最近又开始研究容器网络了,本系列文章是 《Kubernetes 网络权威指南》的读书笔记。首先介绍的是 Linux 为网络虚拟化的基础知识,包括 Linux network namespace、tap/tun 设备、iptables、VxLAN 等等。
Network namespace
Linux 的 namespace 的作用是隔离内核资源。Linux 共提供了 6 类系统资源的 namespace:
- Mount namespace:文件系统挂载点 namespace
- UTS namespace:主机名 namespace
- IPC namespace:POSIX 进程间通信消息队列 namespace
- PID namespace:PID namespace
- Network namespace:网络 namespace
- User namespace:用户 namespace
默认情况下,Linux 进程处在和宿主机相同的 namespace,即初始的根 namespace 里,默认享有全局系统资源。Docker 容器作为一项轻量级的虚拟化技术,它的隔离能力来自于 Linux 内核的 namespace 技术。
Network namespace 作用是隔离 Linux 系统的 IP 地址、端口、路由表、防火墙规则等网络资源。
初识 network namespace
和其他 namespace 一样,Network namespace 可以通过系统调用来创建:
- 通过 Linux 的 clone() API 创建一个通用 namespace
- 如果参数传入 CLONE_NETWORK 表示创建一个
Network namespace
Linux 的 ip 工具也可以用于管理 Network namespace。
- 使用
ip netns add netns1创建一个Network namespace。此时系统会在 /var/run/netns 目录下生成一个挂载点。它的作用是(1)方便对 namespace 的管理(2)namespace 中即使没有进程存在,也能继续运行
1 | # ip netns add netns1 |
- 可以通过
ip netns exec命令在指定的Network namespace中执行命令
1 | # ip netns exec netns1 ip link show |
ip netns list查看所有的Network namespace
1 | # ip netns list |
ip netns delete删除指定的 namespace。其实这条命令并不会删除Network namespace。它只是移除了对应的挂载点,只要里面还有进程在运行,namespace就一直存在
配置 Network namespace
新创建的 Network namespace 只包含环回口 lo,而且还是 down 的:
1 | # ip netns exec netns1 ping 127.0.0.1 |
再将环回口设置为 up 后,可以 ping 通本机环回地址:
1 | # ip netns exec netns1 ip link set lo up |
用户可以随意将虚拟网络设备分配到自定义的 Network namespace 里,但是连接真实硬件的物理设备则只能放在系统的根 Network namespace 中。任何一个网络设备最多只能存在于一个 namespace 里。
进程可以通过系统调用 clone()、unshare()、setns 进入 network namespace。
- 非 root 进程被分配到
network namespace后只能访问和配置已经存在于该network namespace的设备 - root 进程可以在
network namespace里创建新的网络设备。而且能把本network namepace的虚拟网络设备分配到其他network namespace中。操作可以是root namespace -> user namespace,反之亦可
例如如下命令 ip netns exec netns1 ip link set lo netns 1 将 netns1 中的 lo 设备挪到 PID 为 1(即 init 进程)所在的 Network namespace。通常 init 进程都在主机的根 Network namespace 下运行,因此就是移动到根 namespace 下。有两种方式索引 Network namespace:名字或者属于该 namespace 的进程 PID。
Network namespace API 使用
用户使用 clone() 系统调用来创建 namespace。但其实 clone() 系统调用来是用来创建一个新的进程的,它是 fork() 的延伸。clone() 系统调用通过 flags 参数来控制克隆进程时的行为:如果指定了 CLONE_NEW 标志,系统就会创建一个新的对应类型的 namespace 以及一个新的进程,并且会把这个进程放到这个新创建的 namespace 中。
clone() 系统调用接受如下参数:
- 函数指针
child_func:指定新进程执行的函数 - 指针
child_stack:传入子进程使用的栈空间 - int 累心给的 flags
- args:用户自定义参数
每个 Linux 进程都有属于自己的 /proc/PID/ns,该目录下的每个文件都代表一个类型的 namespace。从内核 3.8 版本开始,/proc/PID/ns 目录下的每个文件都是一个特殊的符号链接,我们可以通过查看这些符号链接确定两个进程是否在相同的 namespace 中。这些文件为操作进程所关联的 namespace 提供了一种方式。除此之外,/proc/PID/ns 目录下的文件还有一个作用,当打开这些文件,只要文件描述符是 open 状态,namespace 就会一直存在,即使该 namespace 下的所有进程都终止运行了。例如通过挂载 /proc/PID/ns 目录下的文件就能起到打开文件描述符的作用。
