这篇文章是 claude code 官方文档 的学习笔记,旨在对 claude code 有个系统的、全面的了解,了解 claude code 的核心概念,方便解决 claude code 使用过程中遇到的问题。
claude code 简介
Claude Code 是一款智能体式编码工具(agentic coding tool),可读取你的代码库、编辑文件、执行命令并与各类开发工具集成,支持终端、集成开发环境(IDE)、桌面应用及浏览器等多端使用。
它是基于人工智能的编码助手,能助力你开发功能、修复程序漏洞、自动化完成开发相关任务。该工具可理解整个代码库的逻辑,还能跨多个文件、协同多款工具完成开发工作。
安装
可以选择合适的使用环境开始体验 Claude Code,多数使用场景需你拥有 Claude 订阅账号 或 Anthropic 控制台账号。其中终端命令行工具(CLI)和 VS Code 插件还支持对接第三方服务商。
这里我们以终端环境使用 Claude Code 为例,演示如何快速上手。通过功能齐全的 cli 命令可以在终端环境上使用 Claude Code。
- Linux 系统安装
1 | curl -fsSL https://claude.ai/install.sh | bash |
- 安装完成后,需要将
~/.local/bin目录添加到你的 PATH 环境变量中。
1 | # echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrc |
- 验证安装成功
1 | # claude --version |
- 运行
claude update命令更新 claude code 到最新版本
1 | # claude update |
claude code 的核心功能
- 自动化处理积压的繁琐工作:Claude Code 可处理占据大量工作时间的繁琐开发任务:为未编写测试的代码撰写测试用例、修复整个项目的代码检查错误、解决代码合并冲突、更新项目依赖、编写发布说明等等
- 开发功能与修复程序漏洞:
- 用自然语言描述你的开发需求,Claude Code 会规划实现方案、跨多个文件编写代码并验证功能可用性
- 针对程序漏洞,你只需粘贴错误信息或描述故障现象,Claude Code 会遍历代码库追踪问题、定位根本原因并完成修复
- 提交代码与创建拉取请求:Claude Code 可直接与 Git 协同工作,支持暂存代码更改、编写提交信息、创建分支、发起拉取请求
- 在持续集成(CI)环境中,你还可通过 GitHub Actions 或 GitLab CI/CD 工具,自动化完成代码评审和问题分类
- 通过 MCP 对接各类工具:模型上下文协议(MCP) 是一套开放式标准,可实现人工智能工具与外部数据源的对接
- 通过指令(instructions)、skills 与 hooks 实现个性化配置
- CLAUDE.md 配置文件:在项目根目录添加该 Markdown 文件,Claude Code 会在每个会话启动时读取文件内容。你可在文件中设置编码规范、架构决策、首选开发库、评审检查清单等内容
- 自动记忆功能:Claude Code 会在工作过程中自动形成记忆,无需手动操作,即可跨会话保存构建命令、调试心得等关键信息。
- 自定义命令:可以将团队可共享的重复性工作流封装为自定义命令,例如 /review-pr(评审拉取请求)、/deploy-staging(部署至预发布环境)
- 钩子(Hooks):可设置在 Claude Code 执行操作前后运行的外壳命令,例如每次文件编辑后自动格式化代码、代码提交前执行代码检查
- 启动 agents team 与开发自定义 agent
- agents team:可启动多个智能体,让它们同时处理一个任务的不同模块,由主智能体协调工作、分配子任务并合并处理结果。
- 自定义智能体:通过
Agent SDK,可基于 Claude Code 的工具和能力开发专属智能体,完全掌控工作编排、工具访问权限等配置
- 通过命令行工具实现管道操作、脚本编写与自动化
- Claude Code 具备可组合性,遵循 Unix 设计理念,支持将日志通过管道传入工具、在持续集成环境中运行、与其他工具串联使用
- 多端无缝协作:
- Claude Code 的会话不绑定单一使用端,可根据使用场景在不同环境间切换工作:
全场景适配
所有使用端均对接 Claude Code 同一底层引擎,因此你的 CLAUDE.md 配置文件、各项设置、MCP 服务器可在所有端通用。
快速入门
接下来将通过实际例子来快速入门 claude code 的使用,同样以终端命令行工具(CLI)为核心讲解。首先需要按照上面的说明,完成 claude code 在 Linux/Mac 系统上的安装。
官方文档是以 claude 官方订阅 账号为例来讲解如何登录并使用 cluade code 的,由于 claude code 账号的严格限制,我们以使用国内 coder 模型 API 的方式来演示,这里使用了火山的 coding plan 套餐:
- 新增如下
claude code配置文件
1 | ~/.claude/settings.json |
- 文件内容如下,
ANTHROPIC_AUTH_TOKEN和ANTHROPIC_BASE_URL都换成自己的配置
1 | { |
- 启动会话
1 | # 进入工作目录 |
- 此时就可以看到 claude code 的交互界面了,可以通过
/status命令查看当前状态
1 | /status |
- 直接用自然语言输入你的任务即可
1 | 帮我写一个 python 的 hello world 程序 |
claude cdoe执行任务,并在执行必要操作时询问你的许可:
1 | ...... |
1 | # more hello_world.py |
- 接下来你可以继续通过自然语言让 claude code 帮你使用 git 提交代码、修改 bug 等
