并发指同时处理多件事,并行指同时做多件事。二者不同,但有联系。一个关于结构,一个关于执行。并发用于制定方案,用来解决可能(但未必)并行的问题。并行是并发的一种特殊情况。所有并行系统都是并发的,但不是所有并发系统都是并行的。
这篇文章将展示 Python 的 3 种并发方式:线程、进程和原生协程。
全景概览
启动线程或进程十分容易,关键是如何跟踪线程或进程。
- 相比于普通函数:调用一个函数,发出调用的代码开始阻塞,直到函数返回。因此,你知道函数什么时候执行完毕,而且能轻松地得到函数的返回值。如果函数可能抛出异常,则把函数调用放在
try/except块中,捕获错误
这些熟悉的概念在你启动线程或进程后都不可用了:你无法轻松地得知操作何时结束,若想获取结果或捕获错误,则需要设置某种通信信道,例如消息队列。此外,启动线程或进程有一定消耗,仅仅为了计算一个结果就退出,肯定得不偿失。
通常,更好的选择是让各个线程或进程进入一个 职程(worker),循环等待要处理的输入,以此分摊启动成本。但也有新的问题,如果不需要 worker 了,如何退出?怎样退出才能做到不中断作业,避免留下未处理完毕的数据和未释放的资源?
协程的启动成本很低。使用 await 关键字启动的协程,返回值容易获取,可以安全取消,捕获异常的位置也明确。但是,协程通常由异步框架启动,因此监控难度与线程或进程相当。
鉴于此,并发编程需要学习新的概念和编程模式。首先,我们要对核心概念确立统一认识。
术语定义
-
并发:处理多个待定任务,一次处理一个或并行处理多个(如果条件允许),直到所有任务最终都成功或失败。对于单核 CPU,如果操作系统的调度程序支持交叉执行待定任务,也能实现并发。并发也叫多任务处理(multitasking)
-
并行:同时执行多个计算任务的能力。需要一个多核 CPU、多个 CPU、一个 GPU 或一个集群中的多台计算机
-
执行单元:并发执行代码的对象的统称,每个对象的状态和调用栈是独立的。Python 原生支持 3 种执行单元:进程、线程和协程
-
进程:计算机程序运行时的一个实例,消耗内存和部分 CPU 时间。每个进程都隔离在自己的私有内存空间中。进程通过管道、套接字或内存映射文件进行通信。进程可以派生子进程,子进程彼此之间以及与父进程之间是隔离的。进程支持抢占式多任务处理机制:操作系统调度程序定期抢占(挂起)运行中的进程,让其他进程运行
-
线程:单个进程中的执行单元。一个进程启动后,只使用一个线程,即主线程。通过调用操作系统 API,进程可以创建更多线程,执行并发操作。一个进程内的线程共享相同的内存空间。因此,线程之间可以轻松地共享数据,但是如果多个线程同时更新同一个对象,则可能导致数据损坏,与进程一样,线程在操作系统调度程序的监督下也可以实现抢占式多任务处理。对于同一份作业,线程消耗的资源比进程少
-
协程:可以挂起自身并在以后恢复的函数。在 Python 中,经典协程由生成器函数构建,原生协程使用
async def定义。Python 协程通常在事件循环(也在同一个线程中)的监督下在单个线程中运行。asyncio、Curio 或 Trio 等异步编程框架为基于协程的非阻塞 I/ O提供了事件循环和支持库。协程支持协作式多任务处理:一个协程必须使用 yield 或 await 关键字显式放弃控制权,另一个协程才可以并发(而非并行)开展工作。这意味着,协程中只要有导致阻塞的代码,事件循环和其他所有协程的执行就都会受到阻塞——这一点与进程和线程的抢占式多任务处理形成鲜明对比。另外,对于同一份作业,协程消耗的资源比线程或进程少 -
队列:一种数据结构,可以放入和取出项,顺序通常是先入先出(FIFO)。独立的执行单元可以通过队列交换应用数据和控制消息。队列的实现因底层并发模型而异:Python 标准库中的 queue 包提供的队列类支持线程,multiprocessing 和 asyncio 包则实现了其他队列类
-
