Python 提供了几种构建简单类的方式,这些类只是字段的容器,几乎没有额外功能。这种模式称为 数据类(data class),dataclasses 包就支持该模式。
数据类构建器概述
如下是一个简单的类,表示地理位置的经纬度:
1 | class Coordinate: |
Coordinate 类的作用是保存经纬度属性。为 __init__ 方法编写样板代码容易让人感到枯燥,尤其是属性较多的时候。而且样板代码并没有给我们提供 Python 对象都有的基本功能:
- 例如继承自 object 的
__repr__作用不大 ==没有意义,因为继承自 object 的 eq 方法比较对象的ID
本章要讲的数据类构建器自动提供必要的 __init__、__repr__ 和 __eq__ 等方法,此外还有其他有用的功能。而且这些类构建器都不依赖继承,它们使用不同的元编程技术把方法和数据属性注入要构建的类。
namedtuple 是一个工厂方法,使用指定的名称和字段构建 tuple 的子类。它创建的子类型提供了有意义的 __repr__ 和 __eq__ 方法。
1 | from collections import namedtuple |
新出现的 typing.NamedTuple 具有一样的功能,不过可为各个字段添加类型注解。
1 | Coordinate = NamedTuple('Coordinate', [('lat', float), ('lon', float)]) |
构建带类型的具名元组,也可以通过关键字参数指定字段:
1 | Coordinate = typing.NamedTuple('Coordinate', lat=float, lon=float) |
typing.NamedTuple 也可以在 class 语句中使用,类型注解按 PEP 526—Syntax for Variable Annotations 标准编写,这样写出的代码可读性更高,而且方便覆盖方法或添加新方法。在 typing.NamedTuple 生成的 __init__ 方法中,字段参数的顺序与在 class 语句中出现的顺序相同:
1 | from typing import NamedTuple |
在 class 语句中,虽然 NamedTuple 出现在超类的位置上,但其实它不是超类。typing.NamedTuple 使用元类这一高级功能创建用户类。
与 typing.NamedTuple 一样,dataclass 装饰器也支持使用 PEP 526 句法来声明实例属性。dataclass装饰器读取变量注解,自动为构建的类生成方法。@dataclass 装饰器不依赖继承或元类,如果你想使用这些机制,则不受影响。
1 | from dataclasses import dataclass |
比较 3 个数据类构建器的部分功能:
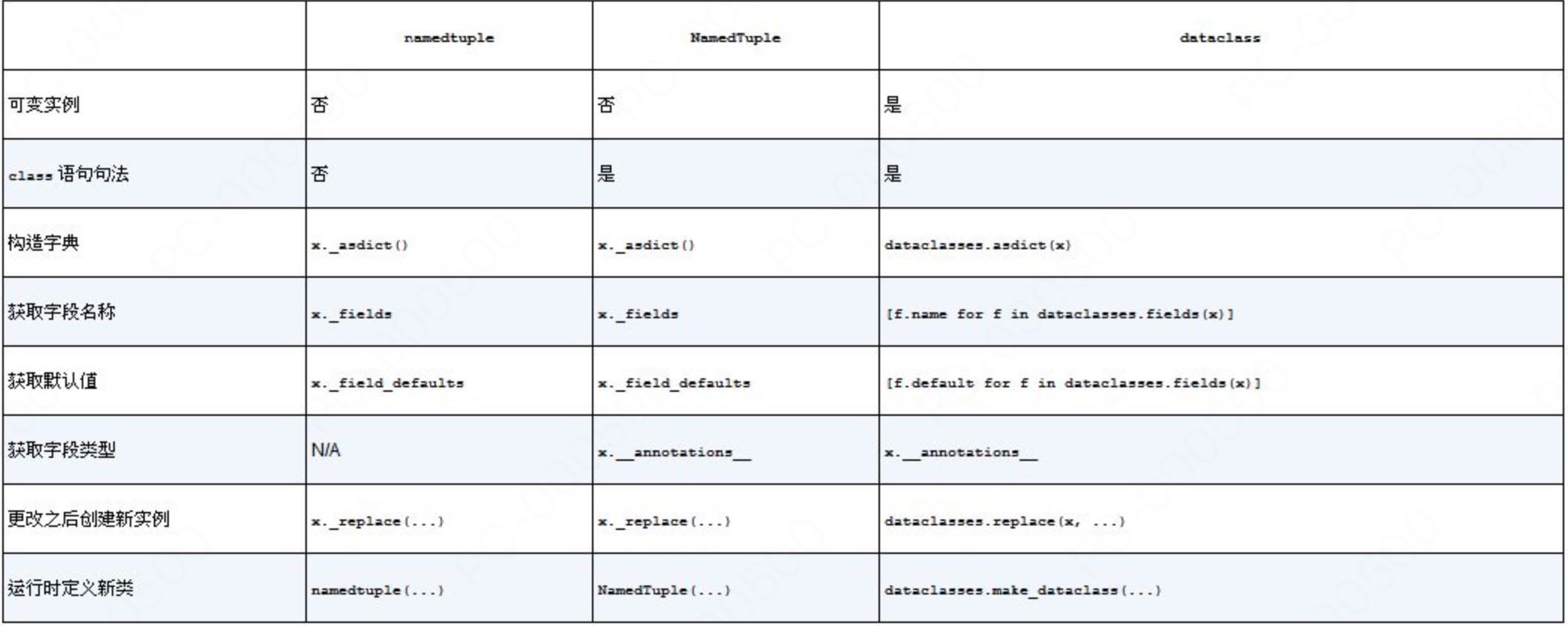
- 3 个数据类构建器之间主要的区别在于,
collections.namedtuple和typing.NamedTuple构建的类是 tuple 的子类,因此实例是不可变的。@dataclass 默认构建可变的类,但@dataclass装饰器接受一个关键字参数 frozen,指定 frozen=True,初始化实例之后,如果为字段赋值,则抛出异常 - 只有
typing.NamedTuple和dataclass支持常规的 class 语句句法,方便为构建的类添加方法和文档字符串 - 两种具名元组都提供了构造 dict 对象的实例方法
._asdict,可根据数据类实例的字段构造字典。dataclasses 模块也提供了构造字典的函数,即dataclasses.asdict - 3 个类构建器都支持获取字段名称和可能配置的默认值
typing.NamedTuple和@dataclass构建的类有一个__annotations__属性,存放字段的类型提示。然而,不建议直接读取__annotations__属性。推荐使用inspect.get_annotations(MyClass)或typing.get_type_hints(MyClass)获取类型信息- 对于具名元组实例 x,
