本章的主题是对象与对象名称之间的区别。名称不是对象,名称就是名称。在 Python 中,变量是标注,而不是盒子。
变量不是盒子
Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注。如下例子说明了 Python 中变量不是盒子:
1 | a = [1, 2, 3] |
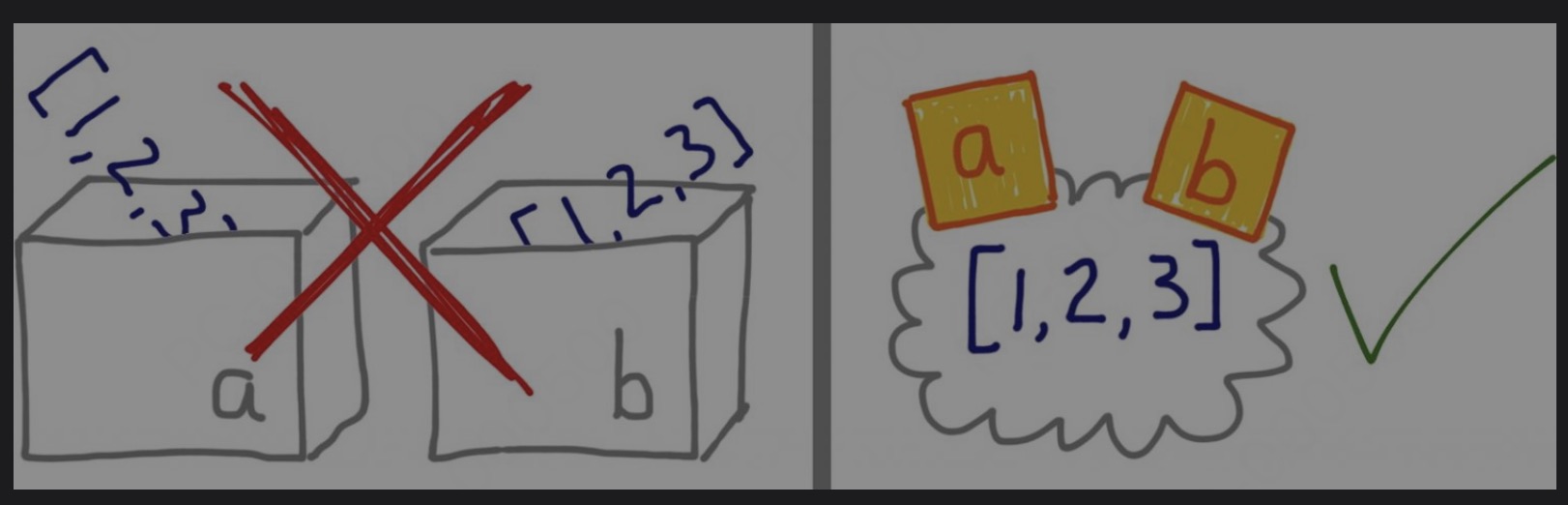
把变量想象为盒子,无法解释 Python 中的赋值。应该把变量视作便利贴,因此,b = a 语句不是把 a 盒子中的内容复制到 b 盒子中,而是在标注为 a 的对象上再贴一个标注 b。
对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了。动词 分配 自相矛盾,经常使用 绑定 代替。在 Python 中,赋值语句 x = ... 把名称 x 绑定到右边创建或引用的对象上。在绑定名称之前,对象必须存在。
为了理解 Python 中的赋值语句,应该始终先读右边。对象先在右边创建或获取,然后左边的变量才会绑定到对象上,就像给对象贴上标签一样。忘掉盒子吧!因为变量只不过是标注,所以即使为对象贴上多个标注也没关系。多出来的标注就是别名。
同一性、相等性和别名
1 | charles = {"name": "charles.Lee", 'age':21} |
- lewis 和 charles 是别名,即两个变量绑定同一个对象
- 而 alex 不是 charles 的别名,因为二者绑定的是不同的对象
- alex 指代的对象与分配给 charles 的对象内容一样。比较两个对象,结果相等,这是因为 dict 类的
__eq__方法就是这样实现的。但它们是不同的对象。在 Python 中,使用a is not b判断两个对象的标识是否不同
对象一旦创建,标识始终不变。可以把标识理解为对象在内存中的地址。is 运算符比较两个对象的标识,id() 函数返回对象标识的整数表示。id 一定是唯一的整数标注,而且在对象的生命周期内绝不会变。
在 == 和 is 之间选择
== 运算符比较两个对象的值(对象存储的数据),而 is 比较对象的标识。编程时,我们关注的通常是值,而不是标识,因此在 Python 代码中 == 出现的频率比 is 高。然而,比较一个变量和一个单例时,应该使用 is。目前,最常使用 is 检查变量绑定的值是不是 None:
1 | x is None |
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找要调用的特殊方法,而是直接比较两个整数 ID。而 a == b 是语法糖,等同于 a.__eq__(b):
- 继承自 object 的
__eq__方法比较两个对象的 ID,结果与 is 一样 - 多数内置类型使用更有意义的方式覆盖了
__eq__方法,把对象的属性值纳入考虑范围。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级较深的结构时
元组与多数 Python 容器(列表、字典、集合等)一样,存储的是对象的引用(相比之下,str、bytes、array.array 等扁平序列存储的不是引用,而是在连续的内存中存储内容本身),如果引用的项是可变的,即便元组本身不可变,项依然可以更改。也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即存储的引用)不可变,与引用的对象无关:
1 | t1 = (1, 2, [3, 4]) |
