Python 从 ABC 语言继承了对序列的统一处理方式。字符串、列表、字节序列、数组、XML 元素和数据库查询结果,这些序列在操作上有很多共通之处,都可以迭代、切片、排序和拼接。深入理解 Python 中不同的序列类型,不但能避免重新发明轮子,还可以从它们共通的接口上受到启发,在自己实现 API 时合理支持及利用现有和将来可能添加的序列类型。
内置序列类型概览
Python 标准库用 C 语言实现了丰富的序列类型,列举如下:
- 容器序列:可存放不同类型的项,其中包括嵌套容器。示例:list、tuple 和 collections.deque
- 扁平序列:可存放一种简单类型的项。示例:str、bytes 和 array.array
容器序列存放的是所包含对象的引用,对象可以是任何类型。扁平序列 在自己的内存空间中存储所含内容的值,而不是各自不同的 Python 对象。下图展示了这种区别,可以看到,扁平序列更加紧凑,但是只能存放原始机器值,例如字节、整数和浮点数
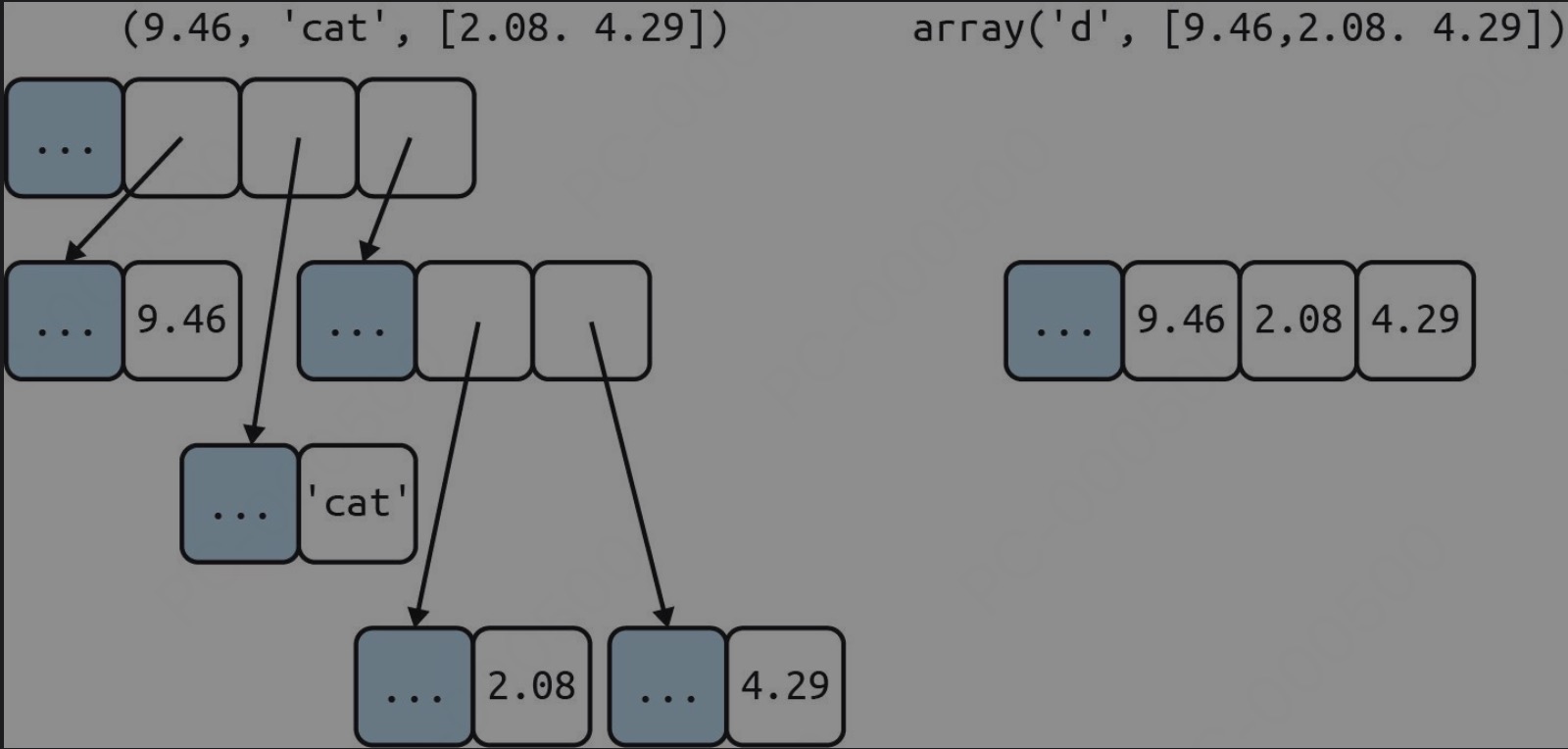
任何 Python 对象在内存中都有一个包含元数据的标头(上图中的灰色方块)。最简单的 Python 对象,例如一个 float,内存标头中有一个值字段和两个元数据字段。
- ob_refcnt:对象的引用计数
- ob_type:指向对象类型的指针
- ob_fval:一个 C 语言 double 类型值,存放 float 的值
假如有一个浮点数数组和一个浮点数元组,显然前者比后者更紧凑,因为数组整体是一个对象,存放各个浮点数的原始值,而元组由多个对象构成:元组自身和存放的各个 float 对象。
另外,还可按可变性对序列类型分类:
- 可变序列:例如 list、bytearray、array.array和collections.deque
- 不可变序列:例如 tuple、str 和 bytes
可变序列继承不可变序列的所有方法,另外还多实现了几个方法。记住不同序列类型的共同点:有些是可变的,有些是不可变的;有些是容器,有些是扁平的。这有助于你把相关概念延伸到不太熟悉的序列类型上。
list 是最基本的序列类型,是一种可变容器。接下来将介绍列表推导式和生成器表达式。
列表推导式和生成器表达式
使用列表推导式(目标是列表)或生成器表达式(目标是其他序列类型)可以快速构建一个序列。很多 Python 程序员把列表推导式简称为 listcomps,把生成器表达式简称为 genexps。
列表推导式
如下代码基于一个字符串构建一个 Unicode 码点列表:
1 | symbols = 'abcdefg' |
可以看到,使用列表推导式更易于理解,其意图是明确的。当然列表推导式应保持简短。如果超过两行,那么最好把语句拆开。如果你不打算使用生成的列表,那就不要使用列表推导式句法。
Python 会忽略[]、{} 和 () 内部的换行。因此,列表、列表推导式、元组、字典等结构完全可以分成几行来写,无须使用续行转义符 \。另外,使用这 3 种括号定义字面量时,项与项之间使用逗号分隔,末尾的逗号将被忽略。因此,跨多行定义列表字面量时,最好在最后一项后面添加一个逗号。这样不仅能方便其他程序员为列表添加更多项,还可以减少代码差异给阅读带来的干扰。
Python3 中的列表推导式、生成器表达式,以及类似的集合推导式和字典推导式,for 子句中赋值的变量在局部作用域内。然而,使用 海象运算符 := 赋值的变量在推导式或生成器表达式返回后依然可以访问,这与函数内的局部变量行为不同。