锁:一种供执行单元用来同步操作和避免数据损坏的对象。更新共享数据结构时,当前代码应持有相关的锁,并告诉程序的其他部分等到锁被释放后再访问这个数据结构
-
争用:对有限资源的争夺。当多个执行单元尝试访问共享资源(例如锁或存储器)时,就会发生资源争用。当计算密集型进程或线程必须等待操作系统调度程序为其分配 CPU 时间时,还会发生 CPU 争用
接下来使用这些术语分析 Python 对并发的支持。
进程、线程和声名狼藉的 Python GIL
-
Python 解释器的每个实例是一个进程:
- 使用
multiprocessing或concurrent.futures库可以启动额外的 Python 进程 - Python 的 subprocess 库用于启动运行外部程序(不管使用何种语言编写)的进程
- 使用
-
Python 解释器仅使用一个线程运行用户的程序和内存垃圾回收程序。使用
threading或concurrent.futures库可以启动额外的 Python 线程 -
对对象引用计数和解释器其他内部状态的访问受一个锁的控制,这个锁是
全局解释器锁(Global Interpreter Lock,GIL)。任意时间点上只有一个 Python 线程可以持有 GIL。这意味着,任意时间点上只有一个线程能执行 Python 代码,与 CPU 核数量无关 -
为了防止一个 Python 线程无限期持有 GIL,Python 的字节码解释器默认每 5 毫秒暂停当前 Python 线程,释放 GIL。被暂停的线程可以再次尝试获得 GIL,但是如果有其他线程等待,那么操作系统调度程序可能会从中挑选一个线程开展工作
-
我们编写的 Python 代码无法控制 GIL。但是,耗时的任务可由内置函数或 C 语言(以及其他能在
Python/CAPI 层级接合的语言)扩展释放 GIL -
Python标准库中发起系统调用的函数均可释放 GIL,这包括所有执行磁盘 I/O、网络 I/O 的函数,以及
time.sleep() -
在 Python/C API 层级集成的扩展也可以启动不受 GIL 影响的非 Python 线程。这些不受 GIL 影响的线程无法更改 Python 对象,但是可以读取或写入内存中支持缓冲协议的底层对象,例如 bytearray、array.array 和 NumPy 数组
-
GIL 对使用 Python 线程进行网络编程的影响相对较小,因为
I/O函数释放 GIL,而且与内存读写相比,网络读写的延迟始终很高。各个单独的线程无论如何都要花费大量时间等待,所以线程可以交错执行,对整体吞吐量不会产生重大影响 -
对 GIL 的争用会降低计算密集型 Python 线程的速度。对于这类任务,在单线程中依序执行的代码更简单,速度也更快
-
若想在多核上运行 CPU 密集型Python代码,必须使用多个 Python 进程
threading 模块的文档对此做了很好的概括:由于 CPython 有 GIL,因此同一时间只有一个线程能执行 Python 代码(尽管有些旨在提升性能的库可以克服这个限制):
- 如果你希望应用程序充分地利用多核设备的计算资源,那么建议使用
multiprocessing或concurrent.futures.ProcessPoolExecutor - 然而,如果你想同时运行多个 I/ O密集型任务,那么线程仍是最合适的模型
GIL 是 CPython 实现细节,因为 GIL 不是 Python 语言规定的机制。Jython 和 IronPython 就没有GIL。
这里没有提到协程,因为默认情况下,协程共用同一个 Python 线程,而且受异步框架提供的事件循环监管,所以不受 GIL 影响。在异步程序中也可以使用多个线程,但是最佳实践是在同一个线程中运行事件循环和所有协程,其他线程负责执行特定的任务。
一个演示并发的 Hello World 示例
接下来几个示例的想法很简单:启动一个函数,阻塞3秒,期间在终端展示字符动画,让用户知道程序正在运转,没有停滞。