x._replace(**kwargs)根据指定的关键字参数替换某些属性的值,返回一个新实例。模块级函数dataclasses.replace(x, **kwargs)与dataclass装饰的类具有相同的作用。 - class 句法虽然可读性更高,但毕竟还是硬编码的。框架可能需要在运行时动态构建数据类。为此,可以使用默认的函数调用句法,
collections.namedtuple和typing.NamedTuple都支持。 dataclasses 模块提供的make_dataclass函数也是出于这个目的
典型的具名元组
collections.namedtuple 是一个工厂函数,用于构建增强的 tuple 子类,具有字段名称、类名和提供有用信息的 __repr__ 方法。namedtuple 构建的类可在任何需要元组的地方使用(以前标准库中返回元组的很多函数,现在都返回具名元组,这对用户的代码没有任何影响)。而且 namedtuple 构建的类,其实例占用的内存量与元组相同,因为字段名称存储在类中。
- 创建具名元组需要指定两个参数:一个类名和一个字段名称列表。后一个参数可以是产生字符串的可迭代对象,也可以是一整个以空格分隔的字符串
- 字段的值必须以单个位置参数传给构造函数
- 可以通过名称或位置访问字段
- 作为 tuple 的子类,创建的命名元组类继承了一些有用的方法,例如
__eq__、__lt__等,以及类型属性_fields(返回一个元组,存储类的字段名称)、_make(iterable)(根据可迭代对象构建类的实例) 和实例方法_as_dict()(返回对应的 dict 对象)。 - namedtuple 接受 defaults 关键字参数,值为一个产生 N 项的可迭代对象,为从右数的 N 个字段指定默认值
1 | from collections import namedtuple |
namedtuple() 返回的类型也能增加自定义方法,只不过过程有些曲折:要先定义一个函数,再把这个函数赋值给一个类属性:
1 | point3D(x=1, y=2, z=10) |
定义的方法函数第一个参数不必命名为 self,但是调用时指代的就是接收方。这种动态添加方法也展示了动态语言的强大。
带类型的具名元组
通过 typing.NamedTUple 也可以定义命名元组,这种定义方式提供了 class 语法:
1 | from typing import NamedTuple |
- 每个实例字段都要注解类型
- 实例字段 reference 注解了类型,还指定了默认值
使用 typing.NamedTuple 构建的类基本和 collections.namedtuple 生成的类类似,唯一的区别是多了类属性 __annotations__。鉴于 typing.NamedTuple 的主要功能是类型注解,接下来先简单介绍类型注解。
类型提示入门
类型提示(也叫类型注解)声明函数参数、返回值、变量和属性的预期类型。关于类型提示,首先你要知道,Python 字节码编译器和解释器根本不强制你提供类型信息。
运行时没有作用
Python 类型提示可以看作 供IDE和类型检查工具验证类型的文档。类型提示对 Python 程序的运行时行为没有影响。
1 | import typing |
可以看到,运行时根本不考虑类型提示,也不检查类型。类型提示主要为第三方类型检查工具提供支持,例如 Mypy 和 PyCharm IDE 内置的类型检查器。这些是静态分析工具,在 静止 状态下检查 Python 源码,不运行代码。为了看到类型提示的效果,必须使用相关工具(例如linter)检查代码。
使用 mypy 检查之前的示例,看到的输出如下所示:
1 | # mypy point.py |
变量注解句法
typing.NamedTuple 和 @dataclass 使用 PEP 526 定义的句法注解变量。这里先介绍在 class 语句中定义属性的注解句法。变量注解的基本句法如下所示:
1 | var_name: some_type |
