今天来分析一个开源项目 go-clean-template ,这是 Go 项目模版,用来演示在 Go 中如何实现 整洁架构(Clean Architecture )。它展示了:
如何组织项目,以防止项目演化成难以维护的代码
在哪里处理业务逻辑,使其保持独立、整洁、可扩展
如何在微服务增长时保持控制
当我们在开发一个大型项目时,可能会遇到如下问题:
缺乏项目结构的最佳实践参考
业务逻辑与基础设施代码耦合
微服务架构难以维护和扩展
多种传输协议(REST、gRPC、AMQP RPC、NATS RPC)的统一处理
而 go-clean-template 则展示了一个整洁的架构,尝试解决这些问题:
提供了清晰的项目结构模板,可直接用于生产项目
多种服务器类型的实现示例(REST API、gRPC、AMQP RPC、NATS RPC)
完整的依赖注入实现
可测试的业务逻辑设计
可测试的业务逻辑设计
这个项目包含了 3 个完整的业务领域,包括 用户认证、任务管理、翻译服务,可以认为是 Clean Architecture 在 Go 中的实践案例,也可以作为 Go 语言微服务开发模板。而且它是生产环境就绪的,它包含 Prometheus 指标、Swagger 文档、数据库迁移等生产必需组件。
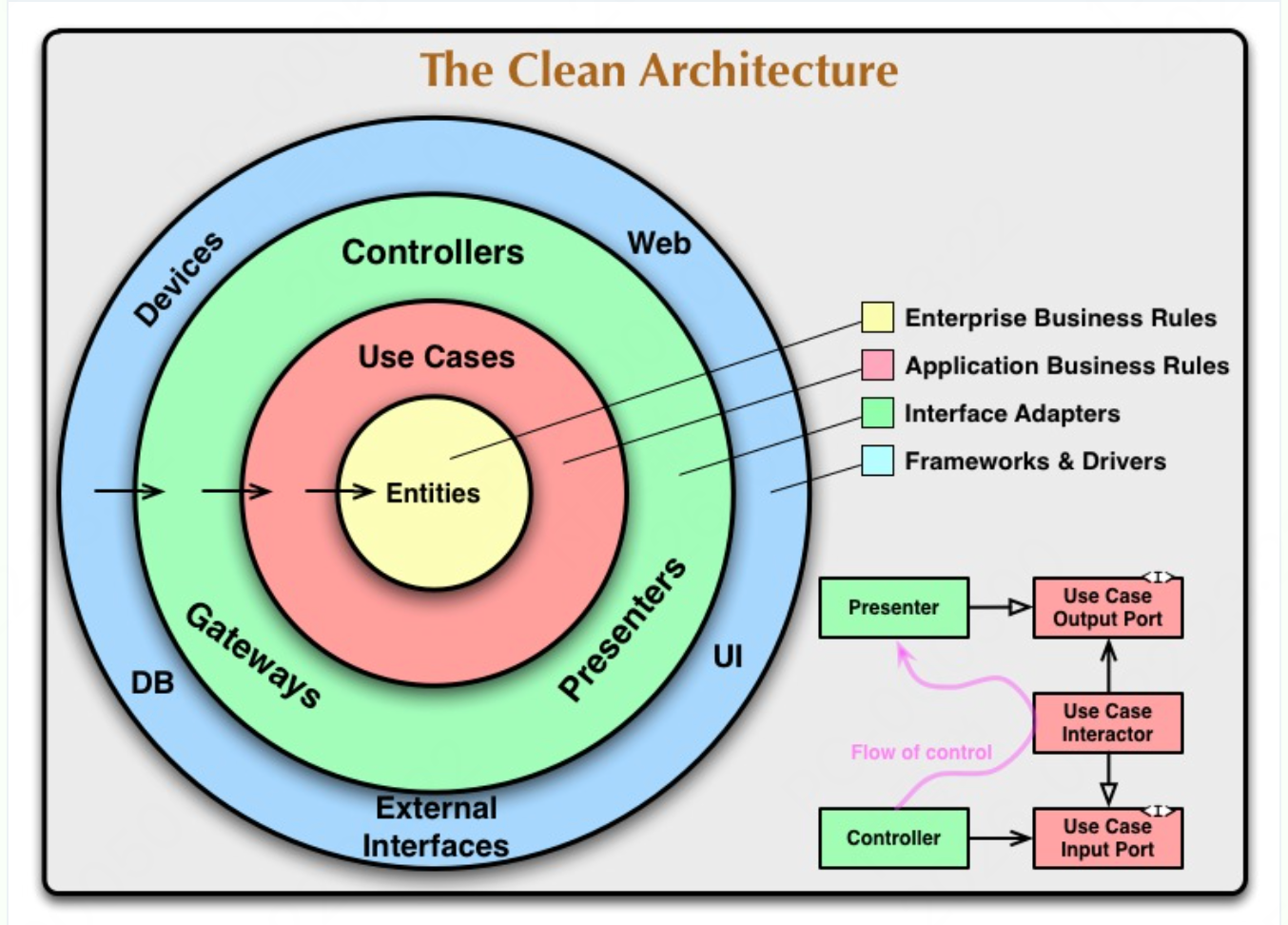
本项目采用 Clean Architecture (整洁架构),遵循 Robert C. Martin(Uncle Bob) 提出的架构原则,其核心思想包括:
依赖反转原则(Dependency Inversion)
业务逻辑独立于框架和基础设施
外层的代码可以依赖内层,但内层永远不能依赖外层
图中同心圆代表软件的不同领域。通常情况下,越往里,软件的层次越高。外圆是机制,内圆是策略 。使这套架构能够工作的核心规则是依赖规则:源代码的依赖关系只能指向内圆 :
在内圆中的任何事物都不能知道外圆中的任何事物。特别是,在外圆中声明的名字(包括函数、类、变量或任何其他软件实体)不能被内圆的代码所提及
在外圆使用的数据格式也不应该被内圆使用,特别是当这些格式是由外圆的框架生成的时候。我们不希望外圆的任何东西影响到内圆
注意,这里的高层/低层指的是软件模块是否承载了业务的核心价值 ,而不是其在代码控制控制流/执行流中的位置。例如对于一个提供 REST API 的应用,Controller 通常会实现 HTTP 参数的解析等逻辑,虽然它在代码执行流中比较靠前执行的,但它属于实现细节/机制(适配 cli、gRPC、REST API 可能有不同的参数传递方式),因此它在同心圆的外层,属于低层模块。
在 Clean Architecture 中,整个系统可以分为四层,通常至少会有这四层:
实体(Entities):实体封装企业级业务规则。一个实体可以是一个带方法的对象,也可以是一组数据结构和函数。只要它能被企业内多个不同应用使用,就可以是实体。如果你没有企业,只是写单个应用,那么实体就是应用的业务对象。它们封装最通用、最高层的规则。当外部变化时,这些对象最不容易被改动
用例(Use Cases):这一层包含应用特有的业务规则。它协调实体的数据流,指挥实体实现系统的用例。这一层的变更不会影响实体。同时,这一层也不会被外部变化(如数据库、UI、框架)影响。
接口适配器(Interface Adapters):这一层是一组适配器,负责把数据从用例/实体方便使用的格式,转换为外部系统方便使用的格式(比如数据库、Web),反之亦然 。这一层是内外格式转换的中间层:数据从数据库取出,转为实体使用的格式;实体的数据转为数据库表格式。Controller、Presenter、Gateway 都属于这一层
框架与驱动(Frameworks and Drivers):最外层,通常由框架和工具组成:Web 框架、数据库驱动、消息队列客户端、UI 组件等。这里只有胶水代码,没有业务逻辑。你在这里写代码把外层工具连接到内层,不写业务规则
假设你正在写一个 保存用户信息 的功能:
高层业务(用例):保存用户。
低层细节(数据库):MySQL
在传统的思维里,你会直接在业务逻辑里调用数据库的代码,这样就形成了 业务逻辑层 依赖 MySQL 驱动。但是如果哪天你想把 MySQL 换成 MongoDB,或者换成一个外部 API,你就不得不去修改最核心的 业务逻辑层。这就是 内层依赖外层 所带来的问题。
而在依赖倒置(Dependency Inversion Principle, DIP)中:高层模块不应该依赖低层模块,二者都应该依赖抽象 。
倒置 指的是控制权的翻转,举例来说:
传统情况:业务逻辑求着数据库:哎呀你快帮我存一下,你叫什么函数我就调什么函数(依赖指向外圆/低层)
倒置情况:业务逻辑制定规矩,谁想给我干活,就得按我的规矩写。数据库反过来要贴合业务的需求(依赖指向内圆/高层)
对于上面的圆形图来说,就是:
内圆(Use Case 层,高层):定义一个接口 UserRepository,里面有个方法叫 save(user)
外圆(DB 层,低层):写一个类叫 SqlUserRepository,它继承并实现了内圆的 UserRepository
运行时:虽然代码执行流是从 业务 流向 数据库 的,但在源代码层面,数据库层的代码却在开头写着 import { UserRepository } from '内圆'
这就是关键,当控制流需要从 内层流向外层 时,必须实现 依赖倒置,从而保证总是 低层依赖高层。这里的倒置指的是运行时的 控制流 和代码编写时的 依赖向 是相反的 。
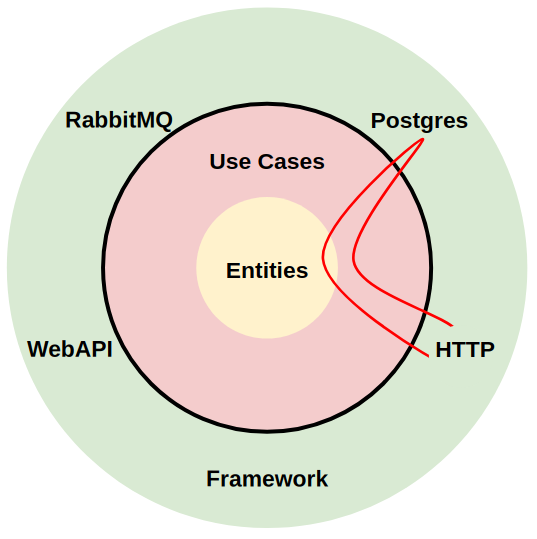
那当外层 Controller 调用内层 Use Case 时,需要怎么处理呢?在 Controller 调用 Use Case 这个环节,依赖关系本身就是 正向 的,并不需要像数据库那样进行 倒置。在干净架构中:
内圆(Use Case 层):是高层策略,它代表了业务的核心逻辑(比如 处理用户下单)
外圆(Controller 层):是低层细节,它只负责处理 HTTP 请求、解析参数、分发指令
我们的依赖规则总是要求:低层(细节)必须依赖高层(策略) 。而这里 Controller(低层)的确是依赖 Use Case(高层),所以,这里不需要通过 倒置 来改变方向,此时依赖方向(从外向内)和业务的控制流方向(从 Controller 到 Use Case)也是一致的。
虽然方向不用倒置,但为了代码的松耦合,我们通常会引入一个 输入端口(Input Port)(即接口)。在代码实现上,它长这样:
Use Case 层(内圆):定义一个接口 CreateOrderInputPort(输入端口),并编写具体的实现类 CreateOrderInteractorController 层(外圆):持有一个 CreateOrderInputPort 接口的引用,而不是直接持有 CreateOrderInteractor 具体的类
引入接口符合 DIP 的另一半定义:细节应该依赖抽象。
Controller(细节):不依赖具体的 实现类,而是依赖 抽象接口
Use Case(实现类):也依赖于 抽象接口(因为它要实现这个接口)
这样,即便你以后想给同一个用例换一个不同的实现方式(Interactor),Controller 的代码也完全不需要动。这一步的本质是 解耦,而不是 反转依赖方向。
以上两个例子就展示了上图右下角的控制流与依赖关系,这也体现了 DIP 的两个层间的定义:
高层模块不应该依赖低层模块,二者都应该依赖抽象
抽象不应该依赖细节,细节应该依赖抽象
场景
控制流方向 (谁调谁)
依赖规则要求 (谁是高层)
矛盾点
解决方案
Controller -> Use Case
外层调内层,内层是高层
没矛盾
方向本来就是往内指的。
使用接口(Input Port)解耦即可
Use Case -> Database
内层调外层,内层是高层
有矛盾
如果直接调用,内层就会依赖外层(违反规则)
必须倒置。内层定义接口,外层去实现