核心命令
以下是日常使用中最常用的核心命令:
| 命令 | 功能 | 示例 |
|---|---|---|
| claude | 启动交互模式 | claude |
| claude “task” | 执行一次性任务 | claude “修复构建错误” |
| claude -p “query” | 执行单次查询后退出 | claude -p “讲解这个函数的功能” |
| claude -c | 在当前目录继续最近一次的对话 | claude -c |
| claude -r | 恢复之前的任意一次对话 | claude -r |
| claude commit | 执行 Git 提交操作 | claude commit |
| /clear | 清空当前对话历史 | /clear |
| /help | 展示所有可用命令 | /help |
| exit 或 Ctrl+C | 退出 Claude Code | exit |
- ?:可查看所有可用的快捷键
- Tab:命令自动补全
- up 键:查看历史输入的命令
- /:查看所有命令和 skill
Claude Code 工作原理
Claude Code 是一款运行在终端中的智能体式辅助工具(agentic assistant),它不仅擅长编码相关工作,还能协助完成所有可通过命令行执行的操作:撰写文档、运行构建脚本、搜索文件、调研相关主题等。接下来讲解 Claude Code 的核心架构、内置能力,以及高效使用技巧。
智能体工作循环
当你向 Claude 下达任务时,它会按三个阶段开展工作:收集上下文、执行操作、验证结果,这三个阶段相互融合、无缝衔接。整个过程中,Claude 可以调用各类工具 —— 无论是为理解代码搜索文件、为修改功能编辑代码,还是为验证效果运行测试。
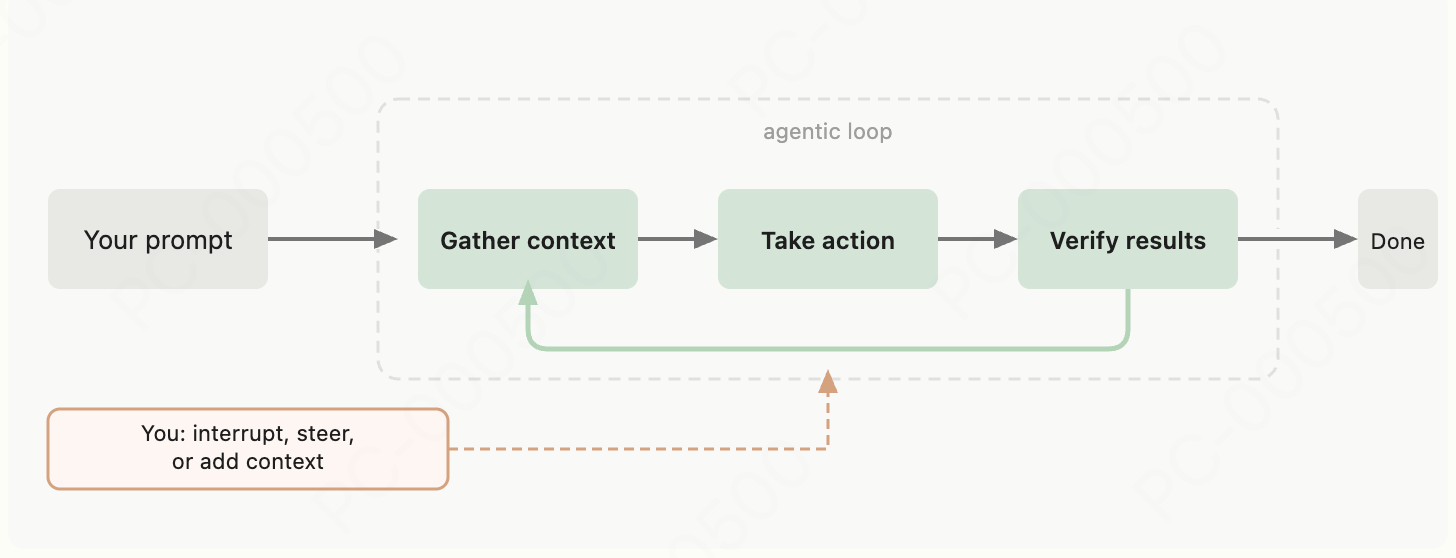
该循环会根据你的需求动态调整:
- 仅查询代码库相关问题时,可能只需要执行收集上下文阶段;
- 修复漏洞时,会反复循环三个阶段
- 代码重构时,则会涉及大量的验证结果工作
Claude 会根据上一阶段的执行结果,判断每个步骤的具体需求,串联数十个操作并在过程中实时调整、修正方向。你也是这个工作循环的一部分,可在任意节点中断流程,引导 Claude 更换处理方向、补充上下文信息,或尝试不同的解决思路。Claude 可自主完成工作,同时也能实时响应你的输入。
智能体工作循环由两大核心组件驱动:负责逻辑推理的模型,以及负责实际操作的工具。Claude Code 是承载 Claude 的 agentic harness,它提供工具、上下文管理能力和执行环境,让语言模型成为能力完备的编码智能体。
模型
Claude Code 基于 Claude 系列模型构建,依托模型实现代码理解和任务逻辑推理。Claude 能解读任意编程语言的代码,理解各组件间的关联关系,并梳理出完成目标所需的代码修改点。面对复杂任务时,它会将任务拆解为多个步骤,分步执行并根据执行结果动态调整方案。
Claude 提供多款不同的模型,各模型的特性与适用场景各有侧重:
- Sonnet 模型能出色完成绝大多数编码任务
- Opus 模型在复杂架构决策中具备更强的推理能力
可以在会话中使用 /model 命令切换模型,也可通过 claude --model <模型名> 的方式启动指定模型。
工具
工具是 Claude Code 实现智能体能力的核心。没有工具时,Claude 仅能返回文本内容;搭配工具后,Claude 可执行实际操作:读取代码、编辑文件、运行命令、网页搜索,以及与外部服务交互。每一次工具调用都会返回相关信息,这些信息会重新融入工作循环,为 Claude 的下一步决策提供依据。
Claude Code 的内置工具主要分为五大类,每一类对应一种不同的智能体操作能力:
| 工具类别 | Claude 可执行操作 |
|---|---|
| 文件操作 | 读取文件、编辑代码、创建新文件、重命名及整理文件 / 目录 |
| 搜索 | 按匹配模式查找文件、通过正则表达式搜索内容、探索整个代码库 |
| 执行 | 运行 Shell 命令、启动服务、执行测试、使用 Git 相关命令 |
| 网络 | 网页搜索、获取官方文档、查询错误信息解决方案 |
| 代码智能 | 编辑代码后查看类型错误和警告、跳转到代码定义处、查找代码引用(需安装代码智能插件) |
以上是 Claude 的核心工具能力,此外它还配备了用于启动子智能体、向用户提问、任务编排等操作的工具。完整工具列表可参考Claude 可用工具。
Claude 会根据你的指令和工作过程中的信息积累,自主选择要调用的工具。例如当你下达 修复执行失败的测试用例 指令时,Claude 可能会按以下步骤操作:
- 运行测试套件,查看具体失败的用例
- 读取错误输出信息
- 搜索相关的源码文件
- 读取文件,理解代码逻辑
- 编辑文件,修复问题
- 重新运行测试,验证修复效果
每一次工具调用都会为 Claude 补充新信息,进而指导下一步操作,这就是智能体工作循环的实际运行过程。
内置工具是 Claude Code 的能力基础,你可通过多种方式扩展其功能:
- 通过
技能(Skills)拓展 Claude 的知识储备 - 通过
MCP对接外部服务 - 通过
钩子(Hooks)自动化工作流、 - 通过子智能体(Subagents) 下放任务处理权
这些扩展功能构建在核心智能体工作循环之上,形成一层扩展能力层。
Claude 会访问什么
当你在某一目录中执行claude命令时,Claude Code 将获得以下访问权限:
- 你的项目:该目录及子目录下的所有文件,经你授权后也可访问其他路径的文件
- 你的终端:所有你能在终端执行的命令 —— 构建工具、Git、包管理器、系统工具、自定义脚本,只要能通过命令行执行,Claude 都可操作
- 你的 Git 状态:当前分支、未提交的修改、近期的提交历史
