这篇文章将介绍 vi 编辑器中的全局替换命令。通过全局替换命令,能够自动替换文件中的某个模式。全局替换一般会用到两个 ex 命令::g (global),:s (substitute)。
替换命令
替换命令的语法如下::s/old/new/。其中斜线用来分隔命令的各部分,如果斜线位于该命令的最后一个字符,则该斜线可以省略。该命令可以将当前行中第一个出现的 old 模式替换为new。
这个命令还有几种变体:
:s/old/new/g:会将当前行中的每一个 old 模式替换为 new- 在 s 前面加上行地址,可以指定替换命令的影响行范围。例如:
%s/old/new/g可以将文件中所有的 old 模式替换为 new
确认替换
有时我们想在替换之前先人工确认下,此时可以在替换命令的结尾加上 c 选项(代表 “confirm”),从而在每一次替换之前进行确认。如下图所示:

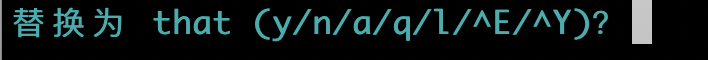
此时输入 y ,即可进行替换。输入 n,则本处不替换。
与上下文有关的替换
考虑这样一种情况:按照某个模式进行搜索,当找到包含该模式的某行时,将该行中的另一个字符串进行替换。即搜索模式并不等于被替换的字符串。此时可以通过如下命令实现 :g/pattern/s/old/new/g。其中第一个 g 代表对文件中的所有行起作用,patten 即为搜索模式。当用于搜索的模式和用于替换的模式一样时,就没有必要重复输入了,此时可以简写为 :g/string/s//new/g,该命令的效果等价于如下命令::%s/string/new/g。
模式匹配
除了可以搜索常量字符串,vi 编辑器还可以搜索可变的模式,即正则表达式。正则表达式是一种将普通字符和特殊的元字符结合起来的表达式。
用在搜索模式中的元字符
- .:匹配任意一个单一字符(换行符除外)
- :匹配 0 到无穷多个前一个字符,因此 . 可匹配任意数量的任何字符
- ^:当 ^ 出现在正则表达式的开头时,代表后面的内容必须出现在一行的开头。如果 ^ 不是出现在正则表达式的开头,则没有特殊含义
- $:当 $ 出现在正则表达式的结尾时,代表前面的内容必须出现在一行的结尾。如果 $ 不是出现在正则表达式的结尾时,则没有特殊含义
- \:转义字符,将后面的特殊字符当成一般的字符
- []:匹配方括号里的任何一个字符。如果匹配目标为一个范围的字符,则可用第一个字符加上连字符,再加上最后一个字符来表示。而且方括号内可以包含两个以上的范围,也可以混合使用范围和单个字符。符号 ^ 作为方括号内的第一个字母时,表示匹配任何一个不在指定字符范围内的字符