为了保护架构内层的纯净,我们绝不能把外层(比如数据库)的复杂对象直接传进去,而是要转换成内层最舒服的格式。
数据要 笨一点:跨边界传数据时,不要传那些带有复杂业务逻辑或框架依赖的“胖对象”(比如数据库框架自带的 Row 对象),如果你愿意,可以使用基础的结构体(structs)或简单的数据传输对象(DTO)。
依赖不能倒置:内层代码(业务逻辑)不应该知道外层代码(数据库、UI)的存在。如果你把数据库的 Row 对象直接传进业务层,业务层就被数据库框架 污染 了。
内层是老大:数据转换成什么样,不是看外层怎么方便,而是看内层(业务核心)怎么用着最顺手。
当我们跨边界传递数据时,其形式永远应该是最方便内层圈子使用的那种。
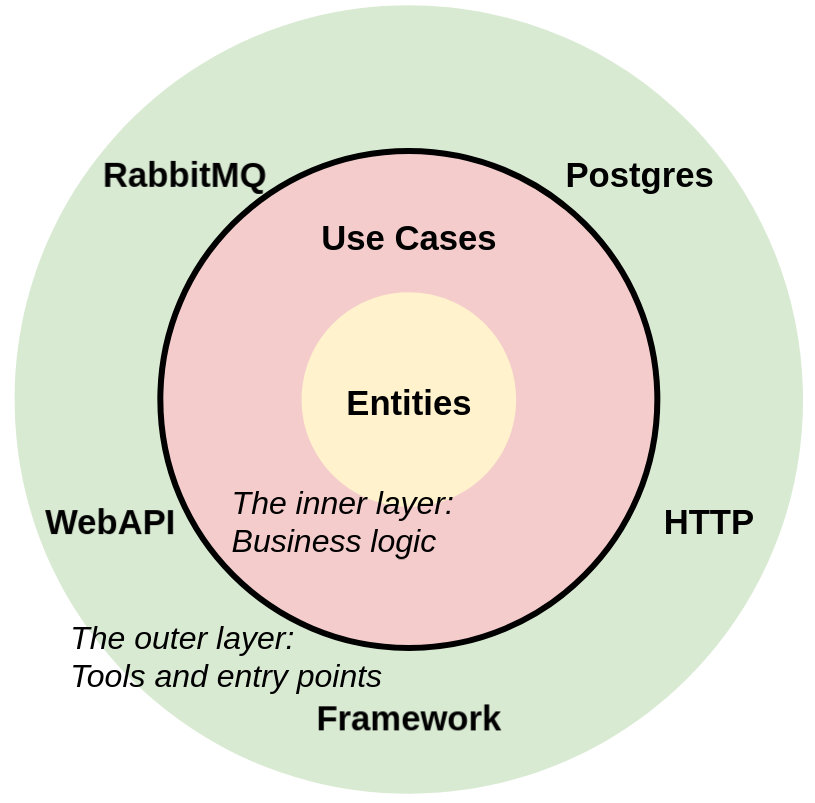
总体上,这个项目采用如下分层结构:
各层之间的交换关系可以使用下图表示:
带有业务逻辑的内层应该是干净的,它应该有如下特征:
没有从外层导入的包
仅使用标准库的功能
通过接口调用外层
业务逻辑对 数据存储 或特定的 Web API 是无感知的,业务逻辑用 抽象接口 来处理数据库或 Web API。
而对于外层,则有其他限制:
该层的所有组件都不知道彼此的存在,如何进行组件间的调用呢? 只能通过业务逻辑的内层间接调用
所有对内层的调用都是通过接口进行的
为了便捷地进行业务数据传输,数据格式需要标准化(internal/entity)
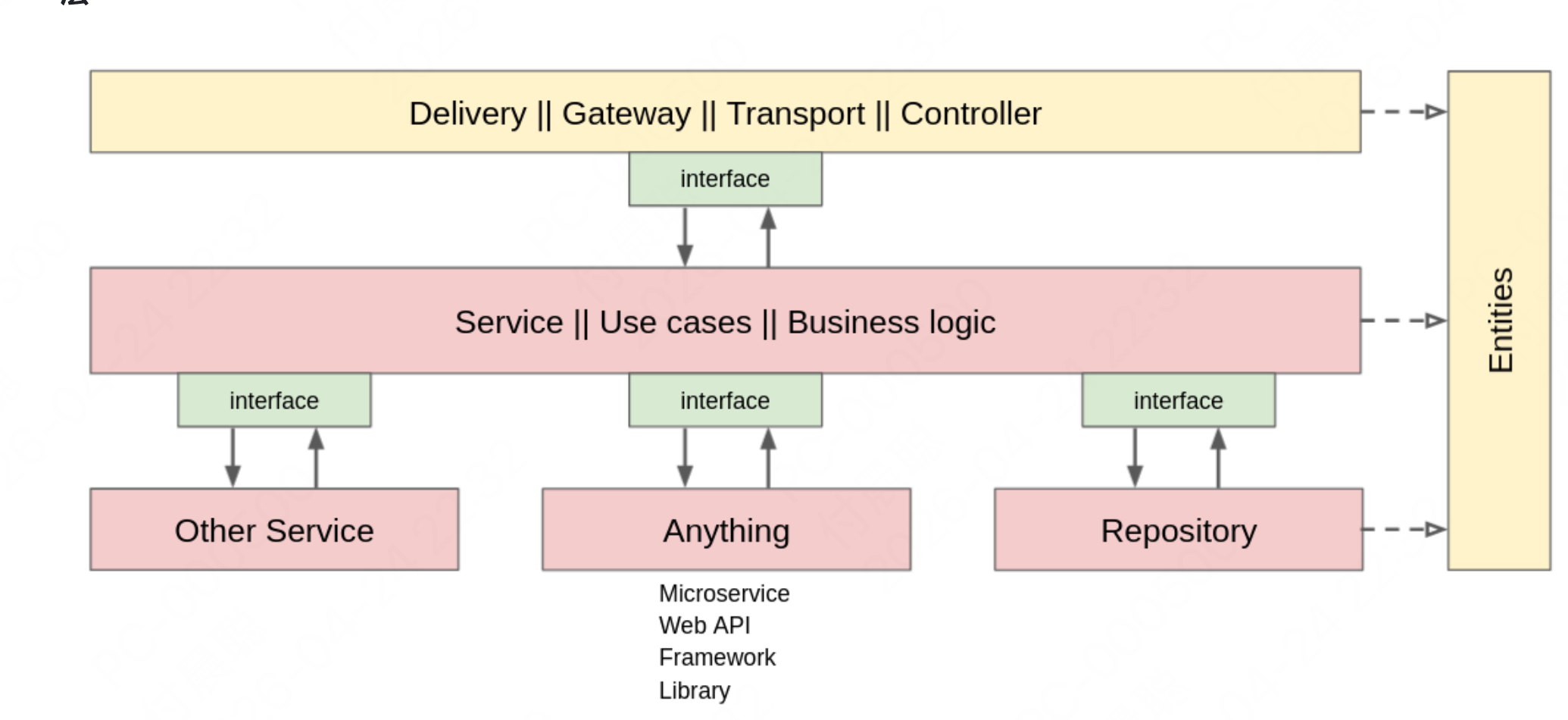
例如,当需要从 HTTP(控制器)访问数据库时,HTTP 和数据库都在外层,这意味着他们彼此无法感知。它们之间的通信是通过 usecase(业务逻辑)进行的:
下面列举了该项目的目录结构,通过这个目录结构的组织,可以清晰地看出项目层次/模块的划分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 go-clean-template/ ├── cmd/app/ ├── config/ ├── docs/ │ ├── proto/v1/ │ └── swagger.json ├── integration-test/ ├── internal/ │ ├── app/ │ ├── controller/ │ │ ├── amqp_rpc/ │ │ ├── grpc/ │ │ ├── nats_rpc/ │ │ └── restapi/ │ ├── entity/ │ ├── repo/ │ │ ├── persistent/ │ │ └── webapi/ │ └── usecase/ │ ├── task/ │ ├── translation/ │ └── user/ ├── migrations/ ├── pkg/ │ ├── grpcserver/ │ ├── httpserver/ │ ├── jwt/ │ ├── logger/ │ ├── nats/ │ ├── postgres/ │ └── rabbitmq/ ├── Makefile ├── docker-compose.yml └── go.mod
Controller:位于 internal/controller,处理外部请求,调用 UseCase,返回响应
Use Cases:业务逻辑,位于 internal/usecase 中,协调 Entity 和 Repository
ENTITY:定义核心业务实体和数据结构。它们位于 internal/entity 文件夹中。在 MVC 术语中,实体是 models
与业务逻辑直接交互的层通常称为 infrastructure 层,这些可以是
存储库(internal/repo/persistent)外部 webapi(internal/repo/webapi)任何包和其他微服务
在模板中,infrastructure 包位于 internal/repo 中(个人感觉不如直接命名为 internal/infra 更合适,因此 repo 一般会被理解为 repository,仅用于表示持久化存储 )