- 你的
CLAUDE.md文件:一个 Markdown 文件,可在其中存储项目专属的指令、编码规范和上下文信息,Claude 会在每个会话启动时读取 - 自动记忆(Auto memory):Claude 会在工作过程中自动保存学习成果,比如项目的代码模式、你的使用偏好等。每个会话启动时,都会加载 MEMORY.md 文件的前 200 行内容
- 你配置的扩展:用于对接外部服务的 MCP 服务器、用于工作流的 skills、用于任务下放的 subagents、用于浏览器交互的 Claude Chrome
正因 Claude 能访问整个项目,它才具备跨文件的工作能力。当你下达 修复认证模块的漏洞 指令时,它会搜索相关文件、读取多个文件以理解上下文、跨文件协同编辑代码、运行测试验证修复效果,若你有要求,还会完成代码提交。这一点与仅能查看当前文件的内联编码助手有本质区别。
会话操作
Claude Code 会在工作时本地保存对话记录,所有的消息、工具调用记录和执行结果都会被存储,这让会话的回退(rewinding)、恢复(resuming)和分叉(forking)成为可能。在 Claude 修改代码前,还会对受影响的文件创建快照,方便你在需要时回滚版本。
每个会话都是相互独立的,新会话会启动全新的上下文窗口,不会携带之前会话的对话历史。不过 Claude 可通过自动记忆实现跨会话的学习成果持久化,你也可在 CLAUDE.md 中添加自定义的持久化指令。
跨分支工作
Claude Code 的每一次对话都是与当前目录绑定的会话,恢复会话时,仅能看到该目录下的历史会话。Claude 能识别你当前 Git 分支的文件,当你切换分支时,Claude 会读取新分支的文件,但对话历史会保留,即便切换分支,Claude 也能记住你们之前的讨论内容。
由于会话与目录绑定,你可通过 git worktrees 为不同分支创建独立的目录,从而实现多个 Claude 会话的并行运行。
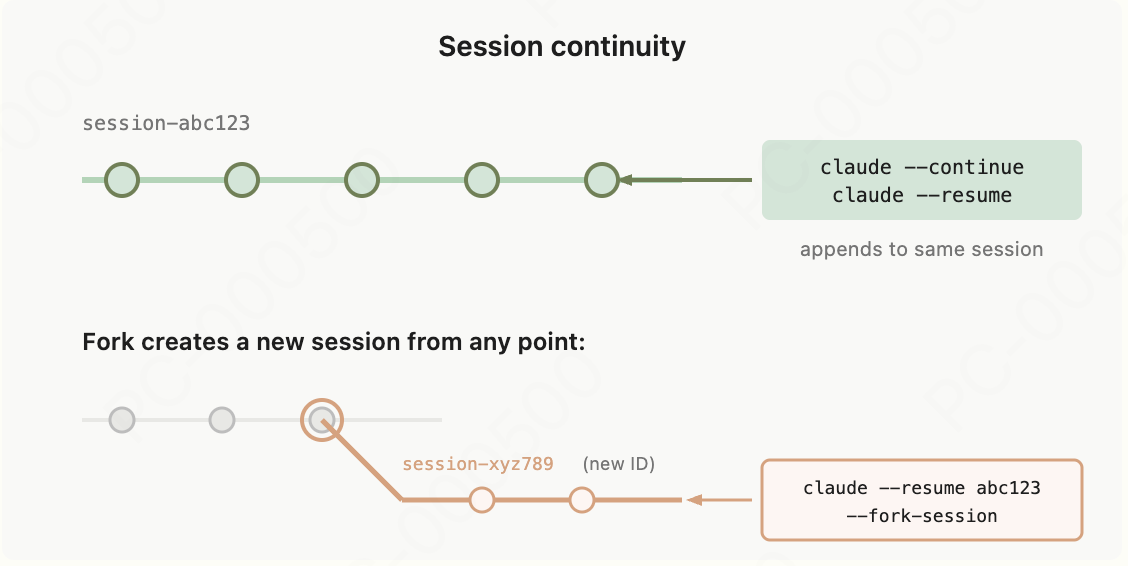
恢复或分叉会话
使用 claude --continue 或 claude --resume 命令恢复会话时,会沿用原有的会话 ID,从上次中断的位置继续工作,新消息会追加到原有对话中。恢复后,完整的对话历史会被还原,但会话级的权限设置不会保留,需要你重新授权。
若想另辟蹊径尝试不同的解决思路,且不影响原会话,可使用 --fork-session 参数:
1 | claude --continue --fork-session |
该命令会创建新的会话 ID,同时保留截至当前的所有对话历史,原会话则保持不变。与恢复会话相同,分叉后的新会话也不会继承原有的会话级权限设置。
多终端运行同一会话的注意事项:若在多个终端中恢复同一个会话,所有终端都会向同一个会话文件写入内容,不同终端的消息会相互交错,就像两个人在同一本笔记本上写字。这种操作不会造成文件损坏,但会让对话记录变得混乱:
- 会话进行中,每个终端只能看到自身发送的消息
- 但当你后续再次恢复该会话时,会看到所有交错的消息记录
- 若想从同一初始点并行开展工作,建议使用
--fork-session为每个终端创建独立的干净会话
上下文窗口
Claude 的上下文窗口会存储以下内容:
- 对话历史
- 文件内容
- 命令输出
- CLAUDE.md 文件内容
- 已加载的技能
- 以及系统指令
随着工作的推进,上下文窗口的空间会逐渐被占满,Claude 会自动对内容进行压缩,但会话初期的部分指令可能会丢失。建议将持久化的规则写入 CLAUDE.md,并可通过 /context 命令查看当前上下文的空间占用情况。
当上下文占用量接近上限时,Claude Code 会自动进行管理:首先清理较早的工具输出记录,若仍需释放空间,则会将对话内容进行总结。你的请求内容和关键代码片段会被保留,而会话初期的详细指令可能会丢失。因此建议将持久化的规则写入 CLAUDE.md,而非依赖对话历史。
若想自定义内容压缩时的保留规则,可在 CLAUDE.md 中添加 Compact Instructions 章节,或者通过带 focus 的 /compact 命令进行设置(例如 /compact focus on the API changes,即压缩时聚焦保留 API 相关的修改内容)。
执行 /context 命令可查看上下文的具体空间占用情况。需要注意的是,MCP 服务器会为每一次请求添加工具定义,因此仅配置几个 MCP 服务器,就可能在你开始工作前占用大量的上下文空间,可通过 /mcp 命令查看各服务器的上下文占用成本。
除了自动压缩,你还可通过其他功能控制加载到上下文窗口的内容,优化空间占用。
- 技能(Skills):按需加载。会话启动时,Claude 仅会读取技能的描述信息,只有在调用技能时,才会加载其完整内容。对于需要手动调用的技能,可设置
disable-model-invocation: true,让技能描述信息在你需要前不占用上下文空间 - 子智能体(Subagents):拥有独立的全新上下文窗口,与主会话的上下文完全隔离,其工作过程不会造成主会话的上下文臃肿。子智能体完成工作后,仅会向主会话返回一份工作总结。这种隔离性,让子智能体成为处理长会话任务的理想选择
各个功能的上下文占用成本可以参考 Context cost by feature,上下文管理中减少 token 的使用技巧可以参考这里。
借助检查点与权限保障操作安全
Claude 配备了两大安全机制:检查点(Checkpoints)支持撤销文件修改,权限(Permissions)控制 Claude 在没有询问的情况下能够执行的操作。
Claude 对文件的所有编辑操作都是可撤销的。在编辑任意文件前,Claude 会先为文件当前内容创建快照。若操作出现问题,连续按两次 Esc 键即可回滚到之前的状态,也可直接让 Claude 执行撤销操作。