使用线程实现旋转指针
1 | import itertools |
- done 参数的值是一个
threading.Event实例,一个用于同步线程的简单对象 - 这里展现了用文本实现动画的技巧:使用 ASCII 回车符(‘\r’)把光标移到行头
- 如果其他线程设置了这个事件,则
Event.wait(timeout=None)方法返回 True;经过 timeout 指定的时间后,返回 False slow()由主线程调用。假设有一个 API 调用通过网络发送,速度很慢。调用 sleep 阻塞主线程,但是 GIL 已被释放,因此指针还能继续旋转- 调用
time.sleep()虽然阻塞所在的线程,但是释放 GIL,其他 Python 线程可以继续运行
Python 故意没有提供终止线程的 API,如果想终止线程,则必须向线程发送相应的消息。在 Python 中,协调线程的信号机制,使用 threading.Event 类最简单:
- Event 实例有一个内部布尔标志,开始时为 False。调用
Event.set()可把这个标志设为 True - 这个标志为 False 时,在一个线程中调用
Event.wait(),该线程将被阻塞,直到另一个线程调用Event.set(),致使Event.wait()返回 True - 使用
Event.wait(s)设置一个暂停时间(单位为秒),经过这段时间后,Event.wait(s)调用返回 False,如果另一个线程调用Event.set(),则立即返回 True
如下则是主程序逻辑:
1 | def supervisor() -> int: |
1 | # python thread_spin.py |
threading.Event实例是协调 main 线程和 spinner 线程活动的关键- 创建一个 Thread 实例,target 关键字参数的值是一个函数,args 参数的值是一个元组,即传给 target 函数的位置参数
- 调用
spinner.start()启动线程,之后slow()则会阻塞主线程,但 spinner 线程可以继续运行 slow()调用结束后,把 Event 标志设为 True,终止 spin 函数中的 for 循环,spinner 线程退出
使用进程实现旋转指针
multiprocessing 包支持在单独的 Python 进程而非线程中运行并发任务。创建 multiprocessing.Process 实例后,一个全新的 Python 解释器以子进程的形式在后台启动。由于每个 Python 进程都有自己的 GIL,因此程序可以使用所有可用的 CPU 核——但是,最终还是取决于操作系统的调度程序。
1 | import itertools |
1 | # python process_spin.py |
- multiprocessing API 基本模仿 threading API,不过类型提示和 Mypy 还是揭示了一处区别:
multiprocessing.Event是函数,返回synchronize.Event实例
threading 和 multiprocessing 的 API 基本相同,但是实现方式差别很大,而且为了处理多进程编程增加的复杂度,multiprocessing 的 API 更多。例如,把线程换成进程后,一个难点是如何在被操作系统隔离且无法共享 Python 对象的进程之间通信。为此,跨进程传递的对象需要序列化和反序列化,这样一来开销就增加了。
- 这个例子中,跨进程传递的数据只有 Event 状态。在
multiprocessing模块底层的 C 代码中,Event 状态通过操作系统底层信号量实现 - 从 Python 3.8 开始,标准库提供了
multiprocessing.shared_memory包,但是不支持用户定义类的实例
使用协程实现旋转指针
