Python 入门相对简单,但要写好 Python 代码绝对不易。几年前阅读过《流畅的 Python》第一版,让我对 Python 语言的各个细节有了较为深入的理解,收获颇丰。最近因为投入 AI 相关工作,重新阅读大量 Python 开源代码,发现很多新特性比较陌生,虽然借助 LLM 可以快速了解这些新知识的内容,但总还是碎片化的。正好发现《流畅的 Python》也有了第二版,内容做了全面升级,可以帮助我学习这些 modern python 特性(modern 一词不独属于 C++ 了,眨眼~~)。
第二版在第一版的基础上,将 Python 更新到了 Python3.10(本书第一版基于 Python3.4)。Python3.10 官方教程的开头是这样写的:Python是一门既容易上手又强大的编程语言。这句话本身并无大碍,但需要注意的是,正因为它既好学又好用,所以很多 Python 程序员只用到了其强大功能的一小部分。
Python 的质量保障得益于一致性。使用 Python 一段时间之后,便可以根据自己掌握的知识,正确地猜出新功能的作用。可以把 Python 视为一个框架,而数据模型就是对框架的描述,规范语言自身各个组成部分的接口,确立序列、函数、迭代器、协程、类、上下文管理器等部分的行为。如果想让对象支持以下基本的语言结构并与其交互,就需要实现 特殊方法:
- 容器
- 属性存取
- 迭代(包括使用
async for的异步迭代) - 运算符重载
- 函数和方法调用
- 字符串表示形式和格式化
- 使用 await 的异步编程
- 对象创建和析构
- 使用
with或async with语句管理上下文
一摞 Python 风格的纸牌
如下代码展示了实现 __getitem__ 和 __len__ 两个特殊方法之后得到的强大功能:
1 | import collections |
- 首先用
collections.namedtuple构建了一个简单的类,表示单张纸牌。使用namedtuple可以构建只有属性而没有自定义方法的类对象 - 与标准的 Python 容器一样,可以通过调用 len() 函数,获取纸牌个数
- 得益于 FrenchDeck 类实现了
__getitem_方法,因此该类型支持索引、切盼、迭代、in 运算、等功能 - 如果想随机选一张牌,可以直接使用 Python 已经提供的从序列中随机获取一项的函数,即
random.choice。
1 | deck = FrenchDeck() |
可以看到,通过特殊方法利用 Python 数据模型,这样做有两个优点。
- 类的用户不需要记住标准操作的方法名称(例如 .size()、.length() 还是其他)
- 可以充分利用 Python 标准库,例如
random.choice函数,无须重新发明轮子
甚至还可以实现排序:
1 | suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0) |
虽然 FrenchDeck 类隐式继承 object 类,但是前者的多数功能不是继承而来的,而是源自数据模型和组合模式。
- 实现
__len__和__getitem__两个特殊方法后,FrenchDeck 的行为就像标准的 Python 序列一样,从语言核心特性(例如迭代和切片)和标准库中受益 - 而
__len__和__getitem__的实现利用组合模式,把所有工作委托给一个 list 对象,即self._cards。
特殊方法是如何使用的
首先要明确一点,特殊方法供 Python 解释器调用,而不是你自己。例如不要使用 deck.__len__(),而要使用 len(deck),让 Python 解释器内部去调用你实现的 __len__ 方法。
很多时候,特殊方法是隐式调用的。我们在编写代码时一般不直接调用特殊方法,除非涉及大量元编程。即便如此,大部分时间也是实现特殊方法,很少显式调用。唯一例外的是 __init__ 方法,为自定义的类实现 __init__ 方法时经常直接调用它调取超类的初始化方法。
如果需要调用特殊方法,则最好调用相应的内置函数,例如 len、iter、str 等。这些内置函数不仅调用对应的特殊方法,通常还提供额外服务,而且对于内置类型来说,速度比调用方法更快(处理内置类型时,Python 解释器可能有自己的优化方式)。