- ():将 ( 与 ) 之间的匹配内容保存到特殊的空间(称为保留缓冲区)。使用这种方法可以保存任何一行中的最多 9 个模式,这些保存的模式以后可以用 \1 到\9 的序列引用
- <>:匹配出以某些字符开头(<)或结尾(>)的单词
POSIX 方括号表达式
方括号除了可以用于匹配位于方括号内的任何一个字符,POSIX 引进了另外的方法,用于比较非英文字母的字符。在 POSIX 标准中,方括号内的字符组称为方括号表达式。方括号表达式中,除了可以有文字字符,还可以包括其它元素:
- 字符类:POSIX字符类包罗了用 [: 与 :] 括起来的关键字
- 校队符号:校队符号是由多个字符组成的序列,但是必须被当成一个单位。并且使用 [.与.] 括起所需字符
- 等价类:等价类列出所有应该被当成相等的字符集合,用 [= 与 =] 括起来
这三类都必须出现在方括号表达式中,例如 [[:alpha:]!] 匹配出任何一个字母字符或者感叹号。
用在替换字符串中的元字符
在进行全局替换时,前面提到的具有特殊含义的元字符只能用在命令的搜索部分。而在替换字符串中,这些元字符就失去了特殊意义。即使如此,替换字符串中仍然可以使用一些具有特殊含义的元字符。
- \number:引用搜索模式中利用( 与 )存储的第 number 个模式
- \:转义字符,使某个特殊字符变为普通字符,从而失去特殊含义
- &:当用在替换字符中,& 会被替换为搜索模式匹配出的完整文本,从而避免重复输入文本
- ~:可以用来代表上一个替换命令中的替换文本。这在重复编辑时很有用
- \u 或 \l:使替换字符串中的下一个字符变成大写或小写
- \U 或 \L 或 \e 或 \E:\U 或 \L 会使后面的所有字符都被转化成大写或小写的,直到出现 \e 或 \E 为止
更多替换技巧
- 😒:命令等同于 😒//~/,即会重复上一次替换
- :&:也能完成重复上一个替换
- 除了使用 / 字符作为替换命令中的分隔符,还可以使用任何非字母、非数值、非空格的字符,但是反斜线、双引号、和竖线除外。 这在替换命令中包含路径字符串时非常有用
模式匹配的范例
接下来将通过一系列模式匹配的范例,进一步熟悉替换命令和正则表达式。
匹配一个完整的单词
- 目标
如下所示,将文本里所有的 child 单词替换成为 children:
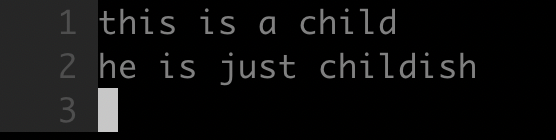
- 命令
1 | :%s/\<child\>/childrendish/g |
使用< > 进行完整单词的匹配,这样 childrendish 中的 child 就不会被替换了。