线程和进程由操作系统调度程序分配 CPU 时间驱动。相比之下,协程由应用级事件循环驱动:事件循环管理待定协程队列,逐个驱动,监视由协程发起的 I/O 操作触发的事件,在各个事件发生时把控制权传回相应的协程。事件循环、库协程以及用户协程都在同一个线程中执行。因此,在协程中花费的任何时间都会减慢事件循环,以及所有其他协程。
1 | import asyncio |
1 | # python async_spin.py |
- 在这个程序中,main 是唯一的常规函数,其他的都是协程
asyncio.run函数启动事件循环,驱动supervisor这个协程,最终也将启动其他协程- 原生协程使用
async def定义 asyncio.create_task调度spin最终执行,现在则立即返回一个asyncio.Task实例- await 关键字调用 slow,阻塞 supervisor,直到 slow 返回。slow 的返回值将赋予 result
Task.cancel方法在spin协程中抛出 CancelledError 异常- 使用
await asyncio.sleep(.1)代替time.sleep(.1),暂停时不阻塞其他协程 - 由于在控制这个协程的 Task 实例上调用 cancel 方法会抛出
asyncio.CancelledError。捕获到这个异常就退出循环 - slow 协程也使用
await asyncio.sleep代替time.sleep
这个例子也展示了运行协程的 3 种主要方式:
asyncio.run(coro()):在常规函数中调用,驱动一个协程对象,通常作为程序中所有异步代码的入口。这个调用保持阻塞,一直到 coro 的主体返回。run()调用的返回值是 coro 主体的返回值。但是需要注意,不能在已经运行的事件循环中继续调用asyncio.run(),例如如下就是错误例子
1 | import asyncio |
-
asyncio.create_task(coro()):在协程中调用,调度另一个协程最终执行(自动被随机调度执行),这个调用不中止当前协程。它返回一个 Task 实例,包装协程对象,提供控制和查询协程状态的方法。 -
await coro():在协程中调用,把控制权转给coro()返回的协程对象,中止当前协程,直到 coro 的主体返回。这个异步等待表达式的值是 coro 主体的返回值
通过 coro() 调用协程立即返回一个协程对象,但是不运行 coro 函数的主体。协程的主体由事件循环驱动。
使用 asyncio 的 Python 代码只有一个执行流,除非显式启动额外的线程或进程。这意味着,任何时间点上都只有一个协程在执行。若想实现并发,则要把控制权由一个协程传给另一个协程。所以如果 slow() 协程里不是调用 asyncio.sleep() 而是调用 time.sleep(),则当前唯一主线程的事件循环会被阻塞,程序什么也干不了,等 sleep 结束后,spinner 任务直接被取消,因此控制流始终没有触及 spin 协程的主体。使用 await asyncio.sleep(DELAY) 则把控制权交还 asyncio 事件循环,驱动其他待定协程。
讲到协程并发,就不得不提 greenlet 包。这个包已经存在很多年,使用广泛,通过轻量级协程(叫作greenlets)支持协作式多任务处理,而不使用 yield 或 await 等特殊句法,因此更易于集成到现有的顺序执行基准代码中。
网络库 gevent 对 Python 标准库中的 socket 模块打了猴子补丁,把部分代码换成了 greenlets,以防止阻塞。在很大程度上,gevent 对周围的代码是透明的,因此顺序执行的应用程序和库(例如数据库驱动)无须大改就能执行并发网络 I/O。使用 gevent 的开源项目很多,包括大量部署的 Gunicorn。