1 | x = "ABC" |
列表推导式涵盖 map 和 filter 两个函数的功能,但写出的代码不像 Python 的 lambda 表达式那样晦涩难懂。
1 | symbols = '$¢£¥€¤' |
如下使用列表推导式计算笛卡尔乘积:
1 | colors = ['r', 'g', 'b'] |
可以看到,[(c, s) for c in colors for s in size] 中是先按照 color,再按 size 进行排列,等同于:
1 | for c in colors: |
列表推导式的作用很单一,就是构建列表。如果想生成其他类型的序列,则应当使用生成器表达式。
生成器表达式
虽然列表推导式也可以生成元组、数组或其他类型的序列,但是生成器表达式占用的内存更少,因为生成器表达式使用迭代器协议逐个产出项,而不是构建整个列表提供给其他构造函数。生成器表达式的句法跟列表推导式几乎一样,只不过把方括号换成圆括号而已。
1 | symbols = "abcdefg" |
- 如果生成器表达式是函数唯一的参数,则不需要额外再使用圆括号括起来
- array 构造函数接受两个参数,因此必须在生成器表达式两侧加上圆括号
- array 构造函数的第一个参数指定数组中数值的存储类型
如下代码使用使用生成器表达式,一次产出一项,提供给 for 循环。如果是两个各有 1000 项的列表,则使用生成器表达式计算笛卡儿积可以节省大量内存,因为不用先构建一个包含 100 万项的列表提供给 for 循环。
1 | colors = ['r', 'g', 'b'] |
元组不仅仅是不可变列表
元组有两个作用,除了可以作为不可变列表使用之外,还可用作没有字段名称的记录。用元组存放记录,元组中的一项对应一个字段的数据,项的位置决定数据的意义。
1 | positions = [(1, 2), (3, 4), (5, 6)] |
- 可以看到,% 格式化运算符理解元组结构,把每一项当作不同的字段
- for 循环知道如何获取元组中单独的每一项,这叫
拆包。这里我们对第二项不感兴趣,因此把它赋值给虚拟变量_(习惯用法)
通常没必要为了给字段指定一个名称而创建一个类。如果不使用索引访问字段,而只使用拆包,那就更没有必要了。当然对于拆包,内容不局限于元组,也涉及序列和一般意义上的可迭代对象。
Python 解释器和标准库经常把元组当作不可变列表使用,你也可以。这么做主要有两个好处:
- 意图清晰:只要在源码中见到元组,你就知道它的长度永不可变
- 性能优越:长度相同的元组和列表,元组占用的内存更少,而且 Python 可对元组做些优化
元组的不可变性仅针对元组中的引用而言。元组中的引用不可删除、不可替换。倘若引用的是可变对象,改动对象之后,元组的值也会随之变化。
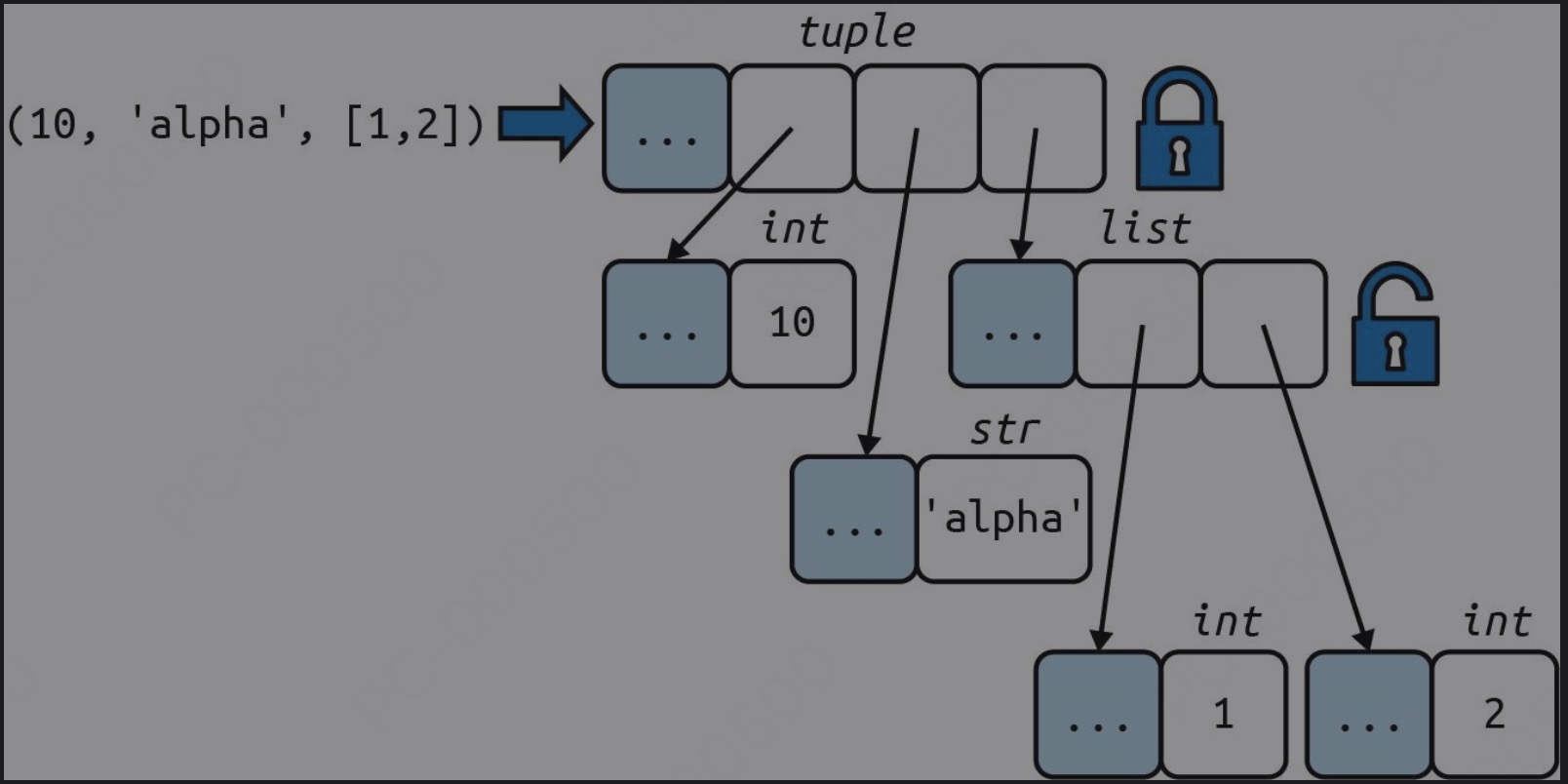
元组的内容自身是不可变的,但是这仅仅表明元组中存放的引用始终指向同一批对象。倘若引用的是可变对象,例如一个列表,那么元组的值就可能发生变化:
1 | a = (10, "alpha", [1, 2]) |
存放可变项的元组可能导致 bug。后面会介绍,只有值永不可变的对象才是可哈希的。不可哈希的元组不能作为字典的键,也不能作为集合的元素。如果你想显式判断一个元组(或其他对象)的值是否固定,则可以使用内置函数 hash 定义如下所示的 fixed 函数:
1 | """ |
尽管如此,元组依然广泛用作不可变列表。相比于 list,元组的性能更好一些。把元组当作列表的不可变变体使用时,有必要了解二者 API 之间的异同。元组支持所有不涉及增删项的列表方法。
另外说一下,列表可以包含不同类型的对象,但是在实践中,这样做没有什么用。我们把一些项放在列表中,是为了后续处理,这就隐含了一层意思,即所有项至少都应该支持同一种操作。与列表不同,元组通常包含不同类型的项。这也符合常理:如果元组中的每一项都是一个字段,那么每个字段就可以具有不同的类型。
序列和可迭代对象拆包
拆包的特点是不用我们自己动手通过索引从序列中提取元素,这样就减少了出错的可能。拆包的目标可以是任何可迭代对象,包括不支持索引表示法([])的迭代器。最明显的拆包形式是并行赋值(parallel assignment),即把可迭代对象中的项赋值给变量元组:
1 | x, y = (1, 2) |
利用拆包还可以轻松对调两个变量的值,省掉中间的临时变量。
1 | x, y = y, x |
调用函数时在参数前面加上一个,利用的也是拆包*。
1 | divmod(20, 8) |
拆包的另一个用途:为函数返回多个值提供一种便于调用方使用的方式。
1 | import os |
如果只需要拆包得到的部分项,那么可以使用 * 语法。我们知道,定义函数时可以使用 *args 捕获余下的任意数量的参数。Python 3 把这一思想延伸到了并行赋值上。并行赋值时,* 前缀只能应用到一个变量上,不过可以是任何位置上的变量。
1 | a, b, *rest = range(5) |
在函数调用中,可以使用多次 *,定义列表、元组或集合字面量时,也可以使用 *
1 | a, b, c, d |
1 | *range(3), 4 |
最后,元组拆包的一个强大功能是可以处理嵌套结构。拆包的对象可以嵌套,例如(a, b, (c, d))。如果值的嵌套结构是相同的,则 Python 能正确处理。
1 | (a, b, (c, *d)) = (1, 2, (3, 4, 5)) |
拆包赋值的对象也可以是一个列表,不过用途不大。只有一种情况用得到,返回的结果是只包含一个元素的的序列,通过拆包确保只返回一个结果:
1 | a |
当然也可以使用元组,但是句法有点怪异,元组中唯一的项后面要加一个逗号。如果忘记末尾的逗号,将埋下不易察觉的 bug:
1 | (a) = [1] |
序列模式匹配
Python3.10 最引人注目的新功能之一是 match/case 语句实现的模式匹配。如下是一个例子,假设你在设计一个机器人,它接受以文字和数值序列形式发送的命令,例如 BEEPER 440 3。经过拆分和解析之后,得到消息 ['BEEPER', 440, 3],使用如下代码,可以处理这样的消息:
1 | def handle_command(self, message): |
match 关键字后面的表达式是匹配对象(subject),即各个 case 子句中的模式尝试匹配的数据。当执行匹配时,会从第一个 case 开始,依次检查模式是否匹配(值的匹配、项数的匹配)。
表面上看,match/case 与 C 语言中的 switch/case 语句很像,但这只是表象。与 switch 相比,match 的一大改进是支持析构,这是一种高级拆包形式:
1 | metro_areas = [ |
