迭代是数据处理的基石:程序将计算应用于数据序列。如果数据在内存中放不下,则需要惰性获取数据项,即按需一次获取一项,这就是迭代器的作用。
我们将实现一个 Sentence 类,以此开启探索可迭代对象的旅程。向这个类的构造函数传入包含一些文本的字符串,然后便可以逐个单词迭代。如下代码实现了序列协议,这个类的对象可以迭代,因为所有序列都可迭代:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import reimport reprlibRE_WORD = re.compile (r'\w+' ) class Sentence : def __init__ (self, text ): self.text = text self.words = RE_WORD.findall(text) def __getitem__ (self, index ): return self.words[index] def __len__ (self ): return len (self.words) def __repr__ (self ): return 'Sentence(%s)' % reprlib.repr (self.text)
因为 Sentence 实现了序列协议,因此是可以迭代的。而且正因为实现了序列协议,因此支持索引操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 >>> s = Sentence("word hard and you will succeed" )>>> for w in s:... w... 'word' 'hard' 'and' 'you' 'will' 'succeed' >>> s[2 ]'and'
需要迭代对象 x 时,Python 自动调用 iter(x)。内置函数 iter 执行以下操作:
检查对象是否实现了 __iter__ 方法,如果实现了就调用它,获取一个迭代器
如果没有实现 __iter__ 方法,但是实现了 __getitem__ 方法,那么 iter() 创建一个迭代器,尝试按索引(从 0 开始)获取项。Python 的迭代机制以从 0 开始的索引调用 __getitem__ 方法,没有剩余项时抛出 IndexError
如果尝试失败,则 Python 抛出 TypeError 异常,通常会提示 'C' object is not iterable(C对象不可迭代),其中 C 是目标对象所属的类
所有 Python 序列都可迭代的原因是,按照定义,序列都实现了 __getitem__ 方法。其实,标准的序列也都实现了 __iter__ 方法,因此你也应该这么做。之所以能通过 __getitem__ 方法迭代,是为了向后兼容,而未来可能不会再这么做。
从 Python3.10 开始,检查对象 x 能否迭代,最准确的方法是调用 iter(x) 函数,如果不可迭代,则处理 TypeError 异常。这比使用 isinstance(x, abc. Iterable) 更准确,因为 iter(x) 函数还会考虑过时的 __getitem__ 方法,而抽象基类 Iterable 则不考虑。
1 2 3 4 5 6 >>> iter (s)<iterator object at 0x7fba600afac0 > >>> from collections import abc>>> isinstance (s, abc.Iterable)False
调用 iter() 时,传入两个参数可以创建 可调用对象的迭代器。对于这种用法:
第一个参数必须是一个无参数的可调用对象,重复调用(不传入参数)产生值
第二个参数是哨符,即一种标记值,如果可调用对象返回哨符,则迭代器抛出 StopIteration,而不产出哨符
1 2 3 4 5 6 >>> def d6 ():... return randint(1 , 6 )... >>> d6_iter = iter (d6, 1 )>>> d6_iter<callable_iterator object at 0x7fba60228ee0 >
注意,这里的 d6_iter 是一个 callable_iterator 对象,而非普通的 iterator。
使用内置函数 iter 可以获取迭代器。如果对象实现了能返回迭代器的 __iter__ 方法,那么对象就是可迭代的 。序列都可以迭代:实现了 __getitem__ 方法,而且接受从 0 开始的索引,这种对象也可以迭代。
Python 从可迭代对象中获取迭代器:
1 2 3 4 5 6 7 >>> s = 'ABC' >>> for char in s:... print (char)... A B C
1 2 3 4 5 6 7 8 9 10 11 12 >>> s = 'ABC' >>> it = iter (s)>>> while True :... try :... print (next (it))... except StopIteration:... del it... break ... A B C
根据可迭代对象构建迭代器 it
不断在迭代器上调用next函数,获取下一项 没有剩余项时,迭代器抛出 StopIteration
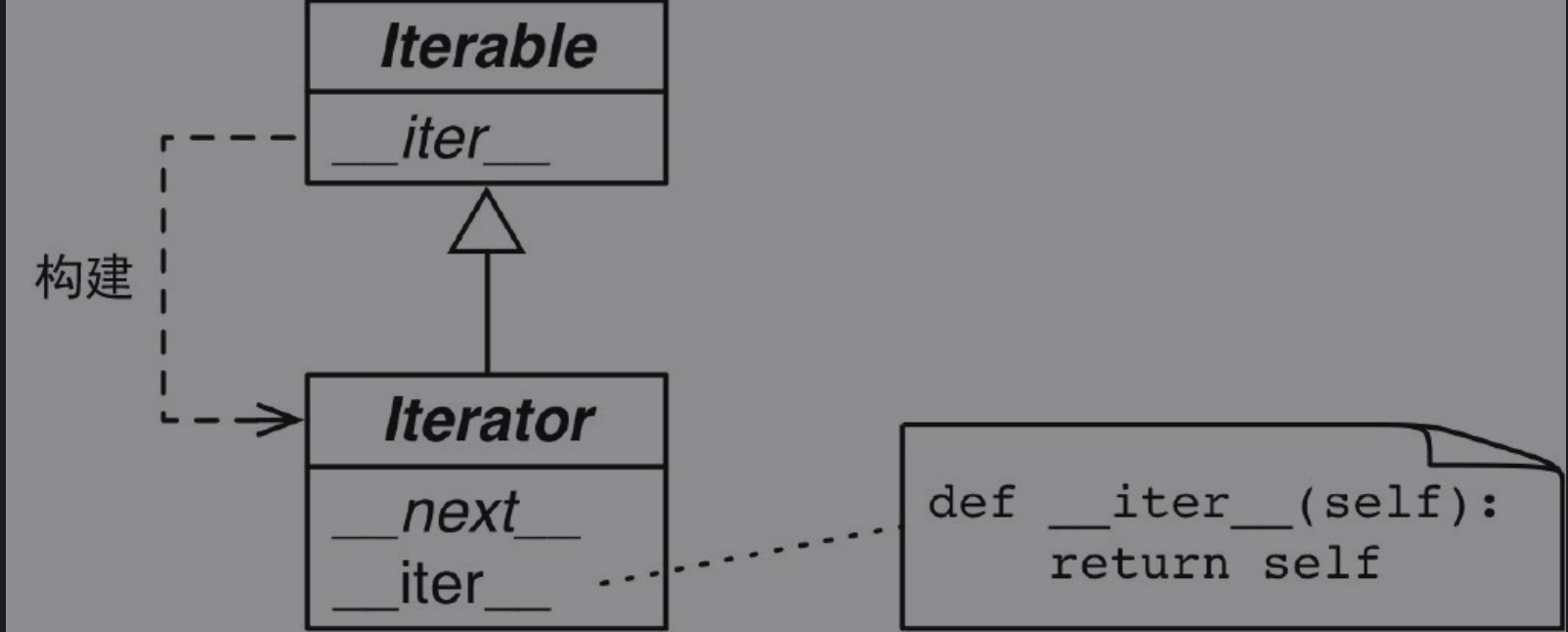
Python 标准的迭代器接口有以下两个方法:
__next__ 返回序列中的下一项,如果没有项了,则抛出 StopIteration__iter__ 返回 self,以便在预期可迭代对象的地方使用迭代器 ,例如 for 循环中。这也说明迭代器本身也是可迭代的
这个接口由抽象基类 collections.abc.Iterator 确立。这个抽象基类定义了抽象方法 __next__,还从 Iterable 类继承了抽象方法 __iter__:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Iterator (Iterable ): __slots__ = () @abstractmethod def __next__ (self ): 'Return the next item from the iterator. When exhausted, raise StopIteration' raise StopIteration def __iter__ (self ): return self @classmethod def __subclasshook__ (cls, C ): if cls is Iterator: return _check_methods(C, '__iter__' , '__next__' ) return NotImplemented
如下代码展示了,如何使用 iter() 构建迭代器的,以及 next() 是如何使用迭代器的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 >>> s3 = Sentence("hello world" )>>> it = iter (s3)>>> it<iterator object at 0x7fba600ef580 > >>> next (it)'hello' >>> next (it)'world' >>> next (it)Traceback (most recent call last): File "<stdin>" , line 1 , in <module> StopIteration >>> list (it)[]