检查点是与本地会话绑定的,与 Git 版本控制相互独立,仅对文件修改操作生效。对于影响远程系统的操作(如操作数据库、调用 API、部署服务),无法通过检查点撤销,这也是 Claude 在执行带有外部副作用的命令前,会向你征求授权的原因。
连续按 Shift+Tab 键,可在不同的权限模式间切换:
- 默认模式:Claude 编辑文件和执行 Shell 命令前,都会向你征求授权
- 自动接受编辑模式:Claude 编辑文件时无需授权,执行命令仍需征求授权
- 规划模式:Claude 仅能使用只读工具,会先制定执行方案,待你批准后再执行
你也可在 .claude/settings.json 文件中配置信任命令,让 Claude 执行这些命令时无需反复征求授权。权限设置可灵活适配不同范围的需求,从企业级的全局策略,到个人的自定义偏好均可配置。
高效使用 Claude Code 的技巧
以下技巧能帮助你借助 Claude Code 获得更优的工作成果。
- 直接向 Claude 询问使用方法:Claude Code 本身就能教你如何使用它,你可直接提出问题,例如
如何合理组织 CLAUDE.md 的结构 - Claude 还提供了内置命令,引导你完成各类配置:
- /init:引导你为项目创建专属的 CLAUDE.md 文件
- /agents:协助你配置自定义子智能体
- /doctor:诊断安装过程中出现的常见问题
- Claude Code 支持自然的对话式交互,你无需撰写完美的指令。可以先说出你的核心需求,再根据 Claude 的执行结果逐步细化、调整。当第一次尝试的结果不符合预期时,无需重新开始,只需通过对话迭代优化即可
- 你可在任意节点中断 Claude 的工作。若发现它的处理方向有误,直接输入你的修正意见并按下回车,Claude 会立即停止当前操作,并根据你的输入调整解决思路,无需等待它完成当前操作,也无需重新发起会话
- 你的初始提示越精准、具体,后续需要的修正就越少
- 当 Claude 能自行验证工作成果时,执行效果会更好。你可在提示中包含测试用例、粘贴预期的界面截图,或明确定义你需要的输出结果
- 若涉及视觉相关的开发工作,可粘贴设计稿截图,让 Claude 将实现效果与设计稿进行对比验证
- 面对复杂问题时,将调研分析与编码实现分开进行。先切换到规划模式(连续按两次Shift+Tab)。先评审 Claude 制定的方案,通过对话细化、优化,再让它执行编码实现。这种
先探索,后实现的两步式方法,比直接让 Claude 写代码的效果更好 - 把 Claude 当作能力出众的同事,向它提供上下文和工作方向,然后信任它去梳理具体的实现细节
扩展 Claude Code
Claude Code 将 能对代码进行逻辑推理的大模 与 内置工具 深度结合,这些工具可实现文件操作、内容搜索、命令执行和网络访问,足以覆盖绝大多数编码任务。Cluade Code 同时也提供可扩展能力,通过自定义配置为 Claude 补充专属知识、对接外部服务、实现工作流自动化的各类功能。
功能总览
- CLAUDE.md:添加持久化上下文,Claude 在每一次会话中都会读取
- 技能(Skills):添加可复用的知识和可调用的工作流
- MCP:实现 Claude 与外部服务、工具的对接
- 子智能体(Subagents):在独立的上下文环境中运行专属工作循环,仅向主会话返回汇总结果
- 智能体团队(Agent teams):协调多个独立的 Claude Code 会话,通过共享任务和点对点消息完成协作
- 钩子(Hooks):完全在工作循环外运行的确定性脚本,实现自动化触发
- 插件(Plugins)与应用市场(marketplaces):将上述各类功能打包封装,实现便捷分发和部署
Skills 是最灵活的扩展方式。一个技能本质是一个 Markdown 文件,内含专属知识、工作流或操作指令。你可通过 /deploy 这类命令手动调用技能,Claude 也会在场景匹配时自动加载。技能既可在当前对话中运行,也可通过子智能体在独立的上下文环境中执行。
按目标匹配功能
Claude Code 的扩展功能覆盖多类使用场景:从 Claude 每次会话都会读取的常驻上下文,到可按需调用的专属能力,再到基于特定事件触发的后台自动化脚本。下表梳理了所有扩展功能的用途及适用场景,帮你精准匹配。
| 功能 | 核心作用 | 适用场景 | 示例 |
|---|---|---|---|
| CLAUDE.md | 每次对话都会加载的持久化上下文 | 项目编码规范、「始终遵循 X 规则」的硬性要求 | 「使用 pnpm,禁止使用 npm;代码提交前必须执行测试」 |
| 技能(Skill) | 为 Claude 补充可调用的指令、知识和工作流 | 可复用的内容、参考文档、重复性的标准化任务 | 执行 /review 触发代码评审检查清单;存储含接口规范的 API 文档技能 |
| 子智能体(Subagent) | 独立的执行上下文,仅返回汇总后的结果 | 上下文隔离、并行处理任务、专属的专业化处理场景 | 需读取大量文件但仅需提炼核心结论的调研任务 |
| 智能体团队(Agent teams) | 协调多个独立的 Claude Code 会话协同工作 | 并行调研、新功能开发、多假设并行的调试工作 | 同时启动多个评审智能体,分别检查代码的安全性、性能和测试覆盖率 |
| MCP | 实现与外部服务的对接 | 需访问外部数据或执行外部操作的场景 | 查询自有数据库、向 Slack 发送消息、操控浏览器 |
| 钩子(Hook) | 基于特定事件触发的确定性脚本 | 可预期的自动化操作(无需大模型参与) | 每次文件编辑后自动执行 ESLint 代码检查 |
插件(Plugins)是功能的打包封装层,可将技能、钩子、子智能体和 MCP 服务器整合为一个可一键安装的单元。插件中的技能会做命名空间化处理(如 /my-plugin:review),确保多个插件共存时不会产生冲突。如果你需要在多个代码仓库中复用同一套配置,或想将自定义功能通过应用市场分发给他人,插件是最佳选择。