而使用协程时,我们编写的代码默认防止中断,因为必须显式使用 await 关键字,程序的其余部分才能运行。按照定义,协程本身即可 同步,不用通过锁同步多个线程的操作,因为任何时刻都只能运行一个协程。想放弃控制权时,我们使用 await 把控制权交还调度程序。这也是可以安全取消协程的原因:按照定义,协程只能在中止它的 await 表达式处被取消,所以可以通过处理 CancelledError 异常执行清理工作。
GIL 真正的影响
对于上面的线程版例子,把 slow 函数中的 time.sleep(3) 调用换成使用某个库发起的 HTTP 客户端请求之后,旋转指针仍然运转。这是因为一个设计精良的网络库在等待网络响应的过程中会释放 GIL。同样对于协程版本也是类似的,因为一个设计精良的异步网络库在等待响应期间会把控制权交还事件循环,让指针保持旋转。
对于 CPU 密集型代码,情况就不同了。假设把 time.sleep(3) 换成一个计算密集型函数(例如素数判断),此时各个版本会有什么影响呢?
- multiprocessing 版本:旋转指针受一个子进程控制,因此在父进程进行素数检测的过程中,指针持续旋转
- threading 版本:旋转指针由一个子线程控制,因此在主线程做素数检测期间指针持续旋转。这里我们不要高估了 GIL 的影响。对这个示例来说,指针得以保持旋转的原因是 Python 每隔 5 毫秒(默认值)中止运行线程,其他待定线程可以获得 GIL。
- asyncio 版本:指针根本不旋转,因为
slow()一直在执行,占据着事件循环,slow()结束后spiner()任务马上又被取消,使其根本来不及执行。程序看上去冻结大约一段时间,然后显示结果
对于线程版本,这个实验很简单,只涉及两个线程,因此我们才能使用线程处理计算密集型任务。在用到的两个线程中,一个独占 CPU,另一个 1 秒只复苏 10 次(占用 GIL 的时间很短),更新旋转指针。但是,如果有两个或以上线程都想占用大量 CPU 时间,那么程序运行速度要比顺序执行的代码更慢,因此这些线程之间总是在争用 GIL。
对于协程版本,为了保持指针旋转,一种办法是把 is_prime 定义为协程,在 await 表达式中定期调用 asyncio.sleep(0),把控制权交还事件循环:
1 | async def is_prime(n): |
- 这里每 50000 次迭代(因为 range 的步幅是2)休眠一次
然而,需要注意的是,这将拖慢 is_prime,以及事件循环和整个程序的速度(因为中途进行了协程的切换),后二者才是重点。使用 await asyncio.sleep(0) 只是权宜之计,更稳妥的办法是重构异步代码,把 CPU 密集型计算委托给另一个进程。后面也将给出一个使用 asyncio.loop.run_in_executor 的方案。另外,还可以使用任务队列。这也可以看出 asyncio 不善于处理 CPU 密集型函数,因为它们会阻塞事件循环。
自建进程池
接下来将展示如何使用多个进程处理 CPU 密集型任务,以及使用队列分配任务和收集结果的常见模式。如下是一个素数运算的顺序版本:
1 | #!/usr/bin/env python3 |
如下则是对应的多进程版本:
1 | import sys |
multiprocessing.SimpleQueue方法用于构建队列,而类型提示所需的SimpleQueue类在multiprocessing.queues中- 使用
0值作为 worker 结束的信号,如果不是 0,则继续循环 - worker 结束时,发回一个
PrimeResult(0, False, 0.0),让主循环知道这个职程结束了
worker 函数遵循了并发编程中的一个常见模式:通过无限循环获取队列中的项,把各个项交给一个函数处理,执行真正的工作。当队列产生一个哨符时,循环结束。在这个模式中,停止 worker 的哨符通常叫作 毒药丸:
- None 经常用作哨符,但是如果数据流中有 None,那就不合适了
- 为了获取一个唯一值用作哨符,经常会调用