这个 match 的匹配对象是 record,即 metro_areas 中的各个元组。但是 case 子句一部分是模式,另一部分是使用 if 关键字指定的卫语句(guard clause,可选)。在这个例子中,嵌套块中的 print 语句仅当匹配模式且卫语句为真时才运行。
一般来说,匹配对象同时满足以下条件方能匹配序列模式:
- 匹配对象是序列
- 匹配对象和模式的项数相等
- 对应的项相互匹配,包括嵌套的项
序列模式可以写成元组或列表,或者任意形式的嵌套元组和列表,使用哪种句法都没有区别,因为在序列模式中,方括号和圆括号的意思是一样的。序列模式可以匹配 collections.abc.Sequence 的多数实际子类或虚拟子类的实例,但 str、bytes 和 bytearray 除外。因为在 match/case 上下文中,str、bytes 和 bytearray 实例不作为序列处理,match 把这些类型视为 原子 值,即一个整体值,而不是序列。如果想把这些类型的对象视为序列,则要在 match 子句中转换,例如使用 match tuple(phone)。
标准库中的以下类型与序列模式兼容:
1 | list memoryview array.array |
有一些注意事项:
- 与拆包不同,模式不析构序列以外的可迭代对象(例如迭代器)。
_符号在模式中有特殊意义:匹配相应位置上的任何一项,但不绑定匹配项的值- 另外,
_是唯一可在模式中多次出现的变量 - 模式中的任何一部分均可使用as关键字绑定到变量上,例如
case [name, _, _, (lat, lon) as coord]: - 添加类型信息可以让模式更具体。例如,下面的模式与前面的示例匹配相同的嵌套序列结构,不过第一项必须是str 实例,而且二元组中的两项必须是 float 实例。
str(name)这种语法在模式上下文中,其作用是在运行时检查类型。
1 | case [str(name), _, _, (float(lat), float(lon))]: |
- 如果想要匹配任何以字符串开头、以嵌套两个浮点数的序列结尾的序列,则可以使用如下模式。
*_匹配任意数量的项,而且不绑定变量,如果把*_换成*extra,匹配的零项或多项将作为列表绑定到 extra 变量上。
1 | case [str(name), *_, (float(lat), float(lon))]: |
- 以 if 开头的卫语句是可选的,仅当匹配模式时才运行,卫语句可以引用模式中绑定的变量
- 在序列模式中,一个序列中只能有一个
*。如下匹配对象是合法的,因为外层一个,内层一个:
1 | case ['lambda', [*parms], *body] if body: |
- 如下模式中,表示第二项必须是 Symbol 类的实例
1 | case ['define', Symbol() as name, value_exp] |
通过序列模式匹配,你可以编写出更简洁、更易读的代码。模式匹配是一种声明式编程风格,即描述你想匹配什么,而不是如何匹配,这样写出的代码结构与数据结构是一致的。
切片
在 Python 中,列表、元组、字符串等所有序列类型都支持切片操作。切片比多数人认为的要强大很多。在切片、区间操作中排除最后一项是一种 Python 风格约定,这与很多其他语言中从零开始的索引相匹配。排除最后一项可以带来以下好处:
- 在仅指定停止位置时,容易判断切片或区间的长度