允许使用的类型在 PEP 484 中的 Acceptable type hints 一节规定,不过定义数据类时,最常使用以下类型:
- 一个具体类,例如
str或FrenchDeck - 一个参数化容器类型,例如
list[int]、tuple[str, float]等 - typing.Optional,例如
Optional[str],声明一个字段的类型可以是str或None
另外,还可以为变量指定初始值。在 typing.NamedTuple 和 @dataclass 声明中,指定的初始值作为属性的默认值,防止调用构造函数时没有提供对应的参数。
1 | var_name: some_type = a_value |
变量注解的意义
类型提示在运行时没有作用。然而,Python 在导入时(加载模块时)会读取类型提示,构建 __annotations__ 字典,供 typing.NamedTuple 和 @dataclass 使用,增强类的功能。接下来先定义一个简单的类,然后再讨论 typing.NamedTuple 和 @dataclass 增加的额外功能。
1 | class DemoPlainClass: |
- a 出现在
__annotations__中,但被抛弃了,因为该类没有名为 a 的属性 - b 作为注解记录在案,而且是一个类属性,值为 1.1
- c 是普通的类属性,没有注解
1 | from demo import DemoPlainClass |
- 特殊属性
__annotations__由解释器创建,记录源码中出现的类型提示,即使是普通的类 - a 只作为注解存在,不是类属性,因为没有绑定值。b 和 c 存储为类属性,因为它们绑定了值
- 这 3 个属性都不出现在 DemoPlainClass 的实例中。使用
o = DemoPlainClass()创建一个对象,o.a抛出AttributeError,而o.b和o.c检索类属性,值分别为1.1和spam,行为与常规的 Python 对象相同
接下来研究一个使用 typing.NamedTuple 构建的类,如下所示:
1 | import typing |
- a 是注解,也是实例属性
- b 是注解,也是实例属性
- c 是普通的类属性,没有注解
1 | DemoNTClass.__annotations__ |
typing.NamedTuple创建了类属性 a 和 b。c 是普通的类属性,值为spam- 类属性 a 和 b 是描述符。可以把描述符理解为特性(property)读值(getter)方法,即不带调用
运算符()的方法,用于读取实例属性 - 这意味着 a 和 b 是只读实例属性。这一点不难理解,因为 DemoNTClass 实例是某种高级的元组,而元组是不可变的
- DemoNTClass 还有定制的文档字符串
1 | t = DemoNTClass(8) |
1 | t.a = 1 |
- 构造 DemoNTClass 实例时,需要提供 a 参数,b 也是构造函数的参数,不过它有默认值
1.1,因此可以不提供。 - 实例有 a 和 b 两个属性,这在预期之中。但是,没有 c 属性,像往常一样,Python 从类中检索该属性
- 为属性赋值时设置抛出抛出 AttributeError 异常,因为对象是元组,是不可变的
如下是使用 dataclass 装饰类的类:
1 | from dataclasses import dataclass |
- a 是注解,也是受描述符控制的实例属性
- 同样,b 是注解,也是受描述符控制的实例属性,默认值为 1.1
- c 是普通的类属性,没有注解
1 | from demo_dataclass import DemoDataClass |
- 这里需要说明的是,a 属性只在DemoDataClass实例中存在。如果冻结 DemoDataClass 类,那么 a 就变成可获取和设定的公开属性
- b 和 c 作为类属性存在,b 存储实例属性 b 的默认值,而 c 本身就是类属性,不绑定到实例上
1 | dc = DemoDataClass(9) |
- a 和 b 是实例属性,而 c 是通过实例获取的类属性