pkg:公共基础设施组件
各目录模块间的依赖、导入关系:
internal 目录 : 只能被本项目导入pkg 目录 : 可以被外部项目导入entity : 无外部依赖usecase : 只依赖 entity 和接口controller : 依赖 usecase 和 pkgrepo : 实现接口,依赖 pkg
cmd/app/main.go:配置和日志能力初始化,主要的功能在 internal/app/app.goconfig:12-Factor推荐将应用的配置存储于 环境变量 中:
环境变量可以非常方便地在不同的部署间做修改,却不动一行代码
与配置文件不同,不小心把它们签入代码库的概率微乎其微
环境变量与语言和系统无关
docs:Swagger 文档。由 swag 库自动生成 你不需要自己修改任何内容
docs/proto:Protobuf 文件,它们用于为 gRPC 服务生成 Go 代码这些 proto 文件也用于生成 gRPC 服务的文档
integration-test:集成测试internal:内部实现,只能被本项目导入
internal/app:
app.go:它是 main 函数的延续,通过依赖注入完成应用的组装migrate.go:完成数据库的自动构建、迁移
internal/controller:服务器处理层(MVC 控制器),模板展示了 4 种服务器
AMQP RPC(基于 RabbitMQ 作为传输)
NATS RPC(基于 NATS 作为传输)
gRPC(基于 protobuf 的 gRPC 框架)
REST API(基于 Fiber 框架)
internal/entity:业务逻辑实体(模型),可用于任何层internal/usecase:业务逻辑,按 应用领域 分组,每个组都有自己的结构internal/repo:与业务逻辑直接交互的 infrastructure 层
internal/repo/persistent:业务逻辑所需要的持久化存储,如数据库internal/repo/webapi:业务逻辑所需要的外部 Web API,例如,它可能是业务逻辑通过 REST API 访问的另一个微服务。实际项目中,根据业务的真正用途进行命名
pkg:公共基础设施组件
因为这本身是一个示例项目,因此并没有很复杂的业务逻辑,我们重点学习其是如何组织代码、划分模块、模块之间是调用的。
整个程序的入口点位于 cmd/app/main.go,它的核心作用就是解析配置,并将解析后的配置作为参数,启动程序:
1 2 3 4 5 6 7 8 9 10 11 func main () cfg, err := config.NewConfig() if err != nil { log.Fatalf("Config error: %s" , err) } app.Run(cfg) }
按照 12-Factor 推荐,配置信息通过环境变量传入。因此该项目使用了 caarlos0/env 库来将环境变量解析到配置结构体中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type ( Config struct { App App HTTP HTTP Log Log PG PG GRPC GRPC RMQ RMQ NATS NATS JWT JWT Metrics Metrics Swagger Swagger } App struct { Name string `env:"APP_NAME,required"` Version string `env:"APP_VERSION,required"` } HTTP struct { Port string `env:"HTTP_PORT,required"` UsePreforkMode bool `env:"HTTP_USE_PREFORK_MODE" envDefault:"false"` } ......