因为迭代器只需 __next__ 和 __iter__ 两个方法,所以除了调用 next() 并捕获 StopIteration 异常之外,没有其他办法检查是否还有剩余项。此外,也没有办法 重置 迭代器。如果想再次迭代,那就要调用 iter(),传入之前构建迭代器的可迭代对象 。传入迭代器本身也没用,因为前面说过,Iterator.__iter__ 方法的实现方式是返回 self,所以无法重置已经耗尽的迭代器。
得益于内置函数 iter() 对序列的特殊处理,因此上面的 Sentence 序列类可以迭代。接下来将重新实现 Sentence 类,实现 __iter__ 方法返回迭代器。
__iter__ 方法下面为 Sentence 类实现标准的可迭代对象接口,先通过迭代器模式实现。
如下代码展示了经典的迭代器设计模式的实现方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import reimport reprlibRE_WORD = re.compile (r'\w+' ) class Sentence : def __init__ (self, text ): self.text = text self.words = RE_WORD.findall(text) def __repr__ (self ): return f'Sentence({reprlib.repr (self.text)} )' def __iter__ (self ): return SentenceIterator(self.words) class SentenceIterator : def __init__ (self, words ): self.words = words self.index = 0 def __next__ (self ): try : word = self.words[self.index] except IndexError: raise StopIteration() self.index += 1 return word def __iter__ (self ): return self
Sentence 类可以迭代,因为它实现了特殊方法 __iter__,返回一个 SentenceIterator 实例
SentenceIterator 类实现了迭代器协议,即实现了 __next__ 和 __iter__ 方法
迭代结束时,__next__ 方法抛出 StopIteration 异常
构建可迭代对象和迭代器时经常会出现错误,原因是混淆了二者:
可迭代对象有个 __iter__ 方法,每次都实例化一个新迭代器
而迭代器要实现 __next__ 方法,返回单个元素,此外还要实现 __iter__ 方法,返回迭代器本身
因此,迭代器也是可迭代对象,但是可迭代对象不是迭代器 。迭代器模式可以用来:
访问一个聚合对象的内容而无须暴露它的内部表示
支持对聚合对象的多种遍历
为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)
为了支持多种遍历,必须能从同一个可迭代对象中获取多个独立的迭代器,而且各个迭代器要能维护自身的内部状态 。因此这一模式正确的实现方式是,每次调用 iter(my_iterable) 都新建一个独立的迭代器。因此让 Sentence 类既是可迭代对象、又是迭代器是一种反模式,是不好的设计。这就是本例需要 SentenceIterator 类的原因。
实现相同功能,但符合 Python 习惯的方式是,用生成器代替 SentenceIterator 类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import reimport reprlibRE_WORD = re.compile (r'\w+' ) class Sentence : def __init__ (self, text ): self.text = text self.words = RE_WORD.findall(text) def __repr__ (self ): return 'Sentence(%s)' % reprlib.repr (self.text) def __iter__ (self ): for word in self.words: yield word
__iter__ 方法的核心逻辑是迭代 self.words,产出当前的 word不用再单独定义一个迭代器类
这里的关键是,返回的迭代器其实是生成器对象,在调用 __iter__ 方法时自动创建,因为这里的 __iter__ 方法是生成器函数 。
只要 Python 函数的主体中有 yield 关键字,该函数就是生成器函数。调用生成器函数,返回一个生成器对象 。也就是说,生成器函数是生成器工厂。普通函数与生成器函数在句法上唯一的区别是,后者的主体中有 yield 关键字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 >>> def gen_123 ():... yield 1 ... yield 2 ... yield 3 ... >>> gen_123<function gen_123 at 0x1051a6de0 > >>> g = gen_123()>>> g<generator object gen_123 at 0x10494b8a0 > >>> next (g)1 >>> next (g)2 >>> next (g)3 >>> next (g)Traceback (most recent call last): File "<python-input-8>" , line 1 , in <module> next (g) ~~~~^^^ StopIteration >>> g = gen_123()>>> for t in g:... print (t)... 1 2 3
gen_123 是一个生成器函数,所以它是一个函数对象
调用 gen_123() 这个生成器函数,返回得到一个生成器对象
生成器对象实现了 Iterator 接口,因此生成器对象也可以迭代
生成器函数创建一个生成器对象,包装生成器函数的主体。把生成器对象传给 next() 函数时:
执行生成器函数主体中的代码,直到遇到 yield 语句
返回产出的值,并在函数主体的当前位置暂停
最终,函数的主体返回时,Python 创建的外层生成器对象抛出 StopIteration 异常,这一点与 Iterator 协议一致
总结一下:
我们说函数会返回值,调用生成器函数,它返回生成器
生成器产出值 ,生成器不以常规的方式 返回 值生成器函数主体中的 return 语句触发生成器对象抛出 StopIteration 异常