- DemoDataClass 实例是可变的,而且运行时不检查类型
甚至还可以为不存在的属性赋值。dc 实例有 c 属性,这对类属性 c 没有影响。我们还可以新增一个 z 属性。这是 Python 正常的行为:常规实例自身可以有未出现在类定义中的属性
1 | dc.c = 10 |
PEP 526提出的实例属性和类属性注解句法与我们在 class 语句中养成的习惯相反。以前,**class 块顶层声明的全是类属性(方法也是类属性)**。而对于 PEP 526 和 NamedTuple 及 @dataclass,在顶层声明的带有类型提示的属性变成了实例属性。
1 |
|
1 |
|
但是,如果没有类型提示,我们一下子就回到了从前,在类顶层声明的属性只属于类自身。
1 |
|
如果你想为类属性注解类型,则不能使用常规的类型,否则就变成实例属性了。正确的做法是使用伪类型 ClassVar 注解(下文详解)。
1 |
|
这是例外中的例外,语法的可读性的确不高,不太符合 Python 风格。
@dataclass 详解
@dataclass 装饰器可以接受多个关键字参数,完整签名如下:
1 |
|
- 如果 eq 和 frozen 参数的值都是 True,那么
@dataclass将生成一个合适的__hash__方法,确保实例是可哈希的。生成的__hash__方法使用所有字段的数据,通过字段选项也不能排除 - 对于
frozen=False(默认值),@dataclass 把 hash 设为 None,覆盖从任何超类继承的 hash 方法,表明实例不可哈希
生成的数据类还可以在字段层面进一步定制。我们已经见过最基本的字段选项,即在提供类型提示的同时设定默认值,声明的字段将作为参数传给生成的 __init__ 方法。Python 规定,带默认值的参数后面不能有不带默认值的参数。因此,为一个字段声明默认值之后,余下的字段都要有默认值。
可变的默认值很容易导致 bug。如果在函数定义中使用可变默认值,调用函数时很容易破坏默认值,则导致后续调用的行为发生变化。@dataclass 使用类型提示中的默认值生成传给 __init__ 方法的参数默认值。为了避免bug,@dataclass拒绝如下那样定义类:
1 | @dataclass |
使用 default_factory 可以解决这个问题:
1 | from dataclasses import dataclass, field |
通过调用 dataclasses.field 函数,把参数设为 default_factory=list,以此设定默认值。default_factory 参数的值可以是一个函数、一个类,或者其他可调用对象,在每次创建数据类的实例时调用(不带参数),构建默认值。这样每次数据类的实例都将拥有自己的 list,而不是所有实例共用 list。
@dataclass 主动拒绝这种方案只适用于部分情况,只对 list、dict 和 set 有效。除此之外,其他可变的值不会引起 @dataclass 的注意。遇到这样的问题,你要自己处理,为可变的默认值设置默认工厂。
另外,这里的类型注解语法 list[int] 表示由 int 构成的列表。这是一种参数化泛型。从 Python3.9 开始,内置类型 list 可以使用方括号表示法指定列表中项的类型。在 Python3.9 之前,内置容器类型不支持泛型表示法。为了临时解决这一问题,typing 模块提供了对应的容器类型。此时如果需要参数化 list 类型提示,则必须使用从 typing 模块中导入的 List 类型,写作 List[str]。
guests: list表示 guests 列表可以由任何类型的对象构成- 而
guests: list[str]的意思是 guests 列表中的每一项都必须是字符串。如果在列表中存储无效的项,或者读取到无效的项,则类型检查工具将报错
default_factory 应该是 field 函数最常使用的参数,不过除此之外还有其他参数可用。例如 default 参数,之所以有 default 参数,是因为在字段注解中设置默认值的位置被 field 函数调用占据了。
1 |
|
初始化后处理