搜索一般的单词类:
- 目标
如下所示,将 mgibox, mgrbox, mgabox 中的所有 box 替换成为 square:
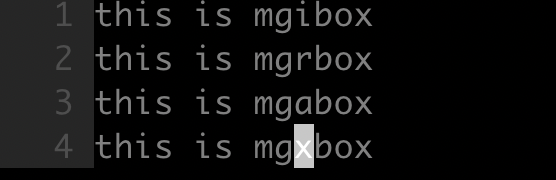
- 命令
1 | :g/mg[ira]box/s/box/square/g |
这里搜索模式和替换模式不同,先找到目标行,在进行相应的替换。
对文件路径做替换
- 目标
如下图所示,将 /home/test/ 替换成为 /usr/local/:
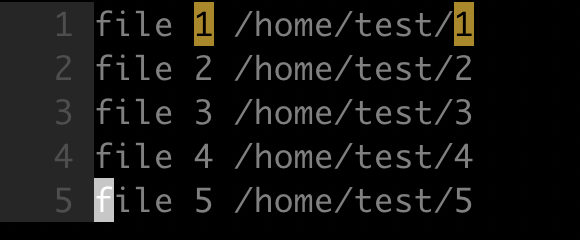
- 命令
1 | :%s;/home/test;/usr/local |
因为一般文件路径中,包含大量 / 字符,而 / 字符在替换命令中又有特殊含义(作为替换命令中各个部分的分隔符),所以此时可以考虑使用其他字符作为分隔符,这里使用字符 ;。
将指令行范围的句号改为分号
- 目标
如下所示,将第一至第五行的句号修改为分号:
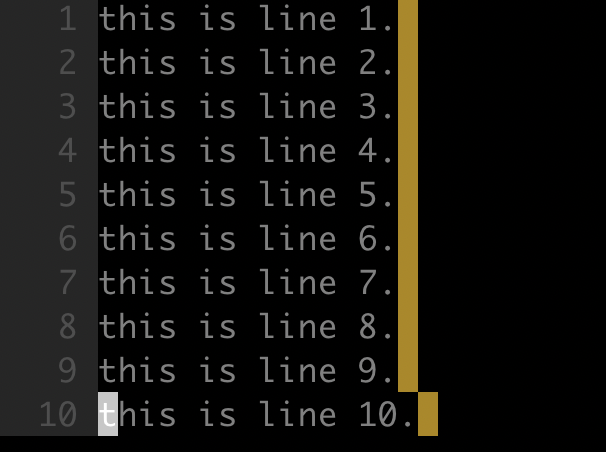
- 命令
1 | :1,5s/\./;/ |
因为 . 在替换字符串中具有特殊含义,所以需要使用转义字符将其转变为普通字符。
删除所有空白行
- 目标
如下所示,删除所有的空白行(不包含任何内容的行)。包含空格或 tab 键的行不能算是空白行。
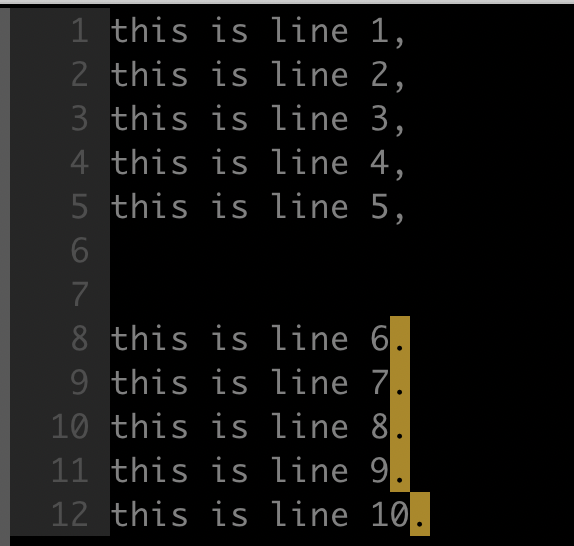
- 命令
1 | :g/^$/d |
^$ 能够匹配出所有空白行,即没有任何内容的行,再配合全局搜索模式 g 和 ex 删除命令 d 即可删除所有空白行。
在每一行的开头添加指定字符串
- 目标
如下所示,在每一行的开头,添加指定字符串 “begin: “:
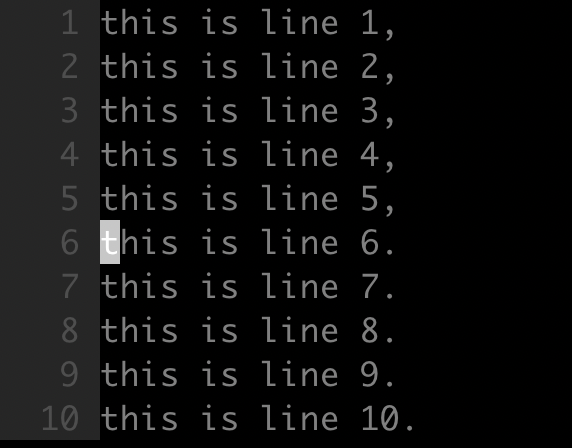
- 命令
1 | :%s/^/begin: / |
^ 代表每一行的开头,将其替换成字符串 begin:,即达到了在行首添加字符串的目的。
逆转连字符分隔部分的顺序
- 目标
如下所示,将连字符分割的两部分进行顺序逆转:

- 命令
1 | :%s/\(.*\)-\(.*\)/\2-\1/ |
在搜索字符串中使用 () 保存模式匹配的内容,在替换字符串中通过 \2 \1 引用之前匹配的内容,从而达到交换的目的。
将文件中的每一个单词全变成大写
- 目标
如下所示,将文件中的每个单词都替换成大写形式:
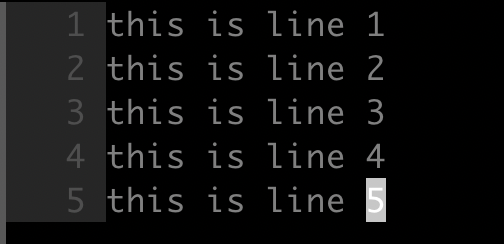