如果生成器中有 return x 语句,则调用方能从 StopIteration 异常中获取 x 的值,但是我们往往把这个操作交给 yield from 句法(后文详细介绍)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 >>> def gen_AB ():... print ("start" )... yield "A" ... print ("continue" )... yield "B" ... print ("end" )... >>> g = gen_AB()>>> next (g)start 'A' >>> next (g)continue 'B' >>> next (g)end Traceback (most recent call last): File "<python-input-17>" , line 1 , in <module> next (g) ~~~~^^^ StopIteration >>> for t in gen_AB():... print (f"-->{t} " )... start -->A continue -->B end
迭代时,for 机制的作用与 g = iter(gen_AB()) 一样,用于获取生成器对象,并在每次迭代时调用 next(g)。for 机制捕获 StopIteration 异常,循环完美终止。
因此对于上一版的 Sentence 类,Sentence.__iter__ 是一个生成器函数,调用时构建一个实现了 Iterator 接口的生成器对象,因此不再需要 SentenceIterator 类。这个版本已经实现很简洁了,但是还不够惰性。如今,人们认为惰性是好的特质,至少在编程语言和 API 中是如此 。惰性实现是指尽可能延后生成值。这样做能节省内存,或许还可以避免浪费 CPU 循环。
Iterator 接口在设计时考虑到了惰性:next(my_iterator) 一次产出一项。目前实现的几版 Sentence 类都不具有惰性,因为 __init__ 方法及早构建好了文本中的单词列表,然后将其绑定到 self.words 属性上。这样就得处理整个文本,列表使用的内存量可能与文本本身一样多。
re.finditer 函数是 re.findall 函数的惰性版本,返回的不是列表,而是一个生成器,按需产出 re.MatchObject 实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import reimport reprlibRE_WORD = re.compile (r'\w+' ) class Sentence : def __init__ (self, text ): self.text = text def __repr__ (self ): return f'Sentence({reprlib.repr (self.text)} )' def __iter__ (self ): for match in RE_WORD.finditer(self.text): yield match .group()
finditer 函数构建一个迭代器,包含 self.text 中匹配 RE_WORD 的单词,产出 MatchObject 实例
match.group() 方法从 MatchObject 实例中提取匹配的文本
简单的生成器函数,可以替换成生成器表达式。列表推导式构建列表,而生成器表达式构建生成器对象 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 >>> def gen_AB ():... print ("start" )... yield "A" ... print ("continue" )... yield "B" ... print ("end" )... >>> res1 = [x * 3 for x in gen_AB()]start continue end >>> res1['AAA' , 'BBB' ] >>> res2 = (x* 3 for x in gen_AB())>>> res2<generator object <genexpr> at 0x103391220 > >>> for i in res2:... print (i)... start AAA continue BBB end
这里生成器表达式 (x* 3 for x in gen_AB()) 返回一个生成器对象 res2。该生成器在这里没有使用。
只有在循环迭代生成器时,这个生成器才从 gen_AB 生成器中获取值
可以使用生成器表达式进一步精简 Sentence 类的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import reimport reprlibRE_WORD = re.compile (r'\w+' ) class Sentence : def __init__ (self, text ): self.text = text def __repr__ (self ): return f'Sentence({reprlib.repr (self.text)} )' def __iter__ (self ): return (match .group() for match in RE_WORD.finditer(self.text))
这里所用的不是生成器函数了(没有 yield),而是使用生成器表达式构建生成器,然后将其返回。不过,最终效果一样:__iter__ 方法的调用方得到一个生成器对象。
生成器表达式是语法糖,完全可以替换成生成器函数,不过有时使用生成器表达式更便利。生成器表达式是创建生成器的简洁句法,无须先定义函数再调用。不过,生成器函数更为灵活,可以使用多个语句实现复杂的逻辑,甚至可以作为协程使用。如果生成器表达式要分成多行编写,那么倾向于定义生成器函数,以便提高可读性 。
另外,如果函数或构造函数只有一个参数,传入生成器表达式时不用先写一对调用函数的括号,再写一对括号围住生成器表达式,只写一对括号就行了。然而,如果生成器表达式后面还有其他参数,那就必须使用括号围住,否则会抛出 SyntaxError 异常。
1 Vector(n * scalar for n in self)
接下来我们讨论一下迭代器和生成器:
生成器对象提供了 __next__ 方法,因此生成器对象是迭代器。Python3.5 之后,还可以使用 async def 声明异步生成器。
如果一个类只是为了构建生成器而去实现 __iter__ 方法,那还不如直接使用生成器函数。毕竟,生成器函数本身就是制造生成器的工厂。
标准库中有许多现成的生成器可用,例如 itertools 模块就提供了多个生成器函数:
itertools.count 函数返回的生成器能产出数值itertools.takewhile 返回一个使用另一个生成器的生成器,在指定的条件求值结果为 False 时停止
如下函数返回了一个等差数列生成器:
1 2 3 4 5 6 7 8 import itertoolsdef aritprog_gen (begin, step, end=None ): first = type (begin + step)(begin) ap_gen = itertools.count(first, step) if end is None : return ap_gen return itertools.takewhile(lambda n: n < end, ap_gen)