@dataclass 生成的 __init__ 方法只做一件事:把传入的参数及其默认值(如果没有提供参数)赋值给实例属性,变成实例字段。有些时候初始化实例要做的不只是这些。为此,可以提供一个 __post_init__ 方法。如果存在这个方法,则 @dataclass 将在生成的 __init__ 方法最后调用 __post_init__ 方法。__post_init__ 经常用于执行验证,以及根据其他字段计算一个字段的值。
1 | from dataclasses import dataclass |
1 | ...... |
带类型的类属性
虽然能实现我们的需求,能实现我们的需求,但不能让静态类型检查工具满意。如下是 mypy 的报错:
1 | # mypy all_handler.py |
mypy 认为需要改 all_handlers 提供类型注解,但是如果为 all_handles 添加类型提示,例如 set[...],那么 @dataclass 将把 all_handles 变成实例字段。所以要解决这个问题,同时仍然将 all_handles 保留为类属性,则要使用一个名为 typing.ClassVar 的伪类型,借助泛型表示法 [] 设定变量的类型,同时声明为类属性。这样就可以为类变量添加类型提示。
1 | all_handles: ClassVar[set[str]] = set() |
它表示 all_handles 是一个类属性,类型为字符串构成的集合,默认值是一个空集合。@dataclass 装饰器不关心注解中的类型,但有两种例外情况,这是其中之一,即类型为 ClassVar 时,不为属性生成实例字段。另外一种情况是声明 仅作初始化的变量”。
初始化不作为字段的变量
有时,我们需要把不作为实例字段的参数传给 __init__ 方法。按照 dataclasses 文档的说法,这种参数叫 仅作初始化的变量(init-only variable)。为了声明这种参数,dataclasses 模块提供了伪类型 InitVar,句法与 typing.ClassVar 一样。
1 |
|
这里 database 不会被设为实例属性,也不会出现在 dataclasses.fields 函数返回的列表中。然而,对于生成的 __init__ 方法,database 是参数之一,同时也传给 __post_init__ 方法。所以如果你想自己编写 __post_init__ 方法,需要在在方法签名中增加相应的参数。
一个复杂例子
1 | from dataclasses import dataclass, field |
- Enum 为
Resource.type字段提供类型安全的值 - identifier 是唯一必需的字段
- title 是第一个有默认值的字段。因此,后续字段都要提供默认值
- date的值可以是一个 datetime.date 实例或 None
- type 字段的默认值是
ResourceType.BOOK
数据类导致代码异味
无论是自己编写所有代码实现数据类,还是这里介绍的某个类构建器实现数据类,都要注意一点:这可能表示你的设计存在问题。所谓数据类是指,它们拥有一些字段,以及用于访问(读写)这些字段的函数,除此之外一无长物。这样的类只是一种不会说话的数据容器,它们几乎一定被其他类过分烦琐地操控着。
面向对象编程的主要思想是把行为和数据放在同一个代码单元(一个类)中。如果一个类使用广泛,但是自身没有什么重要的行为,那么整个系统中可能遍布处理实例的代码,并出现在很多方法和函数中。这样的系统对维护来说简直就是噩梦。鉴于此,Martin Fowler 提出的重构方案才建议把职责放回数据类中。
尽管如此,仍然有几种情况适合使用没什么行为或者没有任何行为的数据类。例如刚开始创建一个项目或者编写一个模块时,先用数据类简单实现一个类。随着时间的推移,类应该拥有自己的方法,而不是依赖其他类的方法操作该类的实例
数据类也可用于构建将要导出为 JSON 或其他交换格式的记录,也可用于存储刚刚从其他系统导入的数据。Python 中的数据类构建器都提供了把实例转换为普通字典的方法或函数,而且构造函数全部支持通过关键字参数提供一个字典(非常接近 JSON 记录),再使用 ** 展开。