- 命令
1 | :%s/.*/\U&/ |
在替换字符串中,使用 & 引用搜索模式所匹配出的字符串,然后使用 \U 将其转化成大写形式。
逆转文件中的各行顺序
- 目标
如下所示,将文件中的各行顺序进行逆转:
- 命令
1 | :g/.*/mo 0 |
.* 会匹配出完整的一行,然后通过 ex 命令 mo 依次将每一行移动到文件开头,从而完成文件中各行顺序的逆转。
操作不包含指定单词的行
- 目标
如下所示,对所有不包含单词 line 的行,在其行末尾添加单词 end:
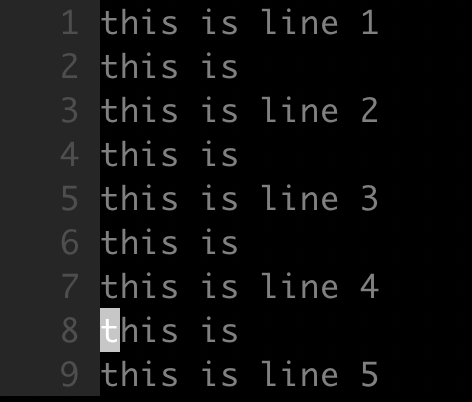
- 命令
1 | :g!/line/s/$/ end/ |
使用 g! 来搜索不包含指定模式的行,然后通过 s 替换命令在行末尾添加单词 end,$ 代表行末尾。
使用模式移动文本块
- 目标
如下所示,将 chapter one 文本块的内容移动到文件末尾:
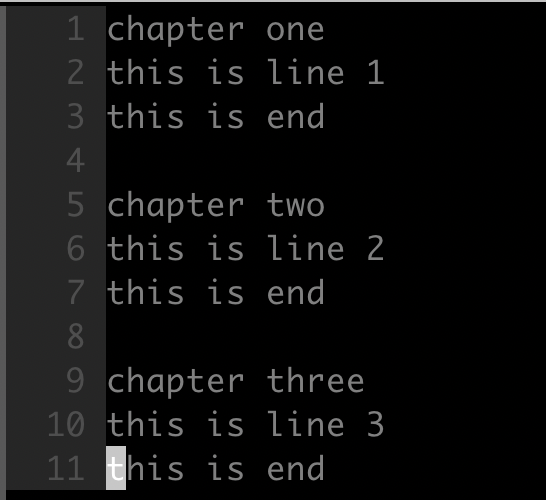
- 命令
1 | :g/chapter one/, /chapter two/-1 mo $ |
这个命令比较复杂,使用了上一篇文章介绍的 ex 命令 mo 进行文本移动,同时使用搜索模式来选择文本范围。通过 /chapter one/ 以及 /chapter two/-1 选择出了 chapter one 的文本块内容。
用 :g 重复命令
这里再额外介绍一个小技巧:使用 :g 来重复命令。通常我们通过 :g 来查找匹配某些模式的行,然后对这些行进行操作。但是有时编辑命令也可以不影响这些匹配行。这里举个简单的例子:
- 目标
如下所示,将文件的第一个行复制 10 次,并添加到文件末尾。
- 命令
1 | :1,10g/$/1 co $ |
该命令在文件的第一至第十行执行全局搜索,由于搜索模式为 $,所以每一行都匹配,匹配之后执行相应的 ex 命令,即将第一行复制到文件末尾。由于共执行了 10 次命令,所以第一行被复制 10 次。这就是通过 :g 来达到重复命令。
最后的叮咛
关于模式匹配,以下还有一些原则性的注意事项:
- 匹配任意数量的任意字符串时,正则表达式总是尽可能多地匹配文本,这被称为 贪婪匹配
- 当我们重新思考一个匹配模式时,通常比较好的方法是更精准地修改变量(元字符),而不是用特定的文字来限制模式。在模式中运用变量越多,命令的力量就越强大
- 有时精确地指定理想结果比指定不要的结果困难的多
正则表达式具有很强的技巧性,只有不断思考和不断尝试,才能扎实的掌握正则表达式,从而在文本编辑时找到更快速的方法。