下面是标准库提供的用于筛选的生成器函数:从输入的可迭代对象中产出项的子集,而且不修改项本身。大多数函数接受一个 predicate 参数。这个参数的值是一个布尔函数,接受一个参数,应用到输入中的每一项上,用于判断项是否包含在输出中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 >>> def vowel (c ):... return c.lower() in 'aeiou' ... >>> list (filter (vowel, 'Aardvark' ))['A' , 'a' , 'a' ] >>> import itertools>>> list (itertools.filterfalse(vowel, 'Aardvark' ))['r' , 'd' , 'v' , 'r' , 'k' ] >>> list (itertools.dropwhile(vowel, 'Aardvark' ))['r' , 'd' , 'v' , 'a' , 'r' , 'k' ] >>> list (itertools.takewhile(vowel, 'Aardvark' ))['A' , 'a' ] >>> list (itertools.compress('Aardvark' , (1 , 0 , 1 , 1 , 0 , 1 )))['A' , 'r' , 'd' , 'a' ] >>> list (itertools.islice('Aardvark' , 4 ))['A' , 'a' , 'r' , 'd' ] >>> list (itertools.islice('Aardvark' , 4 , 7 ))['v' , 'a' , 'r' ] >>> list (itertools.islice('Aardvark' , 1 , 7 , 2 ))['a' , 'd' , 'a' ]
下一组是用于映射的生成器函数:在输入的可迭代对象中的各项上做计算,产出计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 >>> sample = [5 , 4 , 2 , 8 , 7 , 6 , 3 , 0 , 9 , 1 ]>>> import itertools>>> list (itertools.accumulate(sample))[5 , 9 , 11 , 19 , 26 , 32 , 35 , 35 , 44 , 45 ] >>> list (itertools.accumulate(sample, min ))[5 , 4 , 2 , 2 , 2 , 2 , 2 , 0 , 0 , 0 ] >>> list (itertools.accumulate(sample, max ))[5 , 5 , 5 , 8 , 8 , 8 , 8 , 8 , 9 , 9 ] >>> import operator>>> list (itertools.accumulate(sample, operator.mul))[5 , 20 , 40 , 320 , 2240 , 13440 , 40320 , 0 , 0 , 0 ] >>> list (itertools.accumulate(range (1 , 11 ), operator.mul))[1 , 2 , 6 , 24 , 120 , 720 , 5040 , 40320 , 362880 , 3628800 ] >>> list (enumerate ('albatroz' , 1 )[(1 , 'a' ), (2 , 'l' ), (3 , 'b' ), (4 , 'a' ), (5 , 't' ), (6 , 'r' ), (7 , 'o' ), (8 , 'z' )] >>> import operator>>> list (map (operator.mul, range (11 ), range (11 )))[0 , 1 , 4 , 9 , 16 , 25 , 36 , 49 , 64 , 81 , 100 ] >>> list (map (operator.mul, range (11 ), [2 , 4 , 8 ]))[0 , 4 , 16 ] >>> list (map (lambda a, b: (a, b), range (11 ), [2 , 4 , 8 ]))[(0 , 2 ), (1 , 4 ), (2 , 8 )] >>> import itertools>>> list (itertools.starmap(operator.mul, enumerate ('albatroz' , 1 )))['a' , 'll' , 'bbb' , 'aaaa' , 'ttttt' , 'rrrrrr' , 'ooooooo' , 'zzzzzzzz' ] >>> sample = [5 , 4 , 2 , 8 , 7 , 6 , 3 , 0 , 9 , 1 ]>>> list (itertools.starmap(lambda a, b: b / a,... enumerate (itertools.accumulate(sample), 1 )))[5.0 , 4.5 , 3.6666666666666665 , 4.75 , 5.2 , 5.333333333333333 , 5.0 , 4.375 , 4.888888888888889 , 4.5 ]
接下来这一组生成器函数用于合并,这些函数都从输入的多个可迭代对象中产出项。chain 和chain.from_iterable 按顺序(一个接一个)处理输入的可迭代对象,而 product、zip 和 zip_longest 并行处理输入的各个可迭代对象。itertools.product 生成器是计算笛卡儿积的惰性方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 >>> list (itertools.chain('ABC' , range (2 )))['A' , 'B' , 'C' , 0 , 1 ] >>> list (itertools.chain(enumerate ('ABC' )))[(0 , 'A' ), (1 , 'B' ), (2 , 'C' )] >>> list (itertools.chain.from_iterable(enumerate ('ABC' )))[0 , 'A' , 1 , 'B' , 2 , 'C' ] >>> list (zip ('ABC' , range (5 ), [10 , 20 , 30 , 40 ]))[('A' , 0 , 10 ), ('B' , 1 , 20 ), ('C' , 2 , 30 )] >>> list (itertools.zip_longest('ABC' , range (5 )))[('A' , 0 ), ('B' , 1 ), ('C' , 2 ), (None , 3 ), (None , 4 )] >>> list (itertools.zip_longest('ABC' , range (5 ), fillvalue='?' ))[('A' , 0 ), ('B' , 1 ), ('C' , 2 ), ('?' , 3 ), ('?' , 4 )] >>> list (itertools.product('ABC' , range (2 )))[('A' , 0 ), ('A' , 1 ), ('B' , 0 ), ('B' , 1 ), ('C' , 0 ), ('C' , 1 )]