object()。但是,一旦跨进程就不能这么做,因为在进程间通信的 Python 对象必须序列化,经过pickle.dump和pickle.load处理之后,反序列化得到的 object 实例就与原实例不同了 - None 有一个很好的替代品,即内置对象
Ellipsis(我们熟悉的...),因为它经过序列化之后也不失同一性
接下来再来看对应的 main 函数实现:
1 | def main() -> None: |
对于繁重的计算,受 Python 的 GIL 限制,线程版比顺序执行版的表现还要糟糕。而只有多进程才能让 Python 从多核 CPU 中受益。
多核世界中的 Python
考虑到目前讨论的这么多局限,Python 为何还能在多核世界蓬勃发展?如今 CPU 时钟速度和执行优化进入平台期,任何显著的性能提升都只能凭借多核或超线程技术,而且只有并发执行的代码能从中受益。
尽管存在 GIL,但是 Python 在需要并发或并行执行的应用领域依然能够蓬勃发展,这要归功于努力解决 CPython 局限性的库和软件架构。接下来,将探讨在当今这个多核 CPU 与分布式计算的年代,Python 在系统管理、数据科学和服务器端应用程序开发等领域仍然发挥作用。
Python 可以很好地服务于数据科学(包括人工智能)和科学计算。这些领域中的应用程序属于计算密集型,但是Python 用户受益于用 C、C++、Fortran、Cython 等语言编写的众多数值计算库,其中许多能够利用多核设备、GPU 和(或)异构集群中的分布式并行计算。
Python 广泛用于 Web 应用程序开发和为移动应用程序提供支持的后端 API 开发。Web-Scale(通过应用新进程、新架构和新实践所实现的灵活性和扩展性)的关键是一个支持横向伸缩的架构。在这样的架构中,所有系统都是分布式系统,没有任何一门语言能够包揽全部解决方案。分布式系统是当前学术研究的一个领域,《数据密集型应用系统设计》是一本值得推荐的相关书籍。
WSGI(Web Server Gateway Interface,Web服务器网关接口)是 Python 框架或应用程序接收 HTTP 服务器请求并向其发送响应的标准 API。WSGI 应用程序服务器管理一个或多个进程,运行你的应用程序,借此最大限度地利用 CPU。
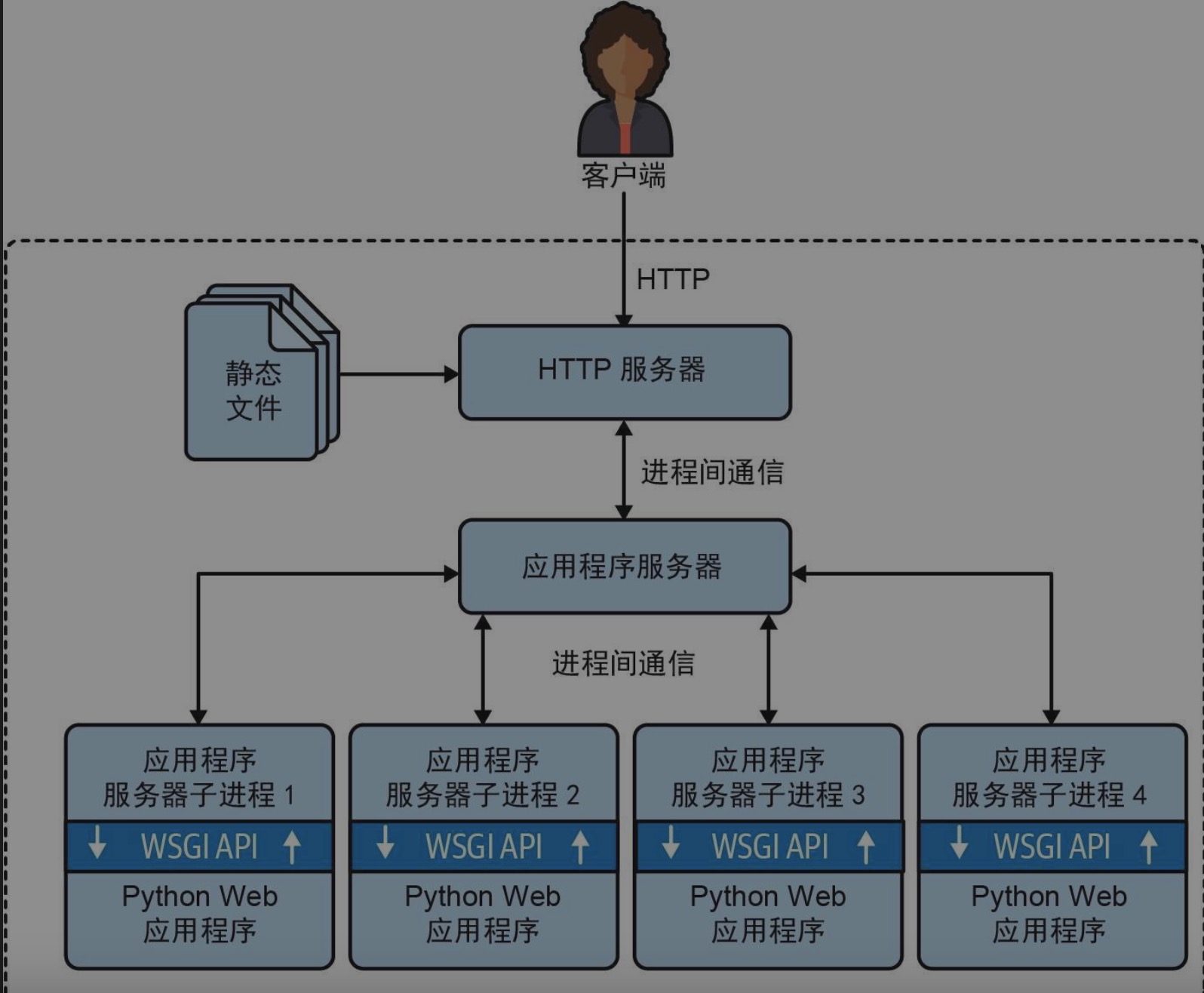
- 客户端连接 HTTP 服务器,后者负责分发静态文件,并把其他请求转发给应用服务器
- 应用程序服务器派生子进程,利用多个 CPU 核运行应用程序代码
- WSGI API 是应用服务器与 Python 应用程序代码之间的黏合剂
mod_wsgi、Gunicorn 等应用程序服务器全都可以派生多个 Python 进程,运行使用 Django、Flask、Pyramid 等框架编写的传统 Web 应用程序,充分利用服务器的所有 CPU 核。这也解释了为什么 Python Web 开发人员无须学习 threading、multiprocessing 或 asyncio 模块就能找到工作:应用程序服务器在无形中已经处理好了并发。
WSGI API 是同步的,不支持使用 async/await 创建协程,而在 Python 中,协程是实现 WebSocket 或 HTTP 长轮询最有效的方式。对此,接任 WSGI 的 ASGI(Asynchronous Server Gateway Interface) 规范应运而生。ASGI 为 aiohttp、Sanic、FastAPI 等 Python 异步 Web 框架而设计,Django 和 Flask 等传统框架也可以借此逐步增加异步功能。
应用程序服务器把请求分发给运行应用程序代码的某个 Python 进程之后,应用需要快速响应,因为你希望进程能尽快完成工作,开始处理下一个请求。然而,有些请求发起的操作要用较长的时间才能处理完毕,这就是分布式任务队列所要解决的问题。在提供 Python API 的开源任务队列中,Celery 和 RQ 最出名。