setns() 系统调用的主要功能就是把一个进程加入一个已经存在的 namespace 中。它接受如下参数:
- 参数 fd:表示进程待加入的 namespace 对应的文件描述符
- nstype:是否检查第一个参数 fd 所指向的 namespace 类型是否符合实际的要求
unshare() 系统调用用于帮助进程逃离 namespace。它的工作机制是:先通过指定的 flags 创建相应的 namespace,再把整这个进程挪到新创建的 namespace 中,于是就完成了:进程从原先的 namespace 的撤离。Linux 系统提供的 unshare 命令就是基于该系统调用,它的作用是在当前 shell 所在的 namespace 之外执行一条命令。
通过 Linux 的 Network namespace 技术可以自定义一个独立的网络栈,这使得 Linux network namespace 成为 Linux 网络虚拟化技术的基石。
veth pair
如果想让 Network namespace 与外界通信,仅有环回口是没用的。此时我们可以在创建一对 veth pair。veth 是虚拟以太网卡(Virtual Ethernet)的缩写。veth pair 总是成对出向且相互链接,它类似于 Linux 的双向管道,报文从 veth pair 一端进入,就会由另一端收到。根据这一特性,veth pair 常用于跨 network namespace 之间的通信,即分别将 veth pair 的两端放在不同的 namespace 里。
如下展示了如何创建 veth pair:
1 | ip link add veth0 type veth peer veth1 |
新创建的 veth pair 默认都在主机的根 Network namespace 中,且都是 DOWN 状态。创建的 veth pair 在主机上表现为两块网卡:
1 | [root@instance-qakp87fy ~]# ip -br link show |
如下将接口设置为 UP:
1 | # ip link set dev veth0 up |
veth pair 可以配置 IP 地址:
1 | ip addr add 10.0.0.1/24 dev veth0 |
设置 IP 地址后,两个 veth pair 设备可以互相 ping 通:
1 | # ping -I veth0 10.0.0.2 |
如果出现 ping 不通的问题,可能需要对 Linux 系统做额外设置,具体如下:
1 | # echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local |
之所以需要做这些设置,是因为 Linux 内核协议栈在收发包中有如下两个检查:
- 任何从非 looback 网卡进入的任何数据包的源地址不能是本机地址。通过将 accept_local 设置为 1 可以关闭该检查。loopback 接口收到的包没有该限制
- linux 反向过滤机制(rp_filter):对于每个进来的数据包,检查其方向路径是否是最佳路径,如果不是,则直接丢弃该数据包。通过将 rp_filter 设置为 1 可以关闭该检查
通过抓包,我们可以看到整个通信过程:
veth0 发送 ICMP request 报文:
1 | # tcpdump -n -i veth0 |
ICMP request 报文直接到达 veth1 上:
1 | # tcpdump -n -i veth1 |
ICMP reply 报文其实是走环回口发送的:
1 | # tcpdump -n -i lo icmp |
环回口发送的 ICMP reply 报文由直接回到内核协议栈,并返回给应用层程序。
容器与 host veth pair 的关系
经典的容器组网模型就是 veth pair + bridge 的模式。容器中的 eth0 和外面 host 上的某个 veth 是成对(pair)的关系。有几种方法可以知道 host 上的 vethXXX 与 container eth0 的对应关系:
- 在容器内查看
eth0的 iflink:cat /sys/class/net/eth0/iflink。然后在主机上遍历/sys/class/net下的全部目录,查看子目录的 ifindex 值。如果值相同,则代表这两个接口为一对veth pair - 另外执行
ip link show命令也可以通过@peer_interface_index展示对端 interface 的 index ethtool -S命令也可以列出对端 interface 的 index
Linux bridge
两个 Network namespace 可以通过 veth 连接起来,但是如果要连接多个 Network namespace,就要使用 Linux bridge 了。Linux bridge 是一台虚拟的网络交换机,任意真实的物理设备(例如主机网卡 eth0)和虚拟设备(例如 veth pair)都可以连接到 bridge 上。Linux bridge 有多个端口,进来之后从哪个口出去取决于目的 Mac 地址。
使用 ip 命令可以添加 bridge:
1 | # ip link add br0 type bridge |
另外也可以使用 bridge-utils 软件包中的 brctl 管理网桥:
1 | yum -y install bridge-utils |
1 | brctl addbr br0 |
Linux brige 和 veth pair
刚创建 Linux bridge 时,它只是一个独立的网络设备,只有一个端口连接着协议栈。接下来将之前创建的 veth pair 中的 veth0 连接到 bridge 上:
1 | # ip link set dev veth0 master br0 |
之后,可以看到 veth0 已经添加到 bridge 中了:
1 | # brctl show br0 |
此时再 ping veth0 的 10.0.0.1 已经不通了:
1 | # ping -I veth1 10.0.0.1 |
这是因为 veth0 已经连接到 br0 上,相当于交换机上的一个二层口,它收到的报文全部交给了 br0。这样协议栈无法正常地通过 veth0 实现互 ping。在交换机的二层口上配置 IP 地址是没有意义的,此时我们应该把 veth0 的地让给 Linux bridge,Linux bridge 本身也是一个网络设备,可以配置 IP 地址(可以认为 Linux brige 自带一块网卡,连接到 Linux brige 上)。
1 | # ip addr del 10.0.0.1/24 dev veth0 |
此时再 ping 就可以互通了(前提同样要设置 br0 的 accept_local 和 rp_filter):
1 | # ip addr add 10.0.0.1/24 dev br0 |
1 | # ping -I veth1 10.0.0.1 |
验证完成后,我们重新删除 Linux brige 的 IP 地址:
1 | # ip addr del 10.0.0.1/24 dev br0 |
将物理网卡添加到 Linux bridge 上
Linux 不会区分接入进来的到底是物理设备还是虚机设备,对它来说是没有区别的。将物理机的物理网卡 eth0 过程和 veth0 类似:
1 | # ip link set dev eth0 master br0 |
此时 eth0 上的 IP 地址已经没有意义,且无法通过该 eth0 ping 通网关地址。这时我们可以把 eth0 的地址配置到 br0 上,这样物理主机和外界的通信就不受影响。
1 | # ip addr del 192.168.64.8/20 dev eth0 |
由于 eth0 的 ip 地址被删除了,原来的默认路由被删除了,因此需要注意重新添加物理主机上的默认路由:
1 | # route add -net 0.0.0.0/0 gw 192.168.64.1 |
此时物理主机访问外网是没有问题的:
1 | # ping www.baidu.com |
Linux brige 在网络虚拟化中的应用
接下来介绍 Linux bridge 的两种常见部署方式,来说明其在现代网络虚拟化技术中的地位。
- 虚拟机:VM 通过 tun/tap 或者其他类似的虚拟网络设备,将虚拟机内的网卡通 br0 连接起来,VM 发出的报文首先到达 br0,br0 交给 eth0 发送出去。同一个物理机上的虚机通信,则直接通过 br0 进行转发。
- 容器:容器运行在自己单独的
Network namespace中,有自己独立的协议栈。因此其组网场景和虚拟机类似。但也存在一些差别。例如容器使用的是 veth pair 设备,而虚拟机则使用的是 tun/tap 设备。在虚拟机场景下,VM 一般和主机在同一个网段,而在容器场景下,容器和物理网络不在同一个网段内。此时可以通过 Linux 的 IP forward 功能(将 Linux 作为路由器),通过物理机的 eth0 发送出去,而且一般发送出去之前需要先做 NAT
网络接口的混杂模式
混杂模式(Promiscuous mode),简称 Promisc mode,是指网卡会把它所接收的所有网络流量都交给 CPU。在非混杂模式下,网卡只会接收目的 MAC 地址是它自己的单播帧、以及多播和广播帧。而在混杂模式下,网卡会接收所有经过它的真。
ifconfig eth0 promisc开启接口的混杂模式。ifconfig eth0 -promisc关闭接口的混杂模式
网络设备加入到 Linux bridge 后,会自动进入混杂模式。离开 Linux bridge 后,会自动退出混杂模式。
tun/tap 设备
从 Linux 文件系统的角度来看,tun/tap 是用户可以用文件句柄操作的字符设备。从网络虚拟化角度来看,它是虚拟网卡,一端连着用户态程序,另一端内核网络协议栈。tun/tap 设备可以将内核协议栈处理好的网络包发送给任何一个使用 tun/tap 驱动的进程,由进程重新处理后发送到物理链路。tun/tap 设备就相当于埋在用户空间的一个钩子,可以方便地将网络包的处理程序挂在这个钩子上。
tun/tap 设备其实就是利用 Linux 的设备文件实现内核态和用户态的数据交互。所有对设备文件的写操作,会通过 tun 设备转换成一个数据包传送给内核协议栈。当内核发送一个包给 tun 设备时,用户态的进程通过读取这个文件可以拿到该数据包。
tap 设备和 tun 设备的工作原理完全相同,区别在于:
- tun 设备的 /dev/tunX 文件收发的是 IP 包,只能工作在 L3,无法与物理网卡做桥接,但是可以通过三层路由(ip_forward)与物理网卡互通
- tap 设备的 /dev/tapX 文件收发的是链路层数据包,可以与物理网卡做桥接
如下展示了使用 tun 设备搭建一个基于 UDP 的 VPN:
- App1 是一个普通的程序,通过 Socket API 发送数据包,目的地址是隧道对端的地址
- 协议栈收到报文后,根据数据包的目的 IP 地址匹配到这个数据包应该由 tun0 网卡发送出去
- tun0 收到数据包后,App2 会得到通知(App2 始终读取对应 tun0 对应的设备文件)并读取数据包
- App2 完成报文封装,封装后的数据包外层目的地址为物理网段地址,发送到内核协议栈
- 内核协议栈根据路由规则,将报文通过 eth0 发送出去,最终数据包到达 VPN 对端
可以看出,报文需要经过网络协议栈两次,因此会有一定的性能损耗。