建议将 CLAUDE.md 的内容控制在 200 行以内。如果内容过多,可将参考型内容迁移至技能,或拆分到 .claude/rules/ 目录的文件中。这里再介绍下 .claude/rules/,它精简 CLAUDE.md 的内容,带 paths 前置配置的规则仅在 Claude 处理匹配文件时加载,节省上下文空间;
- 加载方式:每次会话自动加载,或打开匹配文件时加载
- 作用范围:可按文件路径限定作用范围
- 最佳适用场景:特定语言或特定目录的编码指南
另外需要注意子智能体和智能体团队的区别,两者均可实现工作并行处理,但架构设计截然不同:
- 子智能体在主会话内运行,但拥有独立的上下文窗口,仅向主会话的上下文返回结果;
- 智能体团队由多个独立的 Claude Code 会话组成,会话间可直接通信协作,每个团队成员都是独立的 Claude 实例
使用原则:
- 子智能体:适用于需要快速处理的聚焦型任务,如调研某个问题、验证某个结论、评审单个文件。子智能体完成工作后仅返回汇总结果,让主会话的对话记录保持简洁;
- 智能体团队:适用于团队成员需共享发现、相互验证、自主协调的场景,如多假设并行的调研、代码的并行评审、各模块独立开发的新功能开发工作
当你运行多个并行的子智能体但遇到上下文空间限制,或子智能体之间需要相互通信时,就可以考虑切换为智能体团队。
MCP 与技能的核心区别则是:MCP 的核心作用是实现 Claude 与外部服务的对接,而技能的核心作用是拓展 Claude 的知识储备,包括如何高效使用这些外部服务的方法:
- MCP:实现 Claude 与外部服务对接的协议
- 技能:存储知识、工作流和参考资料的载体
两者解决不同的问题,且可完美结合使用:
- MCP 为 Claude 提供与外部系统交互的能力,没有 MCP,Claude 无法查询你的自有数据库,也无法向 Slack 发送消息;
- 技能为 Claude 补充高效使用这些外部工具的知识,同时提供可通过
/<技能名>触发的标准化工作流。例如,一个技能可存储团队的数据库表结构和查询规范,或封装/post-to-slack工作流并内置团队的消息格式规则
例如通过 MCP 服务器实现 Claude 与自有数据库的对接,再通过一个技能向 Claude 传授数据模型、常用查询模式,以及不同任务对应的查询表名。
理解功能是如何分层的
Claude Code 的各类功能可在多个层级定义:全局用户级、项目级、插件级,或通过企业托管策略配置。你可在子目录中嵌套创建 CLAUDE.md 文件,或在单体仓库的指定包中放置技能文件。当同一功能在多个层级都有定义时,将遵循以下层级加载规则:
-
CLAUDE.md:叠加式加载,所有层级的内容会同时加入 Claude 的上下文
-
技能与子智能体:按名称覆盖
- 当同一名称的技能/子智能体在多个层级定义时,会按优先级确定最终生效的配置
- 技能的优先级:托管级 > 用户级 > 项目级
- 子智能体的优先级:托管级 > 命令行参数 > 项目级 > 用户级 > 插件级
- 插件中的技能会做命名空间化处理,避免命名冲突
-
MCP 服务器:按名称覆盖
- 优先级:本地级 > 项目级 > 用户级
-
钩子:合并式加载
- 所有已注册的钩子,只要匹配触发事件就会执行,与定义的层级无关
功能的组合使用
每类扩展功能都有其专属的适用场景:CLAUDE.md 处理常驻上下文,技能处理按需加载的知识和工作流,MCP 处理外部服务对接,子智能体处理上下文隔离,钩子处理自动化操作。实际使用中,可根据自身工作流组合使用各类功能,实现效能最大化。
例如,你可通过 CLAUDE.md 配置项目编码规范,通过技能封装部署工作流,通过 MCP 对接自有数据库,再通过钩子实现每次文件编辑后自动执行代码检查。让每类功能发挥其核心优势,各司其职。
| 组合模式 | 工作原理 | 应用示例 |
|---|---|---|
| 技能 + MCP | MCP 实现外部服务对接,技能教 Claude 如何高效使用该服务 | MCP 对接自有数据库,技能存储数据库表结构和查询规范 |
| 技能 + 子智能体 | 技能触发多个子智能体,实现任务并行处理 | 执行 /review 技能,自动启动安全、性能、编码风格三类子智能体,在独立上下文环境中并行评审 |
| CLAUDE.md + 技能 | CLAUDE.md 存储常驻的硬性规则,技能存储按需加载的参考资料 | CLAUDE.md 中定义遵循团队 API 编码规范,技能中存储完整的 API 编码风格指南 |
| 钩子 + MCP | 钩子触发后,通过 MCP 执行外部操作 | 配置文件编辑后触发的钩子,当 Claude 修改核心文件时,自动通过 MCP 向 Slack 发送通知 |
了解上下文成本
你添加的每一项扩展功能,都会占用 Claude 的部分上下文空间。过多的功能不仅会占满上下文窗口,还会引入无关信息,导致 Claude 的执行效率下降:比如技能无法正常触发,或 Claude 忘记项目的编码规范。理解各类功能的上下文成本取舍,能帮你搭建更高效的 Claude Code 配置。
| 功能 | 加载时机 | 加载内容 | 上下文成本 |
|---|---|---|---|
| CLAUDE.md | 会话启动时 | 完整内容 | 每次请求都会占用 |
| 技能(Skills) | 会话启动时 + 实际使用时 | 会话启动时加载描述,实际使用时加载完整内容 | 较低(每次请求仅加载描述)* |
| MCP 服务器 | 会话启动时 | 所有工具的定义和数据模型 schema | 每次请求都会占用 |
| 子智能体(Subagents) | 触发时 | 加载指定技能的全新独立上下文 | 与主会话隔离,不占用主上下文 |
| 钩子(Hooks) | 触发时 | 无(在外部独立运行) | 零成本,除非钩子返回的内容作为消息加入会话 |