1 2 3 4 5 6 7 8 func NewConfig () error ) { cfg := &Config{} if err := env.Parse(cfg); err != nil { return nil , fmt.Errorf("config error: %w" , err) } return cfg, nil }
internal/app 目录负责 app 启动启动、运行、停止逻辑。核心函数是 Run:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func Run (cfg *config.Config) l := logger.New(cfg.Log.Level) pg, err := postgres.New(cfg.PG.URL, postgres.MaxPoolSize(cfg.PG.PoolMax)) if err != nil { l.Fatal(fmt.Errorf("app - Run - postgres.New: %w" , err)) } defer pg.Close() jwtManager := jwt.New(cfg.JWT.Secret, cfg.JWT.TokenExpiry) uc := initUseCases(pg, jwtManager) s := initServers(cfg, uc, jwtManager, l) s.startServers() s.waitForShutdown(l) }
启动流程可以分为以下几个阶段:
初始化基础设施 :创建 logger 和数据库连接初始化业务组件 :创建 JWT Manager 和所有 useCases初始化服务端 :创建 HTTP、gRPC、RabbitMQ RPC、NATS RPC 四种服务器启动服务 :并行启动所有服务器等待关闭信号 :监听系统信号,优雅关闭所有服务
初始化核心是 initUseCases 和 initServers,它们分别负责初始化业务逻辑和服务器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type useCases struct { translation *translation.UseCase user *user.UseCase task *task.UseCase } func initUseCases (pg *postgres.Postgres, jwtManager *jwt.Manager) userRepo := persistent.NewUserRepo(pg) taskRepo := persistent.NewTaskRepo(pg) translationRepo := persistent.NewTranslationRepo(pg) return useCases{ user: user.New(userRepo, jwtManager), task: task.New(taskRepo), translation: translation.New(translationRepo, webapi.New()), } }
useCases 按照业务领域分组,每个业务领域都有自己的 UseCase在初始化时,这里是手动构造各个 UseCase 的依赖,并将其只作为参数传入 UseCase 的 New 函数。对于大型复杂的生产项目,可以考虑使用 Wire 等依赖注册工具
Server 的初始化也是类似的,servers 结构体是各个服务器的集合,也是手动根据 initServers 所传入的参数,构造各个具体 Server 所需要的依赖,并将其作为参数来构造各个具体的 Server:
1 2 3 4 5 6 type servers struct { rmq *rmqRPCServer.Server nats *natsRPCServer.Server grpc *grpcserver.Server http *httpserver.Server }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func initServers (cfg *config.Config, uc useCases, jwtManager *jwt.Manager, l logger.Interface) rmqRouter := amqprpc.NewRouter(uc.translation, uc.user, uc.task, jwtManager, l) rmqServer, err := rmqRPCServer.New(cfg.RMQ.URL, cfg.RMQ.ServerExchange, rmqRouter, l) natsRouter := natsrpc.NewRouter(uc.translation, uc.user, uc.task, jwtManager, l) natsServer, err := natsRPCServer.New(cfg.NATS.URL, cfg.NATS.ServerExchange, natsRouter, l) grpcServer := grpcserver.New(l, grpcserver.Port(cfg.GRPC.Port), grpcserver.ServerOptions(pbgrpc.UnaryInterceptor(grpcmw.AuthInterceptor(jwtManager))), ) grpc.NewRouter(grpcServer.App, uc.translation, uc.user, uc.task, l) httpServer := httpserver.New(l, httpserver.Port(cfg.HTTP.Port), httpserver.Prefork(cfg.HTTP.UsePreforkMode)) restapi.NewRouter(httpServer.App, cfg, uc.translation, uc.user, uc.task, jwtManager, l) return servers{rmq: rmqServer, nats: natsServer, grpc: grpcServer, http: httpServer} }
Server 初始化时都会依赖到 UseCase,这样才能在 Server 中实现具体的业务逻辑,只不过 Server 并不是直接使用 UseCase,而是通过 Controller 来封装 UseCase 的使用,不同 Server 对应不同的 Controller 。
我们首先分析下 grpc Server 的实现,它的代码位于 pkg/grpcserver 目录下:
1 2 3 pkg/grpcserver/ ├── server.go └── options.go
其中最重要的结构体是 Server:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pbgrpc "google.golang.org/grpc" type Server struct { ctx context.Context eg *errgroup.Group App *pbgrpc.Server notify chan error address string serverOpts []pbgrpc.ServerOption logger logger.Interface }
pkg/grpcserver 本质上是对 gRPC Server 的简单封装:
封装功能
原生 gRPC
pkg/grpcserver
创建 Server
pbgrpc.NewServer(opts...)New(logger, opts...) + Option 模式
启动 Server
server.Serve(listener)Start() + errgroup 并发控制
优雅关闭
server.GracefulStop()Shutdown() + 等待 goroutine 完成
错误通知
手动实现
Notify() <-chan error 自动通知
配置方式
直接传参数
Option 函数式选项模式
支持通过 Option 函数式选项模式,在创建 Server 时传入配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 type Option func (*Server) func Port (port string ) return func (s *Server) s.address = net.JoinHostPort("" , port) } } func ServerOptions (opts ...pbgrpc.ServerOption) return func (s *Server) s.serverOpts = append (s.serverOpts, opts...) } }
httpserver 的实现也是类似的,它是对 fiber.App 的封装。这里我们再分析下 NATS RPC Server 的实现,它的代码位于 pkg/natsrpcserver 目录下。核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import "github.com/nats-io/nats.go" type CallHandler func (*nats.Msg) error ) type Server struct { connection *nats.Conn subscription *nats.Subscription router map [string ]CallHandler } func New (url, serverSubject string , router map [string ]CallHandler, l logger.Interface, ...) error ) { connection, err := nats.Connect( url, nats.ReconnectWait(_defaultWaitTime), nats.MaxReconnects(_defaultAttempts), nats.Timeout(_defaultWaitTime), ) } func (s *Server) s.eg.Go(func () error { err := s.subscribe() <-s.stop }) } func (s *Server) handler := msg.Header.Get("Handler" ) callHandler, ok := s.router[handler] response, err := callHandler(msg) s.publish(msg, body, status) }