元组的相对不可变性也解释了,为什么有些元组是不可哈希的。
默认做浅拷贝
复制对象时,相等性和同一性之间的区别有更深层的影响。副本与源对象相等,但是 ID 不同。可是,如果对象中包含其他对象,那么应该复制内部对象吗?可以共享内部对象吗?这些问题没有唯一的答案。
复制列表(或多数内置的可变容器)最简单的方式是使用内置的类型构造函数:
1 | l1 = [1, [2, 3], (4, 5, 6)] |
对列表和其他可变序列来说,还可以使用简洁的 l2 = l1[:] 语句创建副本。然而,构造函数或 [:] 做的是浅拷贝:即复制最外层容器,副本中的项是源容器中项的引用。如果所有项都是不可变的,那么这种行为没有问题,而且还能节省内存。但是,如果有可变的项,可能就会导致意想不到的问题。
1 | l1.append(10) |
- 由于 l2 是 l1 的浅拷贝,因此修改 l1 本身对 l2 没有影响
- 但是由于浅拷贝,
l1[1]和l2[1]绑定的是同一个列表,对于可变对象来说,就地修改列表后,l1[1]和l2[1]都有所体现(因为绑定的是同一个对象) - 对于元组来说,虽然
l1[2]和l2[2]最开始也是绑定同一个元组对象,但是对元组来说,+=运算符创建一个新元组,然后重新绑定给变量l2[2],因此l1[2]和l2[2]不再是同一个元组对象
浅拷贝通常来说没什么问题,但有时我们需要的是深拷贝(即副本不共享内部对象的引用)。copy 模块提供的 copy 和 deepcopy 函数分别对任意对象做浅拷贝和深拷贝。
1 | class Bus: |
1 | b1 = Bus(["A", "B", "C"]) |
函数的参数是引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言采用这一模式,共享传参指函数的形参获得实参引用的副本。也就是说,函数内部的形参是实参的别名。这种模式的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象彻底替换成另一个对象)。
1 | def add(a, b): |
可选参数可以有默认值,这是 Python 函数定义的一个很棒的特性,这样我们的 API 在演进的同时能保证向后兼容。然而,应该避免使用可变的对象作为参数的默认值。默认值在定义函数时求解(通常在加载模块时),因此默认值变成了函数对象的属性。所以,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
1 | def test(l = []): |
可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值。通过检查参数值是否为 None,来创建一个新的空列表,而不是使用代表默认值的空列表对象。
防御可变参数
如果你定义的函数接收可变参数,那就应该谨慎考虑调用方是否期望修改传入的参数。接口设计的最佳实践需要满足 最少惊讶原则。例如如下校车的实现中,就自己维护乘客列表,在内部像这样处理乘客列表,就不会影响初始化校车时传入的参数了。
1 | def __init__(self, passengers=None): |
除非方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。如果不确定,那就创建副本,免得给客户添麻烦。
del 和垃圾回收
对象绝不会自行销毁;然而,对象不可达时,可能会被当作垃圾回收。需要注意,del 不是函数而是语句,写作del x 而不是 del(x)。后一种写法也能起到作用,但这仅仅是因为在 Python 中,x和 (x) 这两个表达式往往是同一个意思。