有些生成器函数会从一项中产出多个值,从而扩充输入的可迭代对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 >>> ct = itertools.count()>>> next (ct)0 >>> next (ct), next (ct), next (ct)(1 , 2 , 3 ) >>> list (itertools.islice(itertools.count(1 , .3 ), 3 ))[1 , 1.3 , 1.6 ] >>> cy = itertools.cycle('ABC' )>>> next (cy)'A' >>> list (itertools.islice(cy, 7 ))['B' , 'C' , 'A' , 'B' , 'C' , 'A' , 'B' ] >>> list (itertools.pairwise(range (7 )))[(0 , 1 ), (1 , 2 ), (2 , 3 ), (3 , 4 ), (4 , 5 ), (5 , 6 )] >>> rp = itertools.repeat(7 )>>> next (rp), next (rp)(7 , 7 ) >>> list (itertools.repeat(8 , 4 ))[8 , 8 , 8 , 8 ] >>> list (map (operator.mul, range (11 ), itertools.repeat(5 )))[0 , 5 , 10 , 15 , 20 , 25 , 30 , 35 , 40 , 45 , 50 ] >>> list (itertools.combinations('ABC' , 2 ))[('A' , 'B' ), ('A' , 'C' ), ('B' , 'C' )] >>> list (itertools.combinations_with_replacement('ABC' , 2 ))[('A' , 'A' ), ('A' , 'B' ), ('A' , 'C' ), ('B' , 'B' ), ('B' , 'C' ), ('C' , 'C' )] >>> list (itertools.permutations('ABC' , 2 ))[('A' , 'B' ), ('A' , 'C' ), ('B' , 'A' ), ('B' , 'C' ), ('C' , 'A' ), ('C' , 'B' )] >>> list (itertools.product('ABC' , repeat=2 ))[('A' , 'A' ), ('A' , 'B' ), ('A' , 'C' ), ('B' , 'A' ), ('B' , 'B' ), ('B' , 'C' ), ('C' , 'A' ), ('C' , 'B' ), ('C' , 'C' )]
接下来这一组生成器函数用于产出输入的可迭代对象中的全部项,不过会以某种方式重新排列。itertools.groupby 假定输入的可迭代对象可以使用分组标准排序,即使不排序,至少也要使用指定的标准分组各项。iterator.tee 从输入的一个可迭代对象中产出多个生成器,每个生成器都可以产出输入中的各项。产出的各个生成器可以单独使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 >>> list (itertools.groupby('LLLLAAGGG' ))[('L' , <itertools._grouper object at 0x102227cc0 >), ('A' , <itertools._grouper object at 0x102227b38 >), ('G' , <itertools._grouper object at 0x102227b70 >)] >>> for char, group in itertools.groupby('LLLLAAAGG' ):... print (char, '->' , list (group))... L -> ['L' , 'L' , 'L' , 'L' ] A -> ['A' , 'A' ,] G -> ['G' , 'G' , 'G' ] >>> animals = ['duck' , 'eagle' , 'rat' , 'giraffe' , 'bear' ,... 'bat' , 'dolphin' , 'shark' , 'lion' ]>>> animals.sort(key=len )>>> animals['rat' , 'bat' , 'duck' , 'bear' , 'lion' , 'eagle' , 'shark' , 'giraffe' , 'dolphin' ]>>> for length, group in itertools.groupby(animals, len ):... print (length, '->' , list (group))... 3 -> ['rat' , 'bat' ]4 -> ['duck' , 'bear' , 'lion' ]5 -> ['eagle' , 'shark' ]7 -> ['giraffe' , 'dolphin' ]>>> for length, group in itertools.groupby(reversed (animals), len ):... print (length, '->' , list (group))... 7 -> ['dolphin' , 'giraffe' ]5 -> ['shark' , 'eagle' ]4 -> ['lion' , 'bear' , 'duck' ]3 -> ['bat' , 'rat' ]>>> list (itertools.tee('ABC' ))[<itertools._tee object at 0x10222abc8 >, <itertools._tee object at 0x10222ac08 >] >>> g1, g2 = itertools.tee('ABC' )>>> next (g1)'A' >>> next (g2)'A' >>> next (g2)'B' >>> list (g1)['B' , 'C' ] >>> list (g2)['C' ] >>> list (zip (*itertools.tee('ABC' )))[('A' , 'A' ), ('B' , 'B' ), ('C' , 'C' )]
如下函数都接受一个可迭代对象,返回单个结果。这些函数叫 归约 函数。其实,这里列出的每个内置函数都可以使用 functools.reduce 函数实现,之所以内置是因为使用它们便于解决常见的问题。之所以内置是因为使用它们便于解决常见的问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 >>> all ([1 , 2 , 3 ])True >>> all ([1 , 0 , 3 ])False >>> all ([])True >>> any ([1 , 2 , 3 ])True >>> any ([1 , 0 , 3 ])True >>> any ([0 , 0.0 ])False >>> any ([])False >>> g = (n for n in [0 , 0.0 , 7 , 8 ])>>> any (g)True >>> next (g)8 >>> max (("3" , "12" , "111" ), key=len )'111' >>> min (("3" , "12" , "111" ), key=len )'3' >>> sum ((1 , 2 , 3 , 4 , 5 ))15