tun/tap 设备是理解 flannel 的基础,而 flannel 是一个重要的 Kubernetes 网络插件。如下是在 tun 的简单使用案例:
- 创建 tun 设备
1 | # ip tuntap add dev tun0 mod tun |
- 将 tun 设备 up 并设置 IP 地址
1 | # ip link set tun0 up |
iptables
iptables 在 Docker 和 Kubernetes 网络中应用很广。这里介绍 iptables 的基本工作机制。
netfilter
iptables 的底层实现是 netfilter。它作为一个通用的、抽象的框架,用于提供一整套 hook 函数的管理机制,使得包过滤、包处理、地址伪装、网络地址转换、透明代理、访问控制、基于协议类型的连接跟踪、甚至带宽限速成为可能。netfilter 的框架就是在整个网络流程的若干位置放置一些钩子,并在每个钩子上挂载一些处理函数进行处理。
netfilter 是 Linux 内核网络模块的一个经典框架,可以认为整个 Linux 系统的网络安全大厦都构建在 netfilter 之上。
table、chain 和 rule
iptables 是用户控件的一个程序,通过 netlink 和内核的 netfilter 框架打交道,负责往钩子上配置回调函数。掌握 iptables,重点需要了解其 5 条内置链,对应上文介绍的 netfilter 的 5 个钩子,这 5 条分别是:
- PREROUTING
- FORWARD
- POSTROUTING
- INPUT
- OUTPUT
除了系统预定义的 5 条 iptables 链,用户可以在表中自定义链。
另外,iptables 提供 5 张表。iptables 的表是用来分类管理 iptables 规则的。系统中所有的 iptables 规则都按照功能被划分到不同的表集合中。因为可以认为 iptables 表就是所有规则的逻辑集合。
- raw 表:iptables 是有状态的,即 iptables 可以对数据包进行连接跟踪(connection track),raw 则是用来去除该机制的
- mangle 表:用于修改数据包的 IP 头部信息
- nat 表:用于修改数据包的源和目的地址
- filter 表:用于控制到达某条链上的数据包是继续放行、丢弃(drop)或拒绝(reject)
- security 表:用于在数据包上应用 SELinux
这 5 张表的优先级从高到底,iptables 不支持用户自定义表。不是每个链上都能挂表。一条 iptables 规则包含 2 部分:匹配条件和动作。匹配条件即数据包的匹配规则,可以基于协议类型、源/目的ip、源/目的端口等。常见的动作则是对匹配的数据包所采取的行动:
- DROP:直接将数据包丢弃
- REJECT:给客户端返回一个
connection refused或destination unreachable - QUEUE:将数据包放入用户空间的队列
- RETURN:跳出当前链,该链后续的规则不再执行
- ACCEPT:同意数据包通过,继续执行后续规则
用户自定义链中的规则和系统预定义的 5 条链里的规则没有区别。由于自定义的链没有与 netfilter 里的钩子进行绑定,所以它不会自动触发,只能从其他链的规则中跳转过来(通过 JUMP)。
- 使用
iptables -L查看当前系统的 iptables 内容,默认查看的是 filter 表。 - 使用
-t可以指定表 - 使用
-n以数字形式列出信息(将域名解析为 IP 地址) - 使用
-v输出更详细的信息 - 使用
-A以添加方式在链中添加规则 - 使用
-F清除所有规则 - 使用
-D从指定 chain 中删除指定规则 - 使用
-X删除自定义链(系统内置链无法删除) - 使用
-N创建自定义链
iptables 中的每条链下面的规则处理顺序是从上到下逐条遍历的,除非中途碰到 DROP、REJECT、RETURN 等内置动作。如果 iptables 规则前面的动作是自定义链,则意味着该规则的动作是 JUMP,即跳到这条自定义链下遍历其所有规则,然后跳回遍历原来那条链后面的规则。
对 iptables 规则作出的改变是临时的,重启后就会丢失。如果想永久保存这些更改,可以使用 iptables-save 命令。后续使用 iptables-restore 恢复这些配置。
Linux 隧道:ipip
tun 设备也叫做点对点设备,经常用来实现隧道通道。Linux 原生支持一下 5 种 L3 隧道:
- ipip:即 IPv4 in IPv4,在一个 IPv4 报文中封装一个 IPv4 报文
- GRE:通用路由封装(Generic Routing Encapsulation),定义了在任意一种网络协议上封装其他任意一种网络协议的机制,适用于 IPv4 和 IPv6
- sit:和 ipip 类似,sit 用 IPv4 报文封装 IPv6 报文,即 IPv6 over IPv4
- ISATAP:站内自动隧道寻址协议(Intra-Site Automatic Tunnel Address Protocol),与 sit 类似,也用于 IPv6 over IPv4
- VTI(Virtual Tunnel Interface),是 Cisco 提出的一种 IPsec 隧道技术
测试 ipip 隧道
我们将搭建如下网络,用于测试 ipip 隧道:
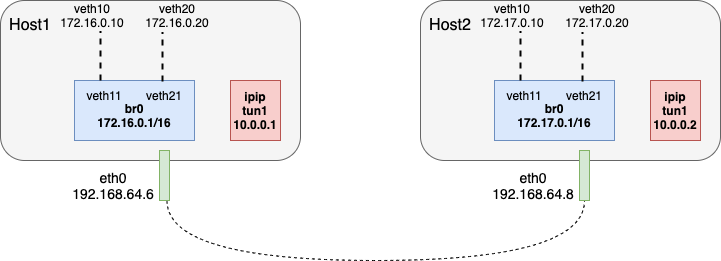
- 通过在 Host1 上使用 Linux bridge,模拟局域网1 172.16.0.0/16,网关为 br0 172.16.0.1
- 通过在 Host2 上使用 Linux bridge,模拟局域网2 172.17.0.0/16,网关为 br0 172.17.0.1