RPC Server 的核心逻辑是订阅 NATS 的 subject,然后根据消息的 Header 找到对应的处理函数执行。订阅 subscribe() 的实现如下:
1 2 3 4 5 6 7 8 9 10 func (s *Server) error { subscription, err := s.connection.Subscribe(s.subject, s.handleMessage) if err != nil { return fmt.Errorf("nats_rpc server - subscribe - s.conn.AttemptConnect: %w" , err) } s.subscription = subscription return nil }
因为是基于 NATS 简单封装的 RPC 实现,因此除了提供 Server 的实现,还提供了 Client 实现以简化客户端的使用,代码位于 pkg/nats/nats_rpc/client 目录下。
rabbitmq rpc 的实现类似于 nat rpc,这里就不再赘述了。
所有的 Server 实现都会以某种方式让外部调用者可以注册路由:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 type Server struct { App *pbgrpc.Server } type Server struct { App *fiber.App } type Server struct { router map [string ]CallHandler } type Server struct { router map [string ]CallHandler }
另外值得说明的是,这些 Server 的实现都位于 pkg 目录下,而不是 internal 目录下,因为这些 Server 本身的实现都是通用的,不包含任何业务依赖。它们都是对底层框架的功能增强,可以直接在其他 Go 项目中使用。因此代码保存在 pkg 目录下是合理的 。
Controller 层在 Clean Architecture 中属于接口适配层 (Interface Adapters),其核心职责:
请求解析:将外部请求(HTTP/gRPC/RPC)解析为内部数据结构
参数验证:验证请求参数的格式和有效性
认证授权:提取用户身份信息,进行权限验证
调用 UseCase:将请求转换为 UseCase 调用参数,执行业务逻辑
响应转换:将 UseCase 返回的结果转换为外部响应格式
错误处理:将业务错误转换为协议特定的错误响应
日志记录:记录请求处理过程中的关键信息
由于 Controller 负责外部请求/响应的处理,因此不同的 Server 实现,对应的 Controller 实现也天然是不同的。而且 Controller 层本身也是业务逻辑的处理入口,因此代码保存在 internal 目录下。如下展示了 internal/controller 目录下文件结构,每个 Server 都有对应的 Controller 实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 internal/controller/ ├── restapi/ │ ├── router.go │ ├── middleware/ │ │ ├── auth.go │ │ ├── logger.go │ │ └── recovery.go │ └── v1/ │ ├── controller.go │ ├── router.go │ ├── error.go │ ├── user.go │ ├── task.go │ ├── translation.go │ ├── request/ │ │ ├── user.go │ │ ├── task.go │ │ └── translate.go │ └── response/ │ ├── error.go │ ├── token.go │ └── task.go │ ├── grpc/ │ ├── router.go │ ├── middleware/ │ │ └── auth.go │ └── v1/ │ ├── controller.go │ ├── router.go │ ├── auth_controller.go │ ├── task_controller.go │ ├── user.go │ ├── task.go │ ├── translation.go │ └── response/ │ ├── task.go │ ├── user.go │ └── translation.history.go │ ├── amqp_rpc/ │ ├── router.go │ └── v1/ │ ├── controller.go │ ├── router.go │ ├── auth.go │ ├── user.go │ ├── task.go │ ├── translation.go │ ├── request/ │ │ ├── auth.go │ │ ├── user.go │ │ ├── task.go │ │ └── translate.go │ └── response/ │ ├── token.go │ ├── task.go │ └── error.go │ └── nats_rpc/ ├── router.go └── v1/ ├── controller.go ├── router.go ├── auth.go ├── user.go ├── task.go ├── translation.go ├── request/ │ ├── auth.go │ ├── user.go │ ├── task.go │ └── translate.go └── response/ ├── token.go ├── task.go └── error.go
由于 Controller 的实现与所使用的通信协议、开发框架强相关,因此它的路由注册、请求/响应转换、请求处理的实现都会有所差异。而这也正是 Controller 层的意义所在:它的核心职责是 翻译:将外部世界的协议(HTTP/gRPC/RPC)、框架翻译成统一的业务逻辑处理形式 。
当前项目将路由分发的相关实现也放到 Controller 目录下,这也是合理的,因为路由本身就与协议/框架强相关。而且该项目的路由组织也遵循了一定规则,以 REST API 为例:
入口 (restapi/router.go): 负责初始化 Fiber App,挂载全局中间件,挂载各个版本的路由 group
版本控制 (v1/router.go): 负责具体的路径映射
接下来我们以 createTask 的实现来对比不同的 Controller 实现逻辑:
HTTP Controller 处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (r *V1) error { userID, ok := ctx.Locals("userID" ).(string ) var body request.CreateTask ctx.BodyParser(&body) r.v.Struct(body) task, err := r.tk.Create(ctx.UserContext(), userID, body.Title, body.Description) return ctx.Status(http.StatusCreated).JSON(task) }
gRPC Controller 处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 func (c *TaskController) error ) { userID, ok := grpcmw.UserIDFromContext(ctx) task, err := c.tk.Create(ctx, userID, req.GetTitle(), req.GetDescription()) return response.NewTaskResponse(&task), nil }
RabbitMQ RPC Controller 处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (r *V1) return func (d *amqp.Delivery) error ) { userID, data, err := extractUserID(d, r.j) var req request.CreateTask json.Unmarshal(data, &req) r.v.Struct(req) task, err := r.tk.Create(context.Background(), userID, req.Title, req.Description) return task, nil } }
可以看到,不同的应用层协议(HTTP、gRPC、NATS RPC、RabbitMQ RPC)、不同的开发框架(是否原生支持路由注册、Middleware、请求解析)等等都会对 Controller 层的实现造成很大的影响。