all 和 any 函数都会短路求值,这两个函数会短路,即一旦确定了结果就立即停止使用迭代器
还有一个内置函数也接受一个可迭代对象,返回相关结果,即 sorted 函数。reversed是生成器函数,而 sorted 不同,它构建并返回一个新列表。毕竟,要读取输入的可迭代对象中的每一项才能排序,而且排序的对象是列表,因此 sorted 操作完成后返回排序后的列表。
Python3.3 新增的 yield from 表达式句法可把一个生成器的工作委托给一个子生成器。yield from 句法提供了一种组合生成器的新方式。
引入 yield from 之前,如果一个生成器根据另一个生成器生成的值产出值,则需要使用 for 循环:
1 2 3 4 5 6 7 8 9 10 11 12 >>> def sub_gen ():... yield 1.1 ... yield 1.2 ... >>> def gen ():... yield 1 ... for i in sub_gen():... yield i... yield 2 ... >>> [t for t in gen()][1 , 1.1 , 1.2 , 2 ]
使用 yield from 可以达到相同的效果:
1 2 3 4 5 6 7 8 9 10 11 >>> def sub_gen ():... yield 1.1 ... yield 1.2 ... >>> def gen ():... yield 1 ... yield from sub_gen()... yield 2 ... >>> [t for t in gen()][1 , 1.1 , 1.2 , 2 ]
for 循环是客户代码,gen 是委托生成器,sub_gen 是子生成器。注意,yield from 暂停 gen,sub_gen 接手,直到它耗尽。sub_gen 产出的值绕过 gen,直接传给客户代码中的 for 循环。在此期间,gen 处在暂停状态,看不到绕过它的那些值。当 sub_ gen 耗尽后,gen 恢复执行 。
子生成器中有 return 语句时,返回一个值,在委托生成器中,通过含有 yield from 的表达式可以捕获那个值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 >>> def sub_gen ():... yield 1.1 ... yield 1.2 ... return 'done' ... >>> def gen ():... yield 1 ... result = yield from sub_gen()... print (f'<--{result} ' )... yield 2 ... >>> for x in gen():... print (x)... 1 1.1 1.2 <--done 2
itertools 模块中有一个 chain 生成器,它从多个可迭代对象中产出项,先迭代第一个可迭代对象,然后迭代第二个,一直到最后一个可迭代对象。用 for 循环实现:
1 2 3 4 5 6 7 8 9 >>> def chain (*iterables ):... for it in iterables:... for i in it:... yield i... >>> s = 'ABC' >>> r = range (3 )>>> list (chain(s, r))['A' , 'B' , 'C' , 0 , 1 , 2 ]
也可以通过 yield from 实现:
1 2 3 4 5 6 >>> def chain (*iterables ):... for i in iterables:... yield from i... >>> list (chain(s, t))['A' , 'B' , 'C' , 0 , 1 , 2 ]
如下是一个更复杂的递归例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def tree (cls, level=0 ): yield cls.__name__, level for sub_cls in cls.__subclasses__(): yield from tree(sub_cls, level+1 ) def display (cls ): for cls_name, level in tree(cls): indent = ' ' * 4 * level print (f'{indent} {cls_name} ' ) if __name__ == '__main__' : display(BaseException)
yield from 建立子生成器与客户代码之间的直接联系,绕过委托生成器。把生成器用作协程时,这种联系就变得十分重要,它不仅产出值,而且还利用客户代码提供的值。
如果函数的参数是可迭代对象,可以使用 collections.abc.Iterable 注解(如果必须支持 Python3.8 或之前的版本,那就使用 typing.Iterable 注解)。
1 2 3 4 5 6 7 8 from collections.abc import IterableFromTo = tuple [str , str ] def zip_replace (text: str , changes: Iterable[FromTo] ) -> str : for from_, to in changes: text = text.replace(from_, to) return text
Iterator 类型没有 Iterable 类型那么常用,但是编写方式也不难。注意,Iterator 类型用于注解含有yield 关键字的生成器函数,以及我们自己动手编写的带有 __next__ 方法的迭代器类。此外,还有一个 collections.abc.Generator 类型(以及已经弃用的 typing.Generator),用于注解生成器对象,但是把生成器当作迭代器使用时,无须多此一举。
1 2 3 4 5 6 7 from collections.abc import Iteratordef fibonacci () -> Iterator[int ]: a, b = 0 , 1 while True : yield a a, b = b, a + b
1 2 3 4 5 6 7 8 9 10 11 12 13 from collections.abc import Iteratorfrom keyword import kwlistfrom typing import TYPE_CHECKINGshort_kw = (k for k in kwlist if len (k) < 5 ) if TYPE_CHECKING: reveal_type(short_kw) long_kw: Iterator[str ] = (k for k in kwlist if len (k) >= 4 ) if TYPE_CHECKING: reveal_type(long_kw)