- 默认情况下,会话启动时会加载技能的描述信息,方便 Claude 判断何时自动触发
- 如果在技能的前置配置中设置disable-model-invocation: true,则该技能会完全隐藏,直到你手动调用才会加载。这类技能的上下文成本为零
了解功能的加载方式
各类功能会在会话的不同阶段加载,下文将分模块说明各类功能的加载时机,以及哪些内容会被加入上下文窗口。
| 加载阶段 | 核心功能 | 加载细节 | 上下文特点 |
|---|---|---|---|
| 会话启动时 | CLAUDE.md、MCP 服务器、技能(默认) | CLAUDE.md 加载完整内容;MCP 服务器加载所有工具定义和 schema;技能仅加载描述信息 | 常驻上下文,每次请求都会占用 |
| 实际使用时 | 技能 | 加载技能的完整内容 | 按需加载,仅使用时占用上下文 |
| 隔离环境中 | 子智能体 | 加载全新的独立上下文,含指定技能、CLAUDE.md 和 Git 状态 | 与主会话完全隔离,不占用主上下文 |
| 事件触发时 | 钩子 | 无加载内容,在外部独立运行脚本 | 零上下文成本,仅返回结果时可能占用 |
对于 CLAUDE.md:
- 加载时机:会话启动时
- 加载内容:所有层级(托管级、用户级、项目级)的 CLAUDE.md 完整内容
- 继承规则:Claude 会读取当前工作目录到根目录的所有 CLAUDE.md,在访问子目录文件时,会自动发现并加载子目录中的嵌套 CLAUDE.md
- 实用技巧:将 CLAUDE.md 的内容控制在约 500 行以内,把参考型内容迁移至技能,通过按需加载节省上下文空间
技能是 Claude 工具集中的扩展能力,分为参考型(如 API 编码风格指南)和操作型(如通过/deploy触发的部署工作流)。Claude Code 内置了 /simplify(代码简化)、/batch(批量操作)、/debug(代码调试)等技能,可直接使用;你也可根据需求自定义技能。Claude 会在场景匹配时自动使用技能,你也可手动直接调用。
- 加载时机:取决于技能的配置。默认情况下,会话启动时加载描述信息,实际使用时加载完整内容;对于仅支持用户手动调用的技能(设置disable-model-invocation: true),手动调用前不会加载任何内容
- 加载内容:对于 Claude 可自动触发的技能,每次请求都会加载技能的名称和描述;当你通过
/<技能名>手动调用,或 Claude 自动加载时,技能的完整内容会被加入当前对话的上下文 - Claude 的技能选择逻辑:Claude 会将当前任务与技能描述进行匹配,判断相关性
- 如果技能描述模糊或存在重叠,Claude 可能会加载错误的技能,或遗漏可用的技能
- 如需指定 Claude 使用某一技能,直接通过
/<技能名>调用即可 - 设置
disable-model-invocation: true的技能,在手动调用前对 Claude 完全不可见
- 上下文成本:使用前成本较低;仅支持手动调用的技能,调用前上下文成本为零
- 子智能体中的技能:技能在子智能体中的工作方式不同:并非按需加载,而是在子智能体启动时,将指定的技能完整预加载到其上下文环境中。子智能体不会继承主会话的技能,需手动显式指定
- 实用技巧:对于带有副作用的技能,建议设置
disable-model-invocation: true。这样既可以节省上下文空间,又能确保只有你能触发该技能,避免误操作
对于 MCP 服务器:
- 加载时机:会话启动时
- 加载内容:所有已连接服务器的工具定义和 JSON 数据模型 schema
- 上下文成本:工具搜索(Tool search)功能(默认开启)会先加载占比不超过 10% 上下文空间的 MCP 工具,剩余工具会在需要时再加载,有效控制成本。
- 可靠性说明:MCP 连接可能会在会话过程中中断(无提示)。服务器断开后,其对应的工具会直接消失,Claude 可能会尝试调用已不存在的工具。如果发现 Claude 无法使用之前可正常访问的 MCP 工具,可执行
/mcp命令检查连接状态 - 实用技巧:执行/mcp命令可查看各 MCP 服务器的令牌成本,及时断开未在使用的服务器,节省上下文空间
对于子智能体(Subagents):
- 载时机:按需触发,当你或 Claude 为某一任务启动子智能体时
- 加载内容:全新的独立上下文,包含以下内容:
- 系统提示词(与主智能体共享,提升缓存效率)
- 智能体
skills:字段中指定的所有技能完整内容 - 从主智能体继承的 CLAUDE.md 和 Git 状态
- 主智能体在提示词中传递的所有上下文信息
- 上下文成本:与主会话完全隔离,不占用主会话的上下文空间。子智能体不会继承主会话的对话历史和已调用的技能
- 实用技巧:对于无需主会话完整对话上下文的工作,建议使用子智能体。其上下文隔离的特性,可有效避免主会话的上下文臃肿
钩子(Hooks):
- 加载时机:事件触发时。钩子会在特定的生命周期事件中执行,如工具执行、会话开始 / 结束、提示词提交、权限请求、上下文压缩等
- 加载内容:默认无加载内容,钩子作为外部脚本独立运行
- 上下文成本:零成本,除非钩子的返回结果作为消息被加入当前对话的上下文
- 实用技巧:钩子非常适合实现副作用操作(如代码检查、日志记录),这类操作无需影响 Claude 的上下文,仅需完成自动化触发即可
Claude 如何记住你的项目
每个 Claude Code 会话都以一个新的上下文窗口开始。laude Code 拥有两种可跨会话持久化的记忆类型:
- CLAUDE.md 文件:由你编写和维护的 Markdown 文件,内含让 Claude 遵循的操作指令、规则和使用偏好。
- 自动记忆(Auto memory):Claude 会自动保存项目模式、核心命令、你的使用偏好等实用上下文信息,该内容可跨会话持久化
CLAUDE.md 与自动记忆的对比