在这种情况下,应把数据类实例当作不可变对象处理,即便字段是可变的,也不应在处于中间形式时更改。倘若更改,把数据和行为结合在一起的巨大优势就没有了。假如导入或导出时需要更改值,应该自己实现构建器方法,而不是使用数据类构建器提供的 用作字典 方法或常规的构造函数。
总之,不要滥用数据类,以免违背面向对象编程的一个基本原则,即数据和处理数据的函数应放在同一个类中。不含逻辑的类可能表明你把逻辑放错位置了。
模式匹配类实例
类模式通过类型和属性(可选)匹配类实例。类模式的匹配对象可以是任何类的实例,而不仅仅是数据类的实例。类模式有3种变体:简单类模式、关键字类模式和位置类模式。下面按顺序依次研究。
简单类模式
如下就是一个简单的类模式,该模式匹配项数为 4 的序列,第一项必须是 str 实例,最后一项必须是二元组,两项均为 float 实例。
1 | case [str(name), _, _, (float(lat), float(lon))]: |
类模式的句法看起来与构造函数调用差不多。下面的类模式匹配 float 值,未绑定变量(在 case 主体中,如果需要可以直接引用 x)。
1 | match x: |
但是下面这样可能有 bug:
1 | match x: |
case float: 可以匹配任何对象,因为 Python 把 float 看作匹配对象绑定的变量。float(x) 这种简单模式句法只适用于 9 种内置类型:
1 | bytes dict float frozenset int list set str tuple |
对这些类来说,看上去像构造函数的参数的那个变量,例如 float(x) 中的 x,绑定整个匹配的实例。如果是子模式,则绑定匹配对象的一部分,例如前例中序列模式内的 str(name):
1 | case [str(name), _, _, (float(lat), float(lon))]: |
除9种内置类型之外,看上去像参数的那个变量表示模式匹配的类实例的属性。
关键字类模式
1 | import typing |
- City(continent=‘Asia’) 匹配的 City 实例,continent 属性的值等于
Asia,其他属性的值不考虑
如果你想收集 country 属性的值,可以像下面这样写:
1 | def match_asian_countries(): |
City(continent='Asia', country=cc) 也匹配位于亚洲的城市,不过现在把变量 cc 绑定到了实例的 country 属性上。模式变量叫 country 也没关系。
关键字类模式的可读性非常高,适用于任何有公开的实例属性的类,不过有点烦琐。有时候,使用位置类模式更方便,不过匹配对象所属的类要显式支持。
位置类模式
如下函数使用位置类模式获取亚洲城市列表:
1 | def match_asian_cities_pos(): |
City('Asia')匹配的 City 实例,第一个属性的值是 ‘Asia’,其他属性的值不考虑
如果你想收集 country 属性的值,可以像下面这样写:
1 | def match_asian_countries_pos(): |
City 或其他类若想使用位置模式,要有一个名为 __match_args__ 的特殊类属性。本章讲到的类构建器会自动创建这个属性。对于 City 类,__match_args__ 属性的值如下所示:
1 | City.__match_args__ |
位置模式中属性的顺序就是 __match_args__ 声明的顺序。一个模式可以同时使用关键字参数和位置参数。match_args 列出的是可供匹配的实例属性,不是全部属性。因此,有时候除了位置参数之外可能还需要使用关键字参数。
小结
这篇文章主要介绍了 3 个数据类构建器:collections.namedtuple、typing.NamedTuple 和 dataclasses.dataclass。每个构建器都可以根据传给工厂函数的参数生成数据类,后两个构建器还可以通过 class 语句提供类型提示。