1 2 3 4 check.py:8: note: Revealed type is "typing.Generator[builtins.str, None, None]" check.py:13: note: Revealed type is "typing.Iterator[builtins.str]" Success: no issues found in 1 source file
abc.Iterator[str] 与 abc.Generator[str, None, None] 相容。Iterator[T] 是 Generator[T, None, None] 的简写形式,二者的意思都是 产出项的类型为 T,但是不利用或返回值的生成器,能利用和返回值的生成器是协程 。
PEP 342—Coroutines via Enhanced Generators 引入 .send() 方法和其他功能后,生成器可以用作协程。PEP342 中协程的含义就是这里的 经典协程。Python3.5 发布之后,协程 通常就是指 原生协程。但是,PEP 342 还未废弃,经典协程最初的作用没有改变,尽管已经不受 asyncio 支持。
Python 中的经典协程不太容易理解,因为经典协程其实就是生成器,只不过以另一种方式使用。生成器通常用作迭代器,但是也可以用作协程。协程其实就是生成器函数,通过主体中含有 yield 关键字的函数创建。自然,协程对象就是生成器对象 。
尽管 Python 生成器和协程的底层 C 语言实现是一样的,但是二者的适用情形差别很大,因此类型提示的写法也不相同:
1 2 3 4 5 6 readings: Iterator[float ] sim_taxi: Generator[Event, float , int ]
typing 模块的作者决定把那个类型命名为 Generator,事实上,它描述的 API 是用作协程的生成器对象,而生成器更常用作简单的迭代器 。typing 模块的文档像下面这样描述 Generator 的形式类型参数:
1 Generator[YieldType, SendType, ReturnType]
仅当把生成器用作协程时,SendType 才有意义。那个类型参数是 gen.send(x) 调用中 x 的类型。倘若创建生成器的目的是用作迭代器,而不是协程,则调用 .send() 将报错
同样,ReturnType 也只在注解协程时有意义,因为迭代器不像常规函数那样可以返回值。对于用作迭代器的生成器,唯一合理的操作是调用 next(it),可以直接调用,也可以通过 for 循环和其他迭代形式间接调用
YieldType 是 next(it) 调用返回值的类型
Generator 类型的类型参数与 typing.Coroutine 相同:
1 Coroutine [YieldType, SendType, ReturnType]
但是,typing.Coroutine(已弃用)和 collections.abc.Coroutine(自 Python3.9 起可用的泛型)仅用于注解原生协程,不能注解经典协程。经典协程的类型提示只能使用模糊不清的 Generator[YieldType, SendType, ReturnType]。
关于生成器和协程:
生成器生产供迭代的数据
协程是数据的消费者
为了保持头脑清醒,不要混淆这两个概念
协程与迭代没有关系
注意:虽然在协程中可以使用 yield 产出值,但这并不是专门为了迭代
如下代码定义了一个计算累计平均值的协程:
1 2 3 4 5 6 7 8 9 10 11 from collections.abc import Generatordef averager () -> Generator[float , float , None ]: total = 0.0 count = 0 average = 0.0 while True : term = yield average total += term count += 1 average = total/count
这个函数返回一个生成器,该生成器产出 float 值,通过 .send() 接受 float 值,而且不返回有用的值
这个无限循环表明,只要客户代码不断发送值,它就会一直产出平均值
这里的 yield 语句暂停执行协程,把结果发给客户,而且稍后还用于接收调用方后面发给协程的值,再次开始无限循环迭代
使用协程的好处是,total 和 count 声明为局部变量即可,在协程暂停并等待下一次调用 .send() 期间,无须使用实例属性或闭包保持上下文。正是这一点吸引人们在异步编程中把回调换成协程,因为在多次激活之间,协程能保持局部状态 。
如下则展示了如何使用这个协程:
1 2 3 4 5 6 7 8 9 >>> coro_avg = averager()>>> next (coro_avg)0.0 >>> coro_avg.send(10 )10.0 >>> coro_avg.send(20 )15.0 >>> coro_avg.send(30 )20.0
首先调用协程函数,创建协程对象
调用 next() 开始执行协程,这里产出 average 变量的初始值,即 0.0
真正计算累计平均值:多次调用 .send() 方法,产出当前平均值
调用 next(coro_avg) 后,协程向前执行到 yield,产出 average 变量的初始值。另外,也可以调用coro_avg.send(None) 开始执行协程——这其实就是内置函数 next() 的作用。但是,不能发送 None 之外的值,因为协程只能在 yield 处暂停时接受发送的值。调用 next() 或 .send(None) 向前执行到第一个 yield 的过程叫作 预激协程 。
每次激活之后,协程在 yield 处暂停,等待发送值
coro_avg.send(10) 那一行发送一个值,激活协程,yield 表达式把得到的值 10 赋给 term 变量继续执行代码,while循环的下一次迭代产出 average 变量的值,协程在 yield 关键字处再一次暂停
我们一般不终止生成器,因为一旦没有对生成器的有效引用,生成器就会被当作垃圾回收。如果你想显式终止协程,那就使用 .close() 方法:
1 2 3 4 5 6 >>> coro_avg.close()>>> coro_avg.close()>>> coro_avg.send(10 )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> StopIteration
.close() 方法在暂停的 yield 表达式处抛出 GeneratorExit。如果协程函数没有处理,则该异常终止协程在已经关闭的协程上调用 .close() 方法没有效果
在已经关闭的协程上调用 .send(),抛出 StopIteration