下图简单总结了下 Server、Controller、UseCase 之间的依赖关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ┌─────────────────────────────────────────────────────────────────────────────┐ │ app.go (协调者) │ │ │ │ 1. 创建 UseCases │ │ uc := initUseCases(pg, jwt) │ │ │ │ 2. 创建 Server + 注册 Controller │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ HTTP Server │ │ │ │ httpServer := httpserver.New(...) │ │ │ │ restapi.NewRouter(httpServer.App, uc) ──► Controller 注册路由到 App │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ gRPC Server │ │ │ │ grpcServer := grpcserver.New(...) │ │ │ │ grpc.NewRouter(grpcServer.App, uc) ──► Controller 注册服务到 App │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ RabbitMQ RPC Server │ │ │ │ rmqRouter := amqprpc.NewRouter(uc) ──► Controller 返回路由表 │ │ │ │ rmqServer := rmqRPCServer.New(rmqRouter) ──► Server 持有路由表 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ NATS RPC Server │ │ │ │ natsRouter := natsrpc.NewRouter(uc) ──► Controller 返回路由表 │ │ │ │ natsServer := natsRPCServer.New(natsRouter) ──► Server 持有路由表 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ │ │ │ 3. 启动 Server │ │ s.startServers() │ │ │ │ 4. Server 运行时调用 Controller │ │ ┌─────────────────────────────────────────────────────────────────────┐ │ │ │ 请求到达 ──► Server 接收 ──► 路由匹配 ──► Controller 处理 ──► 返回 │ │ │ └─────────────────────────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────────────────────┘
接下来再来看 usercase 的实现,这块就是业务逻辑的核心了。contracts.go 定义了各个接口契约:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 type ( Translation interface { Translate(ctx context.Context, userID string , t entity.Translation) (entity.Translation, error ) History(ctx context.Context, userID string ) (entity.TranslationHistory, error ) } User interface { Register(ctx context.Context, username, email, password string ) (entity.User, error ) Login(ctx context.Context, email, password string ) (string , error ) GetUser(ctx context.Context, userID string ) (entity.User, error ) } Task interface { Create(ctx context.Context, userID, title, description string ) (entity.Task, error ) Get(ctx context.Context, userID, taskID string ) (entity.Task, error ) List(ctx context.Context, userID string , status *entity.TaskStatus, limit, offset int ) ([]entity.Task, int , error ) Update(ctx context.Context, userID, taskID, title, description string ) (entity.Task, error ) Transition(ctx context.Context, userID, taskID string , newStatus entity.TaskStatus) (entity.Task, error ) Delete(ctx context.Context, userID, taskID string ) error } )
每个业务领域有独立接口
输入参数/返回值都是都是基本类型/或者 Entity 类型,不直接使用 Request 结构体、Response 结构体
通过 go:generate 注释自动生成 Mock
接下来以 Translation UseCase 的实现为例,看下具体的 UseCase 应该如何实现。internal/usecase/translation 下定义了如下结构体:
1 2 3 4 type UseCase struct { repo repo.TranslationRepo webAPI repo.TranslationWebAPI }
它实现了 Translation 接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func (uc *UseCase) string , t entity.Translation) (entity.Translation, error ) { translation, err := uc.webAPI.Translate(ctx, t) if err != nil { return entity.Translation{}, fmt.Errorf("TranslationUseCase - Translate - s.webAPI.Translate: %w" , err) } err = uc.repo.Store(ctx, userID, translation) if err != nil { return entity.Translation{}, fmt.Errorf("TranslationUseCase - Translate - s.repo.Store: %w" , err) } return translation, nil } func (uc *UseCase) string ) (entity.TranslationHistory, error ) { translations, err := uc.repo.GetHistory(ctx, userID) if err != nil { return entity.TranslationHistory{}, fmt.Errorf("TranslationUseCase - History - s.repo.GetHistory: %w" , err) } return entity.TranslationHistory{History: translations}, nil }
这个例子其实展示了典型的后端业务逻辑实现,包括数据库操作、外部 API 调用。其他两个 UseCase 也是类似的:
1 2 3 4 5 6 7 8 9 10 type UseCase struct { repo repo.UserRepo jwt *jwt.Manager } type UseCase struct { repo repo.TaskRepo }
User 的 UseCase 除了需要实现数据库操作,还需要通过 JWT 实现用户认证,JWT 相关实现可以是通用能力,因此保存在 pkg/jwt 目录下
Task 的 UseCase 只需要实现数据库操作,因此只需要 repo.TaskRepo 接口即可
这里的 repo 其实代表的是 infrastructure 层,也就是实现业务逻辑所依赖的外部基础设施。这个例子包含两种:
数据库持久化:在 internal/repo/persistent 中实现
外部 API 调用:在 internal/repo/webapi 中实现
所有的 repo 同样通过接口契约的来对外暴露,internal/repo/contracts.go 定义了各个接口契约:
1 2 3 4 5 6 7 8 9 10 11 12 TranslationRepo interface { Store(ctx context.Context, userID string , t entity.Translation) error GetHistory(ctx context.Context, userID string ) ([]entity.Translation, error ) } TranslationWebAPI interface { Translate(ctx context.Context, t entity.Translation) (entity.Translation, error ) } ......