- 同时指定起始和停止位置时,容易计算切片或区间的长度,做个减法即可
- 方便在索引 x 处把一个序列拆分成两部分而不产生重叠,直接使用
my_list[:x]和my_list[x:]即可
切片操作 s[start:stop:step] 中 step 指定步距,让切片操作跳过部分项。步距也可以是负数,反向返回项:
1 | s = "abcdefg" |
a:b:c 表示法只在 [] 内部有效,表示索引或下标运算符,得到的结果是一个切片对象。为了求解表达式seq[start:stop:step],Python调用 seq.__getitem__(slice(start, stop, step))。我们可以给切片命名,以提供更好的代码可读性:
1 | text="jack 15 master" |
[] 运算符还可以接受多个索引或切片,以逗号分隔。负责处理 [] 运算符的特殊方法 __getitem__ 和 __setitem__ 把接收到的 a[i, j] 中的索引当作元组。也就是说,为了求解 a[i, j],Python调用 a.__getitem__((i, j))。例如 NumPy 包中,numpy.ndarray 表示的二维数组可以使用 a[i, j] 句法获取数组中的元素,还可以使用表达式 a[m:n, k:l] 获取二维切片。除了 memoryview 之外,Python 内置的序列类型都是一维的,因此只支持一个索引或切片,不支持索引或切片元组。
省略号写作 3 个句点 ...,Python 解析器把它识别为一个记号。省略号是 Ellipsis 对象的别名,而 Ellipsis 对象是 ellipsis 类的单例。因此,你可以把省略号作为参数传给函数,也可以写在切片规范中。存在这种句法是为了给用户定义的类型和扩展(例如 NumPy)提供支持,例如,对 Numpy 四维数组 x,x[i, ...] 是 x[i, :, :, :,] 的快捷句法。
切片不仅可从序列中提取信息,还可以就地更改可变序列,即不重新构建序列。在赋值语句的左侧使用切片表示法,或者作为 del 语句的目标,可以就地移植、切除或以其他方式修改可变序列。需要注意,如果赋值目标是一个切片,则右边必须是一个可迭代对象,即使只有一项。
1 | l = [i for i in range(10)] |
使用 + 和 * 处理序列
序列支持 + 和 *。通常,+ 的两个运算对象必须是同一种序列,而且都不可修改,拼接的结果是一个同类型的新序列。如果想多次拼接同一个序列,可以乘以一个整数。同样,结果是一个新创建的序列。
1 | [1, 2, 3] + [1, 2, 3] |
+ 和 * 始终创建一个新对象,绝不更改操作数。注意 a * n 这种表达式,如果序列 a 中包含可变项,则结果可能出乎意料。例如,使用 my_list = [[]] * 3 初始化一个嵌套列表,得到的结果是一个列表没错,但是嵌套的 3 个引用指向同一个列表,而你或许并不希望如此。
1 | x = [['_'] * 3 for i in range(3)] |
第二种用法中,外层列表内部的 3 个引用指向同一个列表,因此修改了其中一个元素也会影响到其他元素。这种问题的原因如同如下代码,它将同一个 row 向 board 中追加 3 次:
1 | row = ['_'] * 3 |
也可以使用增量赋值运算符处理序列,根据第一个操作数而定,增量赋值运算符 += 的行为差异较大。背后支持 += 运算符的是特殊方法 __iadd__(就地相加)。对于 a += b:
- 如果 a 实现了
__iadd__,那就调用它 - 如果 a 是可变序列(例如,list、bytearray、array.array),则就地修改 a
- 倘若 a 没有实现
__iadd__方法,表达式a += b的作用等同于a = a + b,先求解表达式a + b,再把得到的新对象绑定到 a 上
a 绑定的对象身份可能变了,也可能没变,这取决于有没有实现 __iadd__ 方法。通常,对于可变序列,最好实现 __iadd__ 方法,而且 += 运算符就地修改。对于不可变序列,显然不能就地修改。如下以 *= 为例:
1 | l = [1, 2, 3] |
再来看一个例子:
1 | t = (1, 2, [3, 4]) |
这个例子 t[2] 被修改是容易理解的,但为什么又抛出错误呢,因为执行 t[2] += [5, 6] 就地修改列表对象后,还是要把列表对象重新赋值到 t[2],由于元组是不可变对象,因此操作失败。从这个例子,吸取了 3 个教训:
- 不要在元组中存放可变的项
- 增量赋值不是原子操作,这一点刚刚见识到,部分操作执行完毕后又抛出了异常。
- 检查 Python 字节码并不太难,从中可以看出 Python 在背后做了什么
1 | dis.dis('s[a] += b') |
list.sort 与内置函数 sorted
list.sort 方法就地排序列表,即不创建副本,返回值为 None,目的就是提醒我们,它更改了接收者,没有创建新列表。这是 Python API 的一个重要约定:就地更改对象的函数或方法应该返回 None,让调用方清楚地知道接收者已被更改。但是这种方式也有缺点,这种方法不能级联调用。相反,返回新对象的方法(例如,str的所有方法)可以在流式接口(fluent interface)风格中级联调用。
与之相反,内置函数 sorted 返回创建的新列表。该函数接受任何可迭代对象作为参数,包括不可变序列和生成器。无论传入什么类型的可迭代对象,sorted 函数始终返回新创建的列表。
而且 Python 的排序算法是稳定的(即能够保留比较时相等的两项的相对顺序)。这两个函数都接收可选的关键字参数:
- reverse:值为 True 时,降序返回项
- key:一个只接受一个参数的函数,应用到每一项上,作为排序依据
当列表不适用时
list 类型简单灵活,不过,针对具体的需求,或许还有更好的选择。例如,使用数组处理上百万个浮点值可以节省大量内存。另外,如果经常需要在列表的两端添加和删除项,使用 deque(double-ended queue,双端队列)更合适,这是一种更高效的 FIFO 数据结构。如果你在代码中经常检查容器中是否存在某一项,应考虑使用 set 类型存储。
数组
如果一个列表只包含数值,那么使用 array.array 会更高效。数组支持所有可变序列操作(包括 .pop、.insert 和 .extend,此外还有快速加载项和保存项的方法,例如 .frombytes、.tofile。
Python 数组像 C 语言数组一样精简。一个由 float 值构成的数组,存放的并不是完整的 float 对象,而是表示相应机器值的压缩字节,,与 C 语言中由 double 值构成的数组如出一辙。创建 array 对象时要提供类型代码,它是一个字母,用来确定底层使用什么 C 类型存储数组中各项。