Claude Code 拥有两种互补的记忆系统。两者都在每次对话开始时加载。Claude 将它们视为上下文,而非强制配置。你的指令越具体、越简洁,Claude 遵循得就越一致。
| 特性 | CLAUDE.md 文件 | 自动记忆 |
|---|---|---|
| 编写者 | 你 | Claude |
| 内容 | 指令和规则 | 学习到的模式和经验 |
| 作用范围 | 项目、用户或组织 | 每个工作树 |
| 加载方式 | 每次会话完整加载 | 每次会话加载前 200 行 |
| 适用场景 | 编码标准、工作流程、项目架构 | 构建命令、调试洞察、Claude 发现的偏好 |
当你想引导 Claude 的行为时,使用 CLAUDE.md 文件。自动记忆让 Claude 无需手动操作即可从你的纠正中学习。子智能体(Subagents)也可以维护自己的自动记忆。
CLAUDE.md 文件
| 作用范围 | 位置 | 用途 | 使用示例 | 共享对象 |
|---|---|---|---|---|
| 托管策略 | • macOS: /Library/Application Support/ClaudeCode/CLAUDE.md• Linux 和 WSL: /etc/claude-code/CLAUDE.md |
由 IT/DevOps 管理的组织级指令 | 公司编码标准、安全策略、合规要求 | 组织内所有用户 |
| 项目指令 | ./CLAUDE.md 或 ./.claude/CLAUDE.md |
团队共享的项目指令 | 项目架构、编码标准、常见工作流程 | 通过源代码控制与团队成员共享 |
| 用户指令 | ~/.claude/CLAUDE.md |
适用于所有项目的个人偏好 | 代码风格偏好、个人工具快捷方式 | 仅你自己(所有项目) |
| 本地指令 | ./CLAUDE.local.md |
个人项目特定偏好,不提交到 git | 你的沙盒 URL、首选测试数据 | 仅你自己(当前项目) |
对于大型项目,你可以使用项目规则 project rules 将指令拆分为特定主题的文件。规则允许你将指令限定到特定文件类型或子目录。
设置项目 CLAUDE.md
项目 CLAUDE.md 可以存放在 ./CLAUDE.md 或 ./.claude/CLAUDE.md。创建此文件并添加适用于项目所有成员的指令:构建和测试命令、编码标准、架构决策、命名约定和常见工作流程。这些指令通过版本控制与团队共享,因此应聚焦于项目级标准而非个人偏好。
运行 /init 命令可自动生成初始的 CLAUDE.md 文件。Claude 会分析你的代码库,并创建一个包含其识别出的构建命令、测试说明以及项目约定的文件。若 CLAUDE.md 文件已存在,/init 命令会给出优化建议,而非覆盖原有文件。你可在此基础上补充 Claude 无法自行识别的定制化说明,进一步完善该文件。
编写有效的指令
每个会话启动时,CLAUDE.md 文件会被加载到上下文窗口中,与你的对话内容一同消耗令牌(Token)。由于这些文件仅作为上下文参考,而非强制生效的配置项,因此你编写指令的方式会直接影响 Claude 遵循这些指令的可靠性。具体、简洁、结构清晰的指令效果最佳。
-
篇幅要求:每个 CLAUDE.md 文件建议控制在 200 行以内。文件过长会占用更多上下文空间,同时降低 Claude 遵循指令的程度。若你的指令内容不断增多,可通过导入(imports)功能或拆分至
.claude/rules/目录下的文件来管理。 -
结构要求:使用 Markdown 标题和项目符号对相关指令进行分组。Claude 解析结构的方式与人类阅读一致:条理清晰的分节内容,远比密集的大段文字更易被遵循
-
明确性要求:编写的指令需足够具体,便于验证执行效果。例如
- 应写
使用 2 个空格缩进,而非正确格式化代码 - 应写
提交前运行 npm test 命令,而非测试你的修改内容; - 应写
API 处理器文件存放于 src/api/handlers/ 目录下,而非保持文件有序
- 应写
-
一致性要求:若两条规则相互冲突,Claude 可能会随机选择其中一条执行。请定期检查你的 CLAUDE.md 文件、子目录中嵌套的 CLAUDE.md 文件,以及 .claude/rules/ 目录下的文件,移除过时或冲突的指令。
-
在单体仓库(monorepo)中,可使用 claudeMdExcludes 配置项跳过其他团队的、与你工作无关的 CLAUDE.md 文件
CLAUDE.md 文件加载机制
Claude Code 会从当前工作目录开始,向上遍历目录树,依次检查沿途每个目录中是否存在 CLAUDE.md 和 CLAUDE.local.md 文件。这意味着,如果你在 foo/bar/ 目录下运行 Claude Code,它会同时加载:
- foo/bar/CLAUDE.md
- foo/CLAUDE.md
Claude 还会识别当前工作目录子目录中的 CLAUDE.md 文件。这类文件不会在启动时直接加载,而是在 Claude 读取对应子目录里的文件时,才会被纳入上下文。
- 如果你在大型
单体仓库(monorepo)中工作,且被加载到了其他团队的 CLAUDE.md 文件,可以使用 claudeMdExcludes 来跳过这些无关文件。 --add-dir标志允许 Claude 访问主工作目录之外的其他目录。默认情况下,这些目录中的 CLAUDE.md 文件不会被加载- 如果需要同时加载这些额外目录中的 CLAUDE.md 文件,可设置环境变量
CLAUDE_CODE_ADDITIONAL_DIRECTORIES_CLAUDE_MD
1 | CLAUDE_CODE_ADDITIONAL_DIRECTORIES_CLAUDE_MD=1 claude --add-dir ../shared-config |
使用 .claude/rules/ 组织规则