- 都通过 veth pair 来模拟局域网中的主机,veth pair 中的一端设置 IP 地址,另一端连接到 br0
- 两个局域网之间,通过 ipip 隧道互通,ipip 隧道内层地址分别为 10.0.0.1/30 和 10.0.0.2/30,外层使用物理机的物理网卡 eth0 通信
要使用 ipip 隧道,需要内核模块 ipip.ko 的支持,如果没有安装,可以使用 modprobe ipip 加载该内核模块。
1 | # lsmod | grep ipip |
Host0 配置 br0 和 veth:
1 | brctl addbr br0 |
Host1 上配置 br0 和 veth
1 | brctl addbr br0 |
完成以上配置之后,主机内的局域网的互 ping 是通的(通过 br0):
1 | # ping -I veth10 172.16.0.20 |
1 | # ping -I veth10 172.17.0.20 |
接下来 Host0 上创建 ipip 隧道:
1 | ip tunnel add tun1 mode ipip remote 192.168.64.8 local 192.168.64.6 |
在 Host1 上创建 ipip 隧道:
1 | ip tunnel add tun1 mode ipip remote 192.168.64.6 local 192.168.64.8 |
完成这两个步骤后,ipip 隧道端点之间互 ping 是通的:
1 | # ping -I tun1 10.0.0.2 |
1 | ping -I tun1 10.0.0.1 |
最后从 Host0 上的 172.16.0.10 ping Host1 上的 172.17.0.20:
1 | # ping -I 172.16.0.10 172.17.0.20 |
发现不通,这是因为物理机上没有相应的路由,我们在 Host0 上添加如下路由:目标网段为 172.17.0.0/0,出接口为 tun1
1 | route add -net 172.17.0.0/16 dev tun1 |
在 Host1 上添加如下路由:目标网段为 172.16.0.0/0,出接口为 tun0
1 | route add -net 172.16.0.0/16 dev tun1 |
之后 ping 就 OK 了:
1 | # ping -I 172.16.0.10 172.17.0.20 |
我们在 Host0 上抓包,看下这个 ipip 包的格式:

可以看到,内存的 icmp ping 报文被直接添加外层 IP 头后,转发到目的主机上。
这个例子其实并不一定非得通过 L3 隧道才能实现 Host0 和 Host1 上的虚拟局域网互通,因为 Host0 和 Host1 本身是直接互通的,中间不需要经过网关设备,所以直接在 Host0/Host1 上为 172.16.0.0/16 和 172.17.0.0/16 配置出接口为 eth0、下一跳为对端主机 IP 的路由即可实现互通。但是在需要经过网关设备,且目的网段无法发布到这些网关设备上时,就需要用到 L3 隧道了,例如这里的 ipip。
其他 L3 隧道实现方式与 ipip 隧道大同小异,底层实现都采用 tun 设备。
VXLAN
VxLAN(Virtual eXtensible LAN,虚拟可扩展的局域网),是一种虚拟化隧道通信技术,它是一种 overlay 技术,通过三层的网络搭建虚拟的二层网络。简单来说,VXLAN 是在底层物理网络(underlay)之上使用隧道技术,依托 UDP 层构建的 overlay 虚拟网络。虚拟网络与物理网络解耦,实现灵活的组网需求。VxLAN 这类的隧道网络对原有的网络架构影响小,不需要对原有网络做任何改动,就可以在原网络的基础上架设一层新的网络。
不同于其他隧道协议,VXLAN 是一个一对多的网络,一个 VXLAN 设备能通过像网桥一样进行动态学习,也可以直接配置静态转发表。VXLAN 技术解决了以下几个问题:
- VxLAN 使用 24bit 作为 VNI 区分不同的网络,相比于 VLAN 中的 12 bit(4096 个网络),支持的 overlay 网络个数大大提高
- 多租户隔离:使用 VNI 区分不同租户的网络
- 大二层:云计算环境下,虚机随时可能会迁移,需要保证被迁移的虚机其网络一直是可用的。因此租户虚拟网络一般需要是二层网络
VxLAN 在原有的 IP 网络(三层)上构建 overlay 的 二层网络,因此只要 underlay 网络三层可达的(能够通过 IP 相互通信),就能部署 VxLAN。VxLAN 网络中需要通过 VTEP(VxLAN Tunnel Endpoints) 设备实现 VxLAN 协议报文的封装/解封装。一个 underlay 网络上可以构建多个 overlay 网络,这些 overlay 网络相互隔离,通过 VNI 进行区分。
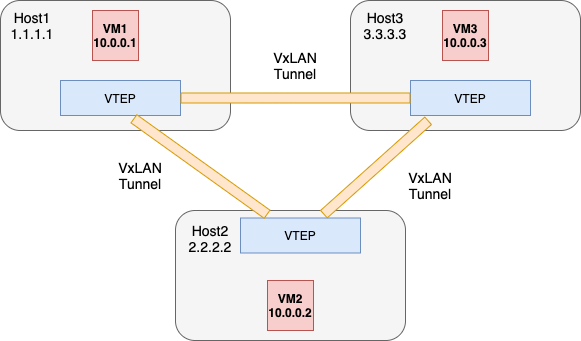
VxLAN 报文的就是 MAC in UDP,原始的二层帧会被添加 VxLAN 头部进行封装,之后再添加标准的 UDP 头部(使用 4789 作为端口),在 underlay 网络上进行传输(继续添加外层 IP 头和外层以太头)。
在使用 VxLAN 搭建虚拟二层网络时,overlay 的两个通信实体怎么实现二层通信的呢?如下所示,三个虚拟机分别分布在三个物理机上,VM1 要 ping 通 VM2 ,具体需要解决那些问题呢?
- VM1(10.0.0.1) 和 VM2(10.0.0.2) 由于在同一个 overlay 二层网络中,因此不需要经过网关转发。但是 VM1 并不知道 VM2 的 Mac 地址,这是需要解决的第一个问题
- 假设 VM1 知道了 VM2 的 Mac 地址后,VM1 报文到达 Host1 的 VTEP 后,如何知道报文是要送到 Host2 的 VTEP 呢?即怎么正确地填充外层 IP 头的目的 IP 地址呢?