1 | from array import array |
如果想使用数值数组表示二进制数据,Python有专门的类型:bytes 和 bytearray。
memoryview
内置的 memoryview 类是一种共享内存的序列类型,可在不复制字节的情况下处理数组的切片。memoryview 在数据结构之间共享内存,而不是事先复制。这对大型数据集来说非常重要。
memoryview.cast 方法使用的表示法与 array 模块类似,作用是改变读写多字节单元的方式,无须移动位。memoryview.cast 方法返回另一个 memoryview 对象,而且始终共享内存。
1 | from array import array |
Numpy
如果你想对数组做一些高级数值处理,应该使用 NumPy 库。科学计算经常需要做一些高级数组和矩阵运算,得益于 NumPy,Python 成为这一领域的主流语言。NumPy 实现了多维同构数组和矩阵类型,除了存放数值之外,还可以存放用户定义的记录,而且提供了高效的元素层面操作。
1 | import numpy as np |
NumPy 还支持一些高级操作,例如加载、保存和操作 numpy.ndarray 对象的所有元素。在 NumPy 基础之上编写的 SciPy 库提供了许多科学计算算法,NumPy 和 SciPy 这两个库的功能异常强大,为很多优秀的工具提供了坚实的基础,例如 Pandas 和 scikit-learn。
至此我们已经讲了两种扁平序列:标准数组 和 NumPy 数组。
双端队列和其他队列
借助 .append 和 .pop 方法,列表可以当作栈或队列使用(.append 和 .pop(0) 实现的是先进先出行为)。但是,在列表头部(索引位为 0)插入和删除项有一定开销,因为整个列表必须在内存中移动。collections.deque 类实现一种线程安全的双端队列,旨在快速在两端插入和删除项。如果需要保留 最后几项,或者实现类似的行为,则双端队列是唯一选择,因为 deque 对象可以有界,即长度固定。有界的 deque 对象填满之后,从一端添加新项,将从另一端丢弃一项。
1 | from collections import deque |
deque 实现了多数 list 方法,另外增加了一些专用方法,例如 popleft 和 rotate。不过,这里隐藏一个不太高效的操作:从 deque 对象中部删除项的速度不快。双端队列优化的是在两端增减项的操作。append 和popleft 是原子操作,因此你可以放心地在多线程应用中把 deque 作为先进先出队列使用,无须加锁。
除了 deque 之外,Python 标准库中的其他包还实现了以下队列:
- queue:提供几个同步(即线程安全)队列类:SimpleQueue、Queue、LifoQueue和 PriorityQueue
- multiprocessing:单独实现了无界的 SimpleQueue 和有界的 Queue。这与 queue 包中的队列类非常相似,只不过专门针对进程间通信
- asyncio:提供了 Queue、LifoQueue、PriorityQueue 和 JoinableQueue,为管理异步编程任务而做了修改
- heapq:提供了 heappush 和 heappop 等函数,可把可变序列当作堆队列或优先级队列使用
小结
若想写出简洁、有效和地道的 Python 代码,势必要掌握标准库中的各种序列类型。