这个项目并没有直接使用 GORM 等 ORM 框架来实现数据库操作,相反,其使用 Masterminds/squirrel 和 jackc/pgx 来实现持久化存储层的各个接口。如下提供一个实际实现举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (r *TaskRepo) error { sql, args, err := r.Builder. Insert("tasks" ). Columns("id, user_id, title, description, status, created_at, updated_at" ). Values(task.ID, task.UserID, task.Title, task.Description, task.Status, task.CreatedAt, task.UpdatedAt). ToSql() if err != nil { return fmt.Errorf("TaskRepo - Store - r.Builder: %w" , err) } _, err = r.Pool.Exec(ctx, sql, args...) if err != nil { return fmt.Errorf("TaskRepo - Store - r.Pool.Exec: %w" , err) } return nil }
internal/entity 定义了核心业务实体和数据结构,在该项目中,Controller 层、UseCase 层、Repository 层的输入输出参数都可以使用 Entity。Entity 一般就是简单的纯数据结构,也可以包含一些辅助方法。例如 Task 的 Entity 定义如下:
1 2 3 4 5 6 7 8 9 10 type Task struct { ID string `json:"id" example:"550e8400-e29b-41d4-a716-446655440000"` UserID string `json:"user_id" example:"550e8400-e29b-41d4-a716-446655440000"` Title string `json:"title" example:"My task"` Description string `json:"description" example:"Task description"` Status TaskStatus `json:"status" example:"todo"` CreatedAt time.Time `json:"created_at" example:"2026-01-01T00:00:00Z"` UpdatedAt time.Time `json:"updated_at" example:"2026-01-01T00:00:00Z"` }
辅助方法实现的逻辑一定是和 Entity 数据结构本身紧密关联的(内聚性),例如这里 Task 的状态转换是 Task 的固有逻辑,因此提供 Transition() 方法用来修改 Task 的状态
接下来我们通过一些实际例子,看看在这个项目中各层都是怎么使用 Entity 对象的。
Repo 层直接以 Entity 作为参数或者返回值
1 2 func (r *TaskRepo) error func (r *TaskRepo) string ) (entity.Task, error )
UseCase 层直接构造 Entity 对象/或者直接接收 Entity作为参数,以 Entity 作为参数调用 Repo 层,或者将 Entity 作为返回值返回给 Controller 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (uc *UseCase) string ) (entity.Task, error ) { task := entity.Task{ ID: uuid.New().String(), UserID: userID, Title: title, Description: description, Status: entity.TaskStatusTodo, CreatedAt: now, UpdatedAt: now, } err := uc.repo.Store(ctx, &task) return task, nil } func (uc *UseCase) string , t entity.Translation) (entity.Translation, error ) { ...... }
Controller 层:
如果 UseCase 层直接以 Entity 对象作为参数,会将请求转换为 Entity 对象,然后调用 UseCase 层
当调用 UseCase 层得到 Entity 对象,部分 Controller 直接将 Entity 对象作为返回值,部分 Controller 则会额外将 Entity 进行转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func (r *V1) error { ...... translation, err := r.t.Translate( ctx.UserContext(), userID, entity.Translation{ Source: body.Source, Destination: body.Destination, Original: body.Original, }, ) return ctx.Status(http.StatusOK).JSON(translation) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (c *TranslationController) error ) { ...... t, err := c.t.Translate(ctx, userID, entity.Translation{ Source: req.GetSource(), Destination: req.GetDestination(), Original: req.GetOriginal(), }) return &v1.TranslateResponse{ Source: t.Source, Destination: t.Destination, Original: t.Original, Translation: t.Translation, }, nil }
虽然 Entity 对象会在 Controller、UseCase、Repo 层直接使用。但是 Controller 层是否直接返回 Entity 对象并不统一:
接入方式
输入
输出
转换层
REST API
有独立 Request 结构体 (request.CreateTask)
直接返回 Entity 无输出转换
GRPC
使用 Proto 生成的 Request
有 Response 转换函数
response.NewTaskResponse()
NATS/AMQP RPC
有独立 Request 结构体
有独立 Response 结构体
有转换
在 Controller 层直接返回 Entity 对象,好处是代码简洁,无需在各层定义重复的数据结构,减少样板代码。但是也会带来一些问题:
API 契约耦合:内部实现变化会直接影响 API 输出
字段控制受限:无法灵活控制哪些字段对外暴露
版本兼容问题:API 版本演进困难
安全风险:可能意外暴露内部字段
JSON tag 耦合:Entity 中需要定义 JSON tag(参见上面的 Task Entity 定义)来控制输出的序列化
所以大型项目一般会通过 DTO 来缓解这个问题,如下是引入 DTO 之后的调用关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌─────────────────────────────────────────────────────────────────┐ │ Controller Layer │ │ ┌──────────────────┐ ┌──────────────────┐ │ │ │ Request DTO │ │ Response DTO │ │ │ │ (输入验证) │ │ (输出控制) │ │ │ └──────────────────┘ └──────────────────┘ │ │ │ ↑ │ │ │ 转换 │ 转换 │ │ ↓ │ │ ├─────────────────────────────────────────────────────────────────┤ │ UseCase Layer │ │ │ │ │ │ │ │ │ │ ↓ │ │ │ ┌──────────────────────────────────────────┐ │ │ │ Entity (业务模型) │ │ │ │ - 包含业务逻辑方法 │ │ │ │ - 不包含 JSON tag │ │ │ └──────────────────────────────────────────┘ │ │ │ │ │ │ │ │ │ │ ↓ │ │ ├─────────────────────────────────────────────────────────────────┤ │ Repository Layer │ │ ┌──────────────────────────────────────────┐ │ │ │ DAO (Data Access Object) │ │ │ │ - 数据库映射结构 │ │ │ │ - 可与 Entity 相同或不同 │ │ │ └──────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────────┘
如下则给出了使用 DTO 的具体的代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 type Task struct { ID string UserID string Title string Description string Status TaskStatus CreatedAt time.Time UpdatedAt time.Time } func (t *Task) error { ... }type CreateTaskRequest struct { Title string `json:"title" validate:"required,max=255"` Description string `json:"description" validate:"max=1000"` } type TaskResponse struct { ID string `json:"id"` Title string `json:"title"` Description string `json:"description"` Status string `json:"status"` CreatedAt time.Time `json:"created_at"` } func ToTaskResponse (task *entity.Task) return TaskResponse{ ID: task.ID, Title: task.Title, Description: task.Description, Status: string (task.Status), CreatedAt: task.CreatedAt, } } func (r *V1) error { var req CreateTaskRequest ctx.BodyParser(&req) task, err := r.tk.Create(ctx.UserContext(), userID, req.Title, req.Description) return ctx.JSON(ToTaskResponse(&task)) }
这种在 Controller 层引入 DTO(Data Transfer Object)的做法,可以有效地解决直接返回 Entity 对象带来的问题。DTO 可以清晰地定义 API 的输入输出契约,控制字段的暴露和序列化方式,便于维护和版本演进:
Controller 层独立 Request/Response 结构体
Entity 专注业务逻辑,通过转换函数解耦
这一些更复杂的项目中,可能每一层都会引入自己的数据结构:Controller 有其 DTO,Usecase 有其特定的输入/输出对象(有时称为 InputPort/OutputPort),Repo 有专门的对象(或 Entity)。当然这种设计方法也可能引入额外的复杂度,需要根据项目实际情况权衡。
这篇文章学习了 go-clean-template 这个项目,它通过将服务划分为 Controller、UseCase 和 Repo 这几个核心层,并使用 Entity 作为核心业务模型,展示了如何在 Go 项目中实现 Clean Architecture。但是其直接在 REST API 的 Controller 中返回 Entity 对象,而没有使用 DTO 来控制 API 的输出。这虽然减少了样板代码,但也引入了潜在的耦合和安全问题。
关于如何组织 Go 后端服务的项目结构,还是有不同的观点和做法(甚至一些术语也存在含义不一致的情况):