对于大型项目,你可以通过 .claude/rules/ 目录将指令拆分为多个文件,让规则模块化,便于团队维护。规则还可以限定作用路径,仅在 Claude 处理匹配文件时才加载到上下文,减少干扰并节省上下文空间。
- 规则会在每次会话启动时,或在打开匹配文件时加载到上下文
- 对于不需要常驻上下文的任务专属指令,建议使用
技能(skills),它们仅在你主动调用,或 Claude 判断与当前提示相关时才加载
将 Markdown 文件放入项目的 .claude/rules/ 目录。每个文件专注一个主题,并使用语义化文件名,例如 testing.md 或 api-design.md。所有 .md 文件会被递归识别,因此你可以按子目录进一步分类,如 frontend/ 或 backend/:
1 | your-project/ |
可以通过带 paths 字段的 YAML 前置信息,将规则限定到特定文件。这类条件规则仅在 Claude 处理匹配指定模式的文件时生效。不带路径前置信息的规则,会在启动时加载,优先级与 .claude/CLAUDE.md 相同。
1 | --- |
在 paths 字段中使用 glob 模式匹配文件后缀、目录或组合条件:
**/*.ts:任意目录下所有 TypeScript 文件src/**/*:src/ 目录下所有文件.md:项目根目录下的 Markdown 文件src/components/*.tsx:指定目录下的 React 组件
可指定多个模式,并使用大括号扩展一次性匹配多种后缀:
1 | --- |
.claude/rules/ 目录支持符号链接(symlink),你可以维护一套共享规则,并链接到多个项目中。符号链接会被正常解析加载,循环链接会被自动检测并优雅处理。
1 | ln -s ~/shared-claude-rules .claude/rules/shared |
用户级规则是放在 ~/.claude/rules/ 中的个人规则,会对本机所有项目生效。适用于与项目无关的个人偏好。用户级规则会在项目规则之前加载,因此项目规则优先级更高。
大型团队的 CLAUDE.md 管理
对于那些跨团队部署 Claude Code 的组织,可以对指令进行集中管理,并控制哪些 CLAUDE.md 文件会被加载。组织可以部署一份集中管理的 CLAUDE.md,对同一台机器上的所有用户生效。该文件无法被个人设置排除。
-
在托管策略路径(managed policy location)下创建文件
- macOS: /Library/Application Support/ClaudeCode/CLAUDE.md
- Linux 和 WSL: /etc/claude-code/CLAUDE.md
-
通过配置管理系统分发:使用 MDM, Group Policy, Ansible 或类似工具,将文件分发到所有开发者机器。
在大型单体仓库(monorepo)中,上层目录的 CLAUDE.md 可能包含与当前工作无关的指令。通过 claudeMdExcludes 设置,可以按路径或 glob 模式跳过指定文件。
例如将配置写入 .claude/settings.local.json,使排除规则仅在本机生效:
1 | { |
- 你可以在任意配置层级设置 claudeMdExcludes
- 托管策略级的 CLAUDE.md 无法被排除,以确保组织级指令始终生效,不受个人设置影响
自动记忆(Auto Memory)
自动记忆允许 Claude 在跨会话中自动积累知识,无需你手动编写任何内容。Claude 会在工作过程中自动为自己记录笔记:构建命令、调试思路、架构说明、代码风格偏好和工作流习惯等。Claude 并非每个会话都保存内容,它会根据信息在未来对话中是否有用,来判断是否值得记忆。
自动记忆默认开启,要切换状态,可以在会话中打开 /memory 并使用自动记忆开关,或在项目设置中配置 autoMemoryEnabled。
1 | { |
如需通过环境变量禁用自动记忆,设置:
1 | CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 |
每个项目都会在以下路径拥有独立的记忆目录:~/.claude/projects/<project>/memory/。其中 <project> 路径由 Git 仓库决定,因此同一仓库下的所有工作树和子目录共享同一个自动记忆目录。该目录包含一个入口文件 MEMORY.md 和若干可选的主题文件:
1 | ~/.claude/projects/<project>/memory/ |
每次对话开始时,只会加载 MEMORY.md 的前 200 行,超过 200 行的内容不会在会话启动时加载。Claude 会通过将详细笔记移至独立主题文件,来保持 MEMORY.md 简洁。
debugging.md、patterns.md 等主题文件不会在启动时加载,Claude 只有在需要相关信息时,才会通过标准文件工具按需读取:
- Claude 会在会话期间读写记忆文件
- 当你在 Claude Code 界面看到
正在写入记忆或已召回记忆时,说明 Claude 正在更新或读取~/.claude/projects/<project>/memory/
自动记忆文件都是普通 Markdown,你可以随时编辑或删除。运行 /memory 即可在会话内浏览并打开记忆文件。/memory 命令可以:
- 列出当前会话加载的所有 CLAUDE.md 和规则文件
- 开启/关闭自动记忆
- 提供打开自动记忆文件夹的快捷方式
- 选择任意文件在编辑器中打开
当你让 Claude 记住某事,例如:
始终使用 pnpm,不要用 npm记住 API 测试需要本地 Redis 实例
1 | ❯ 始终使用 gcc -g 构建 c 程序 |
常见问题排查(Troubleshoot)
以下是 CLAUDE.md 和自动记忆最常见的问题及调试方法。