SentenceIterator 类继承 abc.Iterator 类,那么它会继承 abc.Iterator.__iter__ 这个具体方法。
由于迭代器也实现 __iter__ 方法并且返回 self,因此迭代器是可迭代对象,但是可迭代对象不是迭代器。不要在可迭代对象中实现 __next__ 方法,试图让可迭代对象也是自身的迭代器。因为迭代器模式是用来:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口
为了支持多种迭代,必须能从一个可迭代的实例中获取多个独立的迭代器,而且每个迭代器都要能维护自身的内部状态。因此正确的方法是调用 iter(my_iterable) 都新建一个独立的迭代器。
深入分析 iter 函数
在 Python 中迭代对象 x 时,会调用 iter(x) 获取 x 的迭代器。iter 函数还有一个用法:使用常规的函数或者任何可调用的对象创建迭代器。此时需要传入两个参数,第一个参数必须是可调用的对象,用于不断调用(没有参数)产出值,第二个值是哨符,这是个标记值,当调用对象返回这个值时,触发迭代器抛出 StopIteration 异常,而不产生哨符。
1 | from random import randint |
这里的 iter 函数返回一个 callable_iterator 对象。
生成器函数
实现相同功能,但是更符合 Python 的习惯方式是,用生成器函数替代 SentenceIterator 类。
1 | import re |
1 | import sentence_v3 |
在这个例子中,生成器就是迭代器,每次 __iter__ 方法都会返回一个生成器,__iter__ 方法就是生成器函数。只要 Python 函数的定义体中有 yield 关键字,该函数就是生成器函数。调用生成器函数时,会返回一个生成器对象,即生成器函数是生成器工厂。普通函数与生成器函数在语法上的唯一区别是,生成器函数定义体中有 yield 关键字。如下说明了生成器函数的行为:
1 | def gen_123(): |
- gen_123 自己是函数对象,只不过其含有 yield 关键字,因此是生成器函数
- gen_123() 返回一个生成器
- 生成器是迭代器(生成器实现了
__next__和__iter__方法),会返回传给 yield 关键字的表达式的值。把生成器传给 next(…) 函数时,生成器会向前,执行函数定义体中下一个 yield 语句,返回产生的值,并在函数定义体中的当前位置暂停。最终函数的定义体返回时,外层的生成器对象会抛出 StopIteration 异常,这与迭代器协议一致
需要注意,迭代生成器是产生值,生成器不会以常规的方式返回值,生成器函数定义体中的 return 语句会触发生成器对象抛出 StopIteration 异常。
惰性实现
惰性实现是指尽可能延后生成值,这样做能节省内存,而且还可以避免做无用的处理。目前的 Sentence 类都不具备惰性,因为在其 __init__ 方法中都急迫地构建好了文本中的单词列表。re.finditer 函数是 re.findall 的惰性版本,返回的不是列表,而是一个生成器,按需生成 re.MatchObject 的实例。
1 | import re |
1 | import sentence_v4 |
这里 match.group() 方法从 MatchObject 实例中提取出匹配正则表达式的具体文本。
等差数列生成器
生成器也可用于生成不受数据源限制的值。如下定义了一个 ArithmeticProgression 类,实现了等差数列:
1 | class ArithmeticProgression: |
如果一个类只是为了构建生成器而去实现 __iter__ 方法,那还不如直接使用生成器函数。
1 | def aritprog_gen(begin, step, end=None): |
标准库有许多现成的生成器。itertools 模块提供了很多生成器函数:
- itertools.count 函数返回的生成器能生成多个数,并且可以提供可选的 start 和 step
- itertools.takeWhile 会生成一个使用另一个生成器的生成器,在指定条件计算结果为 False 时停止
因此更简单的实现方法为:
1 | import itertools |
标准库中的生成器函数
实现生成器时,要知道标准库中有什么可用,否则可能会重新发明轮子。
- 用于过滤的生成器函数:从输入的可迭代对象中产出元素的子集,而且不修改元素
- 用于映射的生成器函数:在输入的可迭代对象中的各个元素上做计算,然后返回结果
- 用于合并的生成器函数:这些函数都从输入的多个可迭代对象中产出元素。
- 有些生成器函数会从一个元素中产生多个值,扩展输入的可迭代对象
- 用于产出输入的可迭代对象中的全部元素,但是会以某种方式重新排列。
生成器表达式
简单的生成器函数,可以替换成生成器表达式。生成器表达式可以理解为列表推导的惰性版本:不会迫切地构建列表,而是返回一个生成器,按需惰性生成元素。也就是说列表推导是生产列表的工厂,那么生成器表达式就是制造生成器的工厂。
如下展示了列表推导和生成器表达式的区别:
1 | def gen_AB(): |
可以看到,列表推导急切地迭代 gen_AB() 函数产生的生成器,从而得到列表。而生成器表达式只有真正迭代时,才会迭代 gen_AB 产生的生成器。可以看出,生成器表达式会产出生成器。因此 Sentence 类的代码可以进一步简化:
1 | import re |
可以看到,这里使用生成器表达式构建生成器,然后将其返回。最终效果是一样的,调用 iter 方法会得到一个生成器对象。
何时使用生成器表达式
生成器表达式是创建生成器的简单语法,这样无需定义函数再调用。但是生成器函数更灵活,可以使用多个语句实现复杂的逻辑,也可以作为协程使用。具体使用哪种语法,可以根据如下经验判断:
- 如果生成器表达式需要分多行写,倾向于定义生成器函数,以便提高可读性
- 另外,生成器函数有名称,因此可以重用
yield from
如果生成器函数需要产出另一个生成器生成的值,传统的解决方法,是使用嵌套的 for 循环,例如如下自己实现了 chain 函数:
1 | def chain(*iterables): |
使用 yield from i 可以替代内层的 for 循环,如下所示:
1 | def chain(*iterables): |
除了替代循环外,yield from 还会创建通道,把内层生成器与外层生成器的客户端联系起来。把生成器当成协程使用时,这个通道特别重要,不仅能够为客户端代码生成值,还能使用客户端代码提供的值。这些知识后面讲解协程时会详细介绍。
把生成器当成协程
接下来要介绍生成器的另一个特性。与 __next__() 方法一样,.send() 方法可以使生成器前进到下一个 yield 语句,但是 .send() 方法允许使用生成器的客户把数据发给自己,即不管传给 .send() 方法什么参数,那个参数都会成为生成器函数定义体中对应的 yield 表达式的值。也就是说,.send() 方法允许在客户代码和生成器之间双向交换数据,而 __next__() 只允许客户从生成器中获取数据。
这一特性改变了生成器的本性:生成器本身就变成了协程:
- 生成器用于生成可供迭代的数据
- 而协程是数据的消费者
- 不能把这两个概念混为一谈,协程与迭代无关。虽然在协程中会使用 yield 产出值,但是这与迭代无关
最后,再介绍使用生成器时的一个注意点,因为 yield 关键字只能把最近的外层函数变成生成器函数。虽然生成器函数看起来像函数,但是不能通过简单的函数调用把职责委托给另一个生成器函数。而 yield from 方法允许生成器或协程把工作委托给第三方完成。