del 语句删除引用,而不是对象。del 可能导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用时。
1 | a = [1, 2] |
即将销毁实例时,Python 解释器调用 __del__ 方法,给实例最后的机会释放外部资源。自己编写的代码很少需要实现 __del__ 方法,有些 Python程序员会花时间实现,但吃力不讨好,因为 __del__ 方法不那么容易实现。
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即被销毁:CPython 在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存。
如下使用 weakref.finalize 注册一个回调函数,在销毁对象时调用。
1 | import weakref |
- 注意,所设置的调用函数,这个函数一定不能是要销毁的对象的绑定方法,否则会有一个指向对象的引用
- 我们把 s1 引用传给 finalize 函数了,而为了监控对象和调用回调,必须要有引用。但是 finalize 持有的是 s1 的弱引用(weak reference),对象的弱引用不增加对象的引用计数
- 弱引用不阻碍目标对象被当作垃圾而回收。弱引用在缓存应用中用得到,因为我们不希望由于存在对缓存的引用而导致缓存的对象无法被删除
- 这个例子展示了,del 不删除对象,但是执行 del 操作后可能会导致对象不可达,从而使得对象被删除
Python 对不可变类型施加的把戏
对元组 t 来说,t[:] 不创建副本,而是返回同一个对象的引用。此外,tuple(t) 获得的也是同一个元组的引用:
1 | t1 = (1, 2, 3) |
str、bytes 和 frozenset 实例也有这种行为。共享字符串字面量是一种优化措施,称为驻留(interning)。CPython还会在小的整数上使用这个优化措施,防止重复创建 热门数值,例如 0、1、-1等。注意,CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明。
1 | t1 = 1 |
千万不要依赖字符串或整数的驻留行为!比较字符串或整数是否相等时,应该使用 ==,而不是 is。驻留是 Python 解释器内部使用的功能。这些实现技巧是 善意的谎言,能节省内存,提升解释器的速度。别担心,这种行为不会给你添任何麻烦,因为只有不可变类型受到影响。
小结
每个 Python 对象都有标识、类型和值。只有对象的值不时变化。不可变容器不变的是所含对象的标识。如果不可变容器存储的项是可变对象的引用,那么可变项的值发生变化后,不可变容器的值也会随之改变。frozenset 类不受这个问题的影响,因为 frozenset 对象中的元素必须可哈希,而按照定义,可哈希对象的值绝不可变。
变量保存的是引用,因此简单的赋值不创建副本。为现有的变量赋予新值,不修改之前该变量所绑定的对象。这叫重新绑定:现在变量绑定了其他对象。如果变量是之前那个对象的最后一个引用,则对象被当作垃圾回收。
使用可变类型作为函数参数的默认值有危险,因为如果就地修改了参数,默认值也就变了,这会影响后续使用默认值的调用。
在 Python 中,函数得到实参的副本,但是实参始终是引用。因此,如果引用的是可变对象,那么对象的值可能会被修改,但是对象的标识不变。此外,因为函数得到的是实参引用的副本,所以重新绑定对函数外部没有影响。