特殊方法的几个重要用途包括:
- 模拟数值类型
- 对象的字符串表示形式
- 对象的布尔值
- 实现容器
数值模拟
有几个特殊方法可以让用户对象响应 +、* 等数学运算符。如下实现一个二维向量类:
1 | """ |
__add__和__mul__分别实现了+和*运算,这两个方法创建并返回一个新 Vector 实例,没有修改运算对象。这是中缀运算符的预期行为,即创建新对象,不修改运算对象
字符串表示形式
特殊方法 __repr__ 供内置函数 repr 调用,获取对象的字符串表示形式。如未定义 __repr__ 方法,Vector 实例在 Python 控制台中显示为 <Vector object at 0x10e100070> 形式。
交互式控制台和调试器在表达式求值结果上调用 repr 函数,处理方式与使用 % 运算符处理经典格式化方式中的 %r 占位符、str.format 方法处理新字符串格式化句法中的 !r 转换字段一样。
注意,Vector 类 __repr__ 方法实现中的 f 字符串使用 !r 以标准的表示形式显示属性,这样做比较好。因为 __repr__ 方法返回的字符串应当没有歧义,如果可能,最好与源码保持一致,方便重新创建所表示的对象。
与此形成对照的是,__str__ 方法由内置函数 str() 调用,在背后供 print 函数使用,返回对终端用户友好的字符串。有时,__repr__ 方法返回的字符串足够友好,无须再定义 __str__ 方法,因为继承自object 类的实现最终会调用 __repr__ 方法。在 Python 中,如果必须二选一的话,请选择 __repr__ 方法。
自定义类型的布尔值
Python 有一个 bool 类型,在需要布尔值的地方处理对象,例如 if 或 while 语句的条件表达式,或者and、or 和 not 的运算对象。为了确定 x 表示的值为真或为假,Python调用 bool(x),返回 True 或 False。
默认情况下,用户定义类的实例都是真值,除非实现了 __bool__ 或 __len__ 方法。Python 解释器优先尝试调用 __bool__(必须返回一个布尔值),如果没有实现,则继续尝试调用 __len__,如果该方法返回零值,则 bool 函数返回 False,否则返回 True。
Vector.__bool__ 方法也可以像下面这样简单定义:
1 | def __bool__(self): |
容器 API
Python 语言中基本容器类型的接口如下所示:
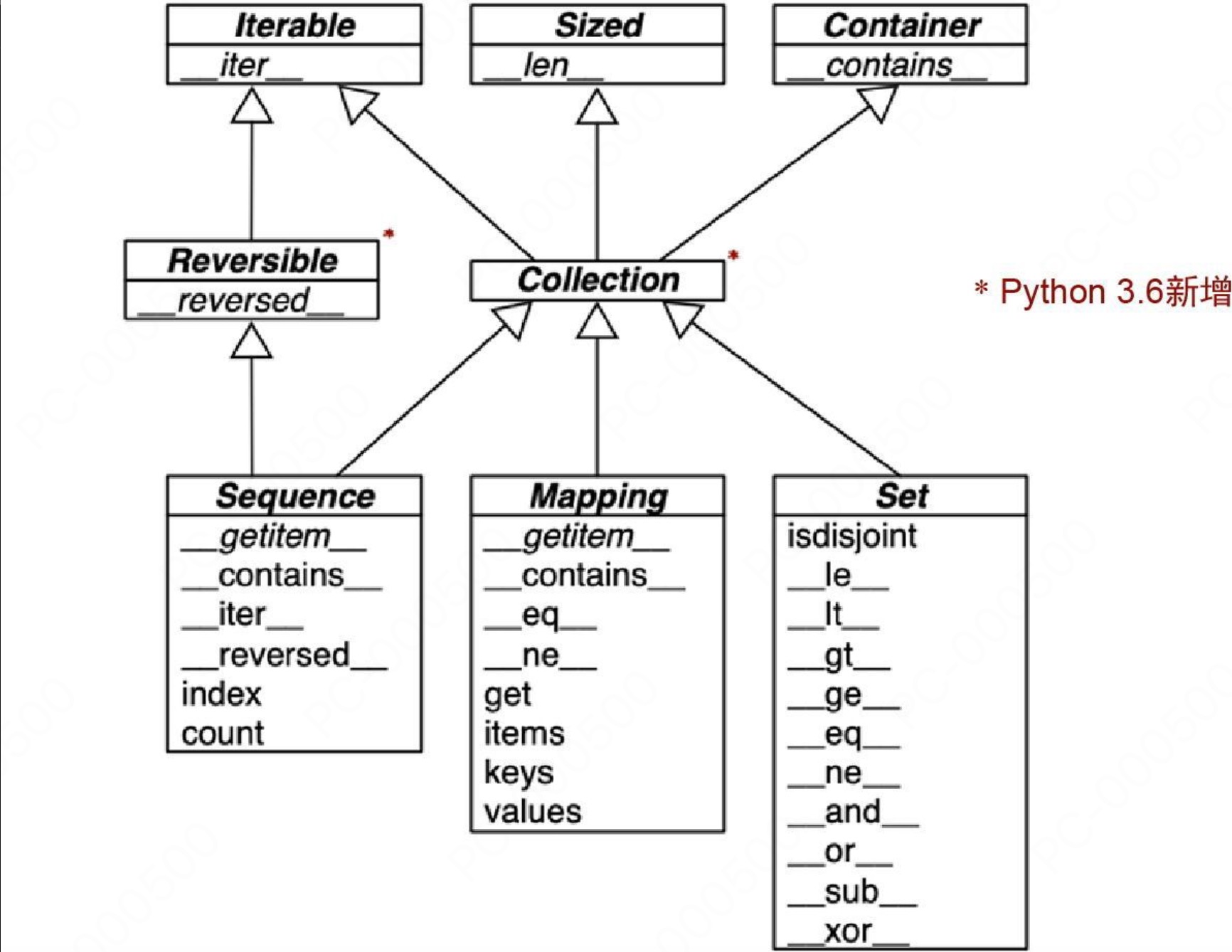
顶部 3 个抽象基类均只有一个特殊方法。抽象基类 Collection 统一了这 3 个基本接口,每一个容器类型均应实现如下事项:
- Iterable 要支持 for、拆包和其他迭代方式
- Sized 要支持内置函数 len
- Container 要支持 in 运算符
Collection 有 3 个十分重要的专用接口:
- Sequence 规范 list 和 str 等内置类型的接口
- Mapping 被 dict、collections.defaultdict 等实现
- Set 是 set 和 frozenset 两个内置类型的接口
只有 Sequence 实现了 Reversible,因为序列要支持以任意顺序排列内容,而 Mapping 和 Set 不需要。
特殊方法概述
Pyton 语言参考手册第 3 章 列出了 80 多个特殊方法名称,其中一半以上用于实现算术运算符、按位运算符和比较运算符。下标列举了这些特殊方法:


小结
借助特殊方法,自定义对象的行为可以像内置类型一样,让我们写出更具表现力的代码,符合社区所认可的 Python 风格。另外值得说明,Python 文档中使用 Python 数据模型 来解释本章所讨论的内容,而一些书籍可能采用的是 Python 对象模型 这一术语。
另外,解释一下 元对象协议。元对象 指构成语言自身的基本对象。在这个语境下,协议 等同于 接口。所以 元对象协议 就是对象模型的高级说法,指语言核心构件的 API。一套丰富的元对象协议能让我们扩展语言,支持新的编程范式。