要解决该问题,总体有 3 种思路:
- 自学习:类似于传统的二层交换机原理,VTEP 设备通过
泛洪-学习的过程,得知每个 Mac 地址所对应的目的 VTEP IP。对于 overlay 上的 ARP 请求等 BUM 流量,则发送到所有的对端 VTEP 上。当然由于 underlay 网络是个三层网络,这里可以使用 IP 组播优化 underlay 的通信,将两两的 IP 单播通信转换为 IP 组播。每个 VNI 对应一个多播组 - 控制面协议:通过控制面协议,实现 MAC/VTEP IP 映射关系的传递。该过程类似于路由协议传递 cidr 的过程,通过某种专有协议,在所有的 VTEP 之间传递
MAC/VTEP IP的映射关系。EVPN 就是这样的协议。 - 集中式控制器:集中式的控制器保存了所有 MAC/VTEP IP 的映射关系,直接将这些数据下发到 VTEP 中。Neutron 的 L2 population 就是这样工作的
VxLAN 实战
接下来我们将搭建如下的测试环境,Host0 和 Host1 上的 veth10 属于同一个 overlay 的虚拟局域网(172.16.0.0/16),Host0 和 Host1 上的 veth20 属于同一个 overlay 的虚拟局域网(172.17.0.0/16)。由于每个虚拟局域网分布在两个 Host 上,因此需要通过 vxlan 隧道实现互通。
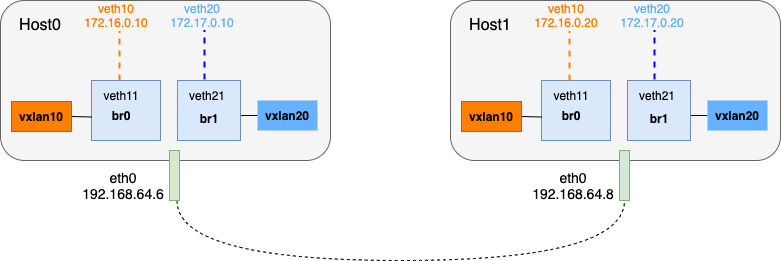
首先搭建 172.16.0.0/16 虚拟局域网:
- 在 Host0 上创建 veth pair:
1 | brctl addbr br0 |
- 在 Host1 上创建 veth pair:
1 | brctl addbr br0 |
- 分别在 Host0 和 Host1 上创建 vxlan10 隧道,并将其加入到 br0 上
Host0:
1 | ip link add vxlan10 type vxlan id 10 dstport 4789 local 192.168.64.6 remote 192.168.64.8 dev eth0 |
Host1:
1 | ip link add vxlan10 type vxlan id 10 dstport 4789 local 192.168.64.8 remote 192.168.64.6 dev eth0 |
这里目前我们只涉及两个物理主机,因此创建的 vxlan VTEP(即这里创建的 vxlan 接口) 直接使用 remote 参数来指定对端的 VTEP IP 地址。如果涉及多个物理主机,可以使用 group 参数来指定该 VXLAN 网络对应的多播组地址。这样 overlay 的广播流量就会发送到所有相关的 VTEP 机器上。但是代价是需要维护 underlay 的多播网络,会稍微复杂一些。
Host1 上配置 br0 和 veth
1 | brctl addbr br0 |
类似地,按照如下配置,完成第二个 overlay 网络的配置:
Host 0:
1 | brctl addbr br1 |
Host1:
1 | brctl addbr br1 |
之后,Host0 上的 veth20 和 Host1 上的 veth20 就可以正常通信:
1 | # ping -I veth20 172.17.0.20 |
vxlan 间路由
由于两个 vxlan 网络之间是相互隔离的,因此 Host0 上的 veth10 和 veth20 之间是无法相互通信:
1 | # ping -I veth10 172.17.0.20 |
两个 vxlan 网络需要通信,需要经过三层路由实现。这里我们引入第三台物理机,将其作为 vxlan 网络的路由器。
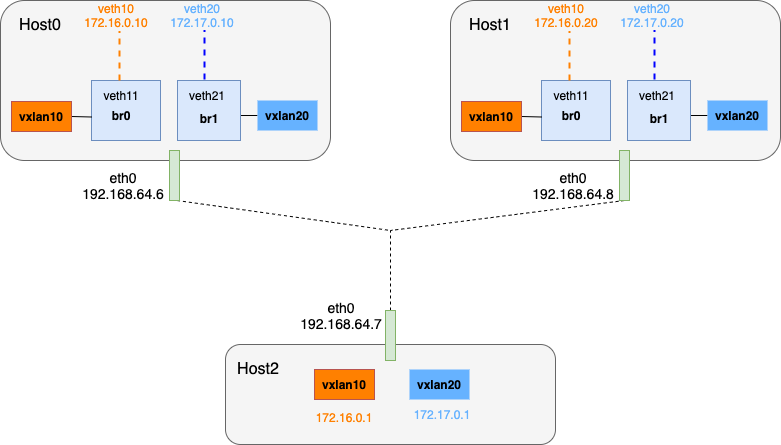
由于现在一个 vlxan 网路设计三台物理机,这里我们在创建 vxlan 接口时,使用多播组来实现 underlay 通信,即通过 group 参数来指定该 vxlan 网络所对应的多播网络。
修改 Host0 和 Host1 上的 vxlan10 和 vxlan20:
Host0:
1 | ip link del vxlan10 |
Host1:
1 | ip link del vxlan10 |
在 Host2 创建 vxlan 接口并设置 IP 地址,将其作为 vxlan 网络的网关地址:
1 | ip link add vxlan10 type vxlan id 10 dstport 4789 local 192.168.64.7 group 239.1.1.10 dev eth0 |
接下来需要同时在 Host0/Host1 上配置路由,如果我们直接配置网关路由,以 Host0 为例:
1 | route add -net 172.17.0.0/16 gw 172.16.0.1 |
这样 Host0 系统中就会同时存在直连路由和网关路由,且度量值一样,这样会对路由转发造成一些影响:
1 | # route -n |
这里我们要用到 Linux 的多路由表结合路由策略,来精准配置路由:
- 首先删除系统上 Host0 相关的 vxlan 路由:
1 | route del -net 172.16.0.0/16 dev veth10 |
- 之后添加路由:路由表 10 负责 vxlan10 网路的路由,路由表 20 负责 vxlan20 网络的路由:
1 | ip route add table 10 172.16.0.0/16 dev veth10 |
- 添加路由规则,指定源为
172.16.0.0/16的数据包,查找 table10 转发,源为172.17.0.0/16的数据包,查找 table 20 转发:
1 | ip rule add from 172.16.0.0/16 table 10 pref 10 |