如下实现了一个新的计算平均值的协程。这一版不产出过程中得到的结果,而是最终返回一个元组,指明项数和平均值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from collections.abc import Generatorfrom typing import Union , NamedTupleclass Result (NamedTuple ): count: int average: float class Sentinel : def __repr__ (self ): return f'<Sentinel>' STOP = Sentinel() SendType = Union [float , Sentinel] def averager2 (verbose: bool = False ) -> Generator[None , SendType, Result]: total = 0.0 count = 0 average = 0.0 while True : term = yield if verbose: print ('received:' , term) if isinstance (term, Sentinel): break total += term count += 1 average = total / count return Result(count, average)
这个协程产出值的类型是 None,因为它不产出数据。接收的数据类型是 SendType,最后返回一个 Result 元组
像这样使用 yield,只存在于协程中,目的是消耗数据。这个 yield 产出 None,从 .send(term) 接收 term
如果 term 是哨符,则跳出循环
通过 isinstance 检查后,Mypy 才允许把 term 加到 total 上,也不会通过报错来提醒不能把一个float 值加到一个可能为 float 或 Sentinel 的对象上
1 2 3 4 5 6 >>> coro_avg = averager2()>>> next (coro_avg)>>> coro_avg.send(10 )>>> coro_avg.send(30 )>>> coro_avg.send(6.5 )>>> coro_avg.close()
如上代码,调用 .close(),协程停止,但不返回结果,因为协程中 yield 所在的那行抛出了 GeneratorExit 异常,所以执行不到 return 语句
1 2 3 4 5 6 7 8 9 10 11 12 >>> coro_avg = averager2()>>> next (coro_avg)>>> coro_avg.send(10 )>>> coro_avg.send(30 )>>> coro_avg.send(6.5 )>>> try :... coro_avg.send(STOP)... except StopIteration as exc:... result = exc.value... >>> resultResult(count=3 , average=15.5 )
发送 STOP 哨符,协程跳出循环,返回一个 Result。然后,包装协程的生成器对象抛出 StopIteration
把 StopIteration 实例的 value 属性绑定为终止协程的 return 语句的值
从 StopIteration 异常中 偷取 协程的返回值,感觉不是标准做法。然而,PEP 342—Coroutines via Enhanced Generators 就是这样规定的。委托生成器可以使用 yield from 句法直接获取协程的返回值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 >>> def compute ():... res = yield from averager2(True )... print ('computed:' , res)... return res... >>> comp = compute()>>> for v in [None , 10 , 20 , 30 , STOP]:... try :... comp.send(v)... except StopIteration as exc:... result = exc.valuereceived: 10 received: 20 received: 30 received: <Sentinel> computed: Result(count=3 , average=20.0 ) >>> resultResult(count=3 , average=20.0 )
res 获得 averager2 的返回值。yield from 机制在处理表示协程终止的 StopIteration 异常时获取返回值
循环代码捕获 StopIteration,获取 compute 的返回值
从这些示例可以看出,直接使用协程既麻烦又让人摸不着头脑。再加上异常处理和协程的 .throw() 方法,情况会变得更加复杂。在实践中,使用协程的生产性工作需要专门的框架支持。
Python3.5 引入原生协程之后,Python 核心开发人员正在逐步淘汰 asyncio 对经典协程的支持。async def 句法使得代码中的原生协程更容易被发现,这是一大进步。在原生协程内部,委托其他协程的 yield from 换成了 await。不过经典协程是原生协程的基础,而且 await 就源自 yield from 表达式。
typing.Generator 是标准库中为数不多的几个有逆变类型参数的类型。学习经典协程之后,现在可以分析这个泛型了。在 Python3.6 中,typing.py 模块的 typing.Generator 类型是像下面这样声明的。
1 2 3 4 5 6 7 8 T_co = TypeVar('T_co' , covariant=True ) V_co = TypeVar('V_co' , covariant=True ) T_contra = TypeVar('T_contra' , contravariant=True ) class Generator (Iterator[T_co], Generic [T_co, T_contra, V_co], extra=_G_base):
从形式参数中的类型变量可以看出,YieldType 和 ReturnType 可以协变,SendType 可以逆变
为了理解其中的原因,可以把 YieldType 和 ReturnType 看作 输出 类型,描述的都是从协程对象(即用作协程的生成器对象)中获取的数据
这两个类型参数可以协变的原因不难理解,因为预取产出浮点数的协程自然可以使用产出整数的协程。这是 YieldType 参数可以协变的原因,同样也适用于可以协变的 ReturnType 参数。
YieldType 和 ReturnType 体现了 型变经验法则 给出的第一条法则:如果一个形式类型参数定义的是从对象中获取的数据类型,那么该形式类型参数可能是协变的
1 2 float :> int Generator[float , Any , float ] :> Generator[int , Any , int ]
另一方面,SendType是 输入 参数,是协程对象 .send(value) 方法的 value 参数的类型。如果客户代码需要向协程发送浮点数,那就不能使用 SendType 为 int 的协程,因为 float 不是 int 的子类型也就是说,float 与 int 不相容。但是,可以使用 SendType 为 complex 的协程,因为 float 是 complex 的子类型,即 float 与 complex 相容
这体现了型变经验法则中的第二条:如果一个形式类型参数定义的是对象初始化之后向对象中输入的数据类型,那么该形式类型参数可能是逆变的
1 2 float :> int Generator[Any , float , Any ] <: Generator[Any , int , Any ]