- 类似地,在 Host1 上进行配置:
1 | route del -net 172.16.0.0/16 dev veth10 |
之后,从 Host0 上的 172.16.0.10/16 ping 172.17.0.20/16,可以 ping 通:
1 | # ping -I veth10 172.17.0.20 |
vlxlan 其他使用事项
- 可以使用
ip -d link show XXX查看某个某个 vxlan 接口的详细信息 - 在创建 Vxlan 接口时,也可以不使用
remote或group参数,此时我们可以手动修改 vxlan 接口的转发表(FDB 表):- 使用
bridge fdb show dev XXX查看某个 vxlan 端口的转发表 - 使用
bridge fdb to 92:47:a2:c2:21:f4 dst 192.168.64.8 dev vxlan10为 vxlan10 端口添加一条转发表项。该表项的含义是:目的 mac 地址是92:47:a2:c2:21:f4的二层转发包,通过 vxlan10 接口转发,对端的 VTEP IP 地址是192.168.64.8 - 使用
bridge fdb to 92:47:a2:c2:21:f4 dev vxlan10删除 vxlan10 端口上的转发表项 - 如果想在不使用多播的情况下把 overlay 的广播报文发送给所有的 VTEP 主机,此时可以手动添加多条默认的 FDB 表项:目的 Mac 地址是
00:00:00:00:00:00、dst 地址是每个对端 VTEP IP 地址。这样相当于手动维护一个多播组
- 使用
vxlan 转发表自学习机制,每次在转发未知单播目的 Mac 地址的数据包时,都需要对该数据包进行泛洪,这样需要发送大量的无用报文。如果提前知道 Mac 地址与所在 VTEP IP 地址的映射关系,就可以手动更新各个 VTEP 的 FDB 表项来减少广播包的数量。创建 vxlan 设备时指定 nolearning 参数,告诉 VTEP 不要通过收到的报文学习 FDB 表项。
上述方式可以减少由于未知单播流量而导致的广播报文,但是对于 ARP 请求等广播流量,并无法减少。其实 ARP 表项也是可以手动维护的。只要提前知道 overlay 网络上 IP 地址与 Mac 地址的对应关系。Linux 提供了一种解决方案,使用 VTEP 可以作为 ARP 代理,回复 ARP 请求。因此只要 VTEP 知道对应 IP 地址和 MAC 地址的映射关系,就可以直接作出 ARP 应答(在容器场景中也可以直接更新容器中的 ARP 表,但是开销太大,且容器会动态创建/删除)。创建 VTEP 时指定 proxy 参数,VTEP 就可以承担 ARP 代理。通过 ip neigh 命令在 vxlan 接口上添加 ARP表项。这样当 overlay 网络上发送 ARP 请求时,该 ARP 请求不需要广播,而是由本地 VTEP 直接作出应答。
通过手动方式维护 FDB 和 ARP 表项时,需要考虑一个问题。为了让所有 overlay 节点能够正常通信,就必须提前维护好所有 ARP 和 FDB 表项。但是并不是所有的 overlay 节点都需要相互通信,所以提前构造含所有表项是用不到的。Linux 提供了另外一种方法:内核发现需要的 ARP 或者 FDB 表项不存在时,会主动发送事件给应用程序。这样应用程序就可以实时更新所需要的表项,做到更精确的控制。
- L2(FDB)miss:如果目的 Mac 地址不是多播或广播地址,FDB 中没有该目的 Mac 地址的转发表项,且 FDB 中没有全零的表项,即默认规则,就会通知 L2 miss
- L3(ARP)miss:如果设备找不到对应 IP 需要的 MAC 地址时,就会通知 L3 miss 事件
在创建 VXLAN 接口时,通过指定 l2miss 和 l3miss 参数,可以开启功能。使用 ip monitor 命令可以监听某个网卡的事件。
VXLAN 协议给虚拟网络带来了灵活性和扩展性,让云计算网络能够像计算、存储资源那样按需扩展,并灵活分布。但是也带来了额外的复杂度和性能开销(每个 VXLAN 报文都需要有额外的头部、VXLAN 报文的封包和解包操作)。
多播实现很简单,不需要中心化的控制,但是需要 underlay 网络支持多播。仅仅依靠多播来实现 underlay 通信,可能会大致大量 BUM 流量出现在网络中。很多云计算的网络通过自动化的方式发现 VTEP 和 MAC 地址等信息。
Macvlan
最早的 docker 是不支持容器网络与宿主机网络直接互通的。从 Docker 1.12 版本开始,为了解决容器的跨主机通信问题,引入了 overlay 和 Macvlan 网络。其中 Macvlan 支持容器之间使用宿主机所在网段资源。
Macvlan 五大工作模式
通常在自定义 Docker 与外部网络通信的网络时会用到 NAT,还有 Linux bridge、Open vSwtich、Macvlan 几种选择。相比之下,Macvlan 拥有更好的性能。在 Macvlan 之前,可以通过网卡别名(eth0:1)的方式为一块以太网卡添加多个 IP 地址,但是无法为其添加多个 Mac 地址,因为以太网卡是以 Mac 地址为唯一标识。
Macvlan 接口可以看做是物理以太网接口的虚拟子接口,Macvlan 允许用户在主机的一个以太网络接口上配置多个虚拟的网络接口。每个 Macvlan 接口都有自己的、和父接口不同的 mac 地址,并且可以像普通网络接口一样分配 IP 地址。Macvlan 的主要用途是网络虚拟化。需要注意的是,使用 Macvlan 的虚拟机或容器网络与主机在同一个网段,即在同一个广播域中。
Macvlan 支持 5 种模式:
- bridge 模式:类似于 Linux bridge,是 Macvlan 最常用的模式。此时,拥有相同父接口的两块 Macvlan 虚拟网卡可以直接通信,不需要吧流量通过父接口发送到外部网络,广播帧将会被泛洪到连接在
网桥(并没有真实的网桥)上的所有子接口和物理接口。bridge 模式的缺点是:如果父接口故障,所有 Macvlan 子接口会跟着故障,子接口也将无法通信 - VEPA(Virtual Ethernet Port Aggregator):它是默认模式,所有从 Macvlan 接口发出的流量不管目的地址是什么,全部发送给父接口。在二层网络中,由于生成树协议的原因,两个 Macvlan 接口之间的通信会被阻塞,这是就需要所接入的外部交换机支持 hairpin(所谓 hairpin mode,是指允许网络设备从一个端口收到包后,回包仍从原端口发出),把源和目的地址都是本地 Macvlan 接口地址的刘爱玲,发送给相应的接口。Linux 网桥支持配置 hairpin 模式,命令为
brctl hairpin <bridge> <port> {on|off}。如果想在物理交换机层面对虚拟机或容器之间的访问流量进行优化设定,VEPA 模式是一种比较好的选择。 - Private 模式类似于 VEPA 模式,但是又增强了 VEPA 模式的隔离能力,其完全阻止共享同一父接口的 Macvlan 虚拟网卡之间通信。即使配置了 hairpin,让从父接口发出的流量返回宿主机,相应的通信流量依然被丢弃。它的实现方式是丢弃广播/多播数据,因此 ARP 解析过程将无法工作。
- Passthru 模式:即直通模式,每个父接口只能和一个 Macvlan 网卡捆绑,并且 Macvlan 网卡继承父接口的 Mac 地址。
- Source 模式:此时寄生在物理设备上的 Macvlan 设备之鞥呢接收指定源 Mac 地址的数据包,其他数据包一概丢弃
另外,需要注意,在 Macvlan 虚拟网络世界中,物理网卡相当于一个交换机,对于进出其子 Macvlan 网卡的数据包,物理网卡只能转发数据包而不处理数据包。这也就造成了使用本机 Macvlan 网卡的 IP 无法和物理网卡的 IP 通信。所以 Macvlan 只为虚拟机或容器提供访问外部物理网络的连接。
Macvlan 实战
- 创建两个 network namespace
1 | ip netns add ns1 |
- 在宿主机上创建 Macvlan 设备,并将设备状态设置为 up
1 | ip link add eth0.1 link eth0 type macvlan mode bridge |
- 为两个 Macvlan 网卡设置 IP 地址
1 | ip -n ns1 addr add 192.168.64.11/24 dev eth0.1 |
此时 Macvlan 网卡之间互 ping 是能通的:
1 | # ip netns exec ns1 ping 192.168.64.12 |
但是 ping 物理网卡是不通的:
1 | # ip netns exec ns1 ping 192.168.64.8 |
Macvlan 小结
Macvlan 是将虚拟机或者容器通过二层该连接到物理网络的一个不错方案,但是也存在局限性:每个虚拟网卡都有自己的 IP 地址,所以 macvlan 需要大量的 Mac 地址。而 Linux 主机练级的交换机可能会限制一个物理端口的 Mac 地址数量上限。而且很多物理网卡的 Mac 地址数量本身也有限制,超过这个限制可能会影响到系统的性能
IPvlan
与 Macvlan 类似,IPvlan 也是从一个主机接口虚拟出多个虚拟网络接口。区别在于 IPvlan 所有虚拟接口都有相同的 Mac 地址,而 IP 地址却各不相同(此时特别需要注意 DHCP 使用的场景,可能需要配置唯一的 Client ID 来动态获取 IP 地址)。
IPvlan 有两种不同的模式,分别是 L2 和 L3 模式。一个父接口只能选择其中一种模式,依附于它的所有子虚拟接口都运行在该模式下。
- IPvlan L2 模式和 Macvlan bridge 模式的工作原理相似,父接口作为交换机转发子接口的数据,同一个网络的子接口通过父接口转发数据,如果想发送到其他网络,则报文回通过父接口的路由发送出去
- IPvlan L3 模式中,IPvlan 有点像路由器的功能,IPvlan 在各个虚拟网络和主机网路之间进行不同网络报文的路由转发工作。只要父接口相同,即使虚拟机/容器网络在不同的网络,也可以相互通信。IPvlan 会在中间做报文转发工作。L3 模式下虚拟接口不会接收多播或者广播的报文,所有的 ARP 过程或者其他多播报文都是在底层的父接口完成的
IPvlan 实战
由于 IPvlan 的 L2 模式和 Macvlan 功能相同,这里主要测试其 L3 模式。
- 创建两个 network namespace
1 | ip netns add ns1 |
- 创建两个 ipvlan 接口
1 | ip link add ipv1 link eth0 type ipvlan mode l3 |
- 为 ipvlan 接口配置不同的 IP 地址,并配置好路由项:
1 | ip -n ns1 addr add 10.0.10.1/24 dev ipv1 |
- 两个 IPvlan 接口通信正常:
1 | # ip netns exec ns1 ping 10.0.20.1 |
IPvlan 可以解决 Macvlan 中 Mac 地址过多的问题,而且还允许用户基于 IPvlan 搭建比较复杂的网络拓扑。不再基于 Macvlan 的简单二层网络,而是能够与 BGP 等协议扩展我们的网络边界。
Reference
分析“关于Linux内核引入的accept_local参数的一个问题”
Linux 云计算网络
动态维护FDB表项